创新点
1、提出了E-ELAN,但是只在yolov7-e6e中使用到。
2、yolov7基于拼接模型的缩放方法,在yolov7x中使用到。
3、将重参数化卷积应用到残差模块中或者用到基于拼接的模块中去。RepConvN
4、提出了两种新的标签分配方法
一、ELAN和E-ELAN
1、 ELAN
yolov7使用大量的ELAN作为基础模块。 这么多堆叠其实对应了更密集的残差结构,残差网络的特点是容易优化,并且能够通过增加相当的深度来提高准确率。内部的残差块使用了跳跃连接,缓解了在深度神经网络中增加深度带来的梯度消失问题。
[-1, 1, Conv, [64, 1, 1]],
[-2, 1, Conv, [64, 1, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]], # 11
2、E-ELAN
2分组的卷积,本质上就是ELAN的拓展 。只在yolov7-e6e中提到,是将yolov7-e6中的ELAN并行处理后得到的。

二、模型缩放
设计了同时改变深度和宽度的模型缩放方法,yolov7x是对yolov7进行了缩放。
增加了两个卷积层,增加了深度,并且输入数量,拼接后输出数量,以及卷积层输出的通道数量都是原来的1.25倍,从这个角度考虑增加了宽度。
三、重参数化卷积的改进 RepConvN
1、RepConv
重参数化卷积,使用3个不同的卷积层训练完成后,进行合并。重参数化卷积虽然在VGG上取得较好的成果,但是在残差网络中并没有取得很好的成果 。
2、RepConvN
而RepConvN是在重参数化卷积的基础上去掉了恒等连接。将重参数化卷积应用到残差模块或者用到基于拼接的模块中去。但是在代码中使用了最简单的重参数化卷积,并没有使用提出的这个结论。
思想取自于RepVGG,基本思想是在训练的时候引入特殊的残差结构辅助训练,这个残差结构是经过独特设计的,在实际预测的时候,可以将复杂的残差结构等效于一个普通的3*3卷积,这个时候网络的复杂度下降,但是网络的预测性能却没有下降。
为什么要去掉恒等连接?
因为残差网络本身存在恒等连接,而原本的重参数化卷积RepConv也有恒等连接,两者之间起了冲突,所以要去掉原本重参数化卷积RepConv中的恒等连接,成为RepConvN。

四、软标签和硬标签

硬标签是yolov5所采用的方式,将目标值和预测值一起计算损失值;软标签是yolov7所使用的方式,将目标值通过分配器得到新的目标值,再和预测值一起计算损失值。
五、两种新的标签分配方法

粗粒度和细粒度。粗标签是5个网格,细标签是3个网格。
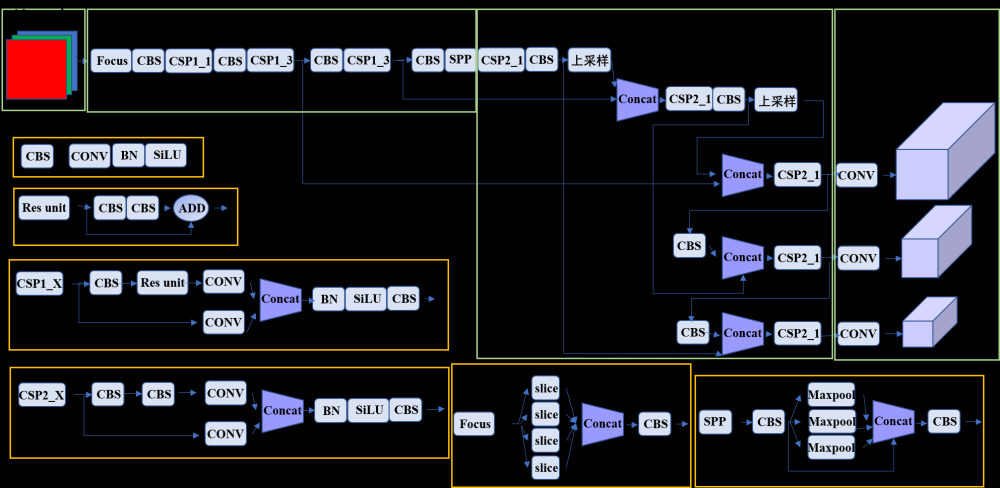
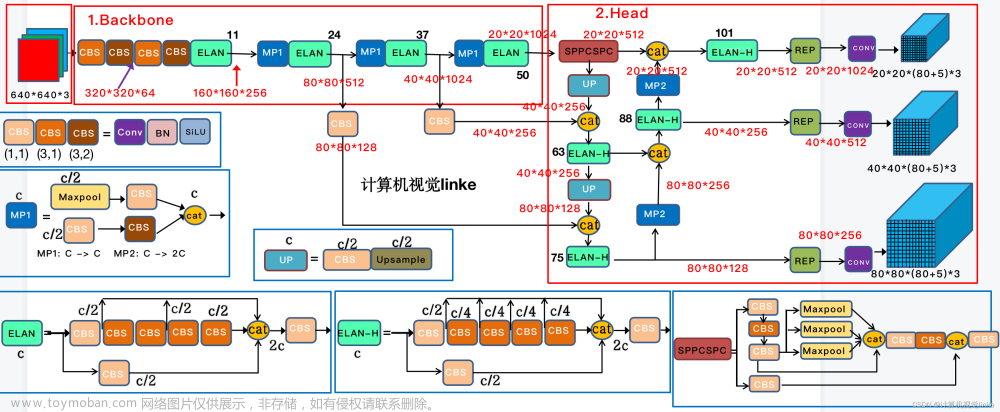
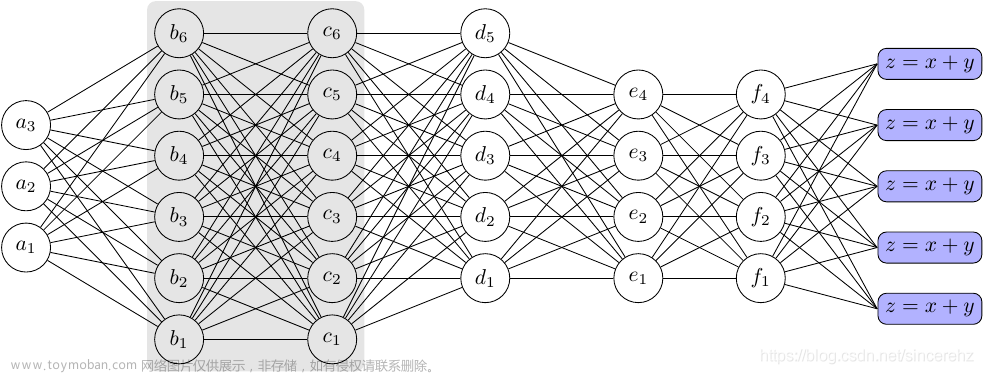
六、yolov7网络结构图

通过backbone获得3个有效特征层。特征金字塔可以将不同shape的特征层进行特征融合,有利于提取出更好的特征。
yolov7中将neck划分到了head里。
使用MP-1进行下采样,在卷积神经网络中,常见的用于下采样的模块是一个卷积核大小为3 * 3、步长为2 * 2的卷积或者一个步长为2*2的最大池化。池化层和卷积。左边的分支是一个步长为2 * 2的最大池化+1个1 * 1卷积,右边的分支是一个1 * 1卷积+1个卷积核大小为3 * 3、步长为2 * 2的卷积,两个分支的结果在输出时进行拼接。输出的通道数相较于输入没有改变,但是尺寸减半了,相当于复杂版的最大池化层。
目的是压缩宽和高,但是通道数不变。
加强特征提取模块。 作用是扩大感受野。池化核大小为5,9,13,无处理。
class SPPCSPC(nn.Module):
# CSP https://github.com/WongKinYiu/CrossStagePartialNetworks
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5, k=(5, 9, 13)):
super(SPPCSPC, self).__init__()
c_ = int(2 * c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(c_, c_, 3, 1)
self.cv4 = Conv(c_, c_, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
self.cv5 = Conv(4 * c_, c_, 1, 1)
self.cv6 = Conv(c_, c_, 3, 1)
self.cv7 = Conv(2 * c_, c2, 1, 1)
def forward(self, x):
x1 = self.cv4(self.cv3(self.cv1(x)))
y1 = self.cv6(self.cv5(torch.cat([x1] + [m(x1) for m in self.m], 1)))
y2 = self.cv2(x)
return self.cv7(torch.cat((y1, y2), dim=1))



在yolov7中,每一个特征层上每一个特征点存在3个先验框。
最后的255可以拆分成3个85,对应3个先验框的85个参数,85可以拆分成4+1+80。
前4个参数用于判断每一个特征点的回归参数,回归参数调整后可以获得预测框;
第5个参数用于判断每一个特征点是否包含物体;
最后80个参数用于判断每一个特征点所包含的物体种类。
七、yolov7x的网络结构图


八、检测模块
测试中用的都是detect模块,在训练中,使用的是Idetect和Iauxdetect模块。I的意思是implicit隐式的意思。对于隐式内容可以通过学习yolo-R来了解。
IDetect

九、文件之间的关系

1、yolov7和yolov7x是常规GPU的模型。yolov7x是在yolov7的基础上在颈部进行堆栈缩放,并使用所提出的复合缩放方法对整个模型的深度和宽度进行缩放得到的。
2、yolov7-d6、yolov7-e6、yolov7-e6e和yolov7-w6是云GPU的模型。对于yolov7-w6,我们使用新提出的复合缩放方法来获得yolov7-e6和yolov7-d6。此外,我们将所提出的E-ELAN用于yolov7-e6,从而完成yolov7-e6e。
3、yolov7-tiny和yolov7-tiny-silu是边缘GPU的模型。它们的区别只在于所使用的激活函数不同。yolov7-tiny它将使用Leaky ReLU作为激活函数。对于其他模型,我们使用SiLU作为激活函数。
十、预测结果的编码
具体可以看看这篇博文:睿智的目标检测61——Pytorch搭建YoloV7目标检测平台
1、获得预测框与得分
我们得到的三个特征层的预测结果并不对应着最终的预测框在图片上的位置,还需要解码才可以完成。
2、得分筛选与非极大抑制
得到最终的预测结果后还要进行得分排序与非极大抑制筛选。
得分筛选:筛选出得分满足confidence置信度的预测框。
非极大抑制:筛选出一定区域内属于同一种类得分最大的框。
十一、损失值部分
1、计算loss所需内容
计算loss实际上是 网络的预测结果和网络的真实结果的对比。
网络的损失由三个部分组成,分别是reg部分、obj部分和cls部分。
reg:特征点的回归参数判断
obj:特征点是否包含物体判断
cls:特征点包含的物体的种类文章来源:https://www.toymoban.com/news/detail-796953.html
2、正样本的匹配过程
(1)对每个真实框通过坐标与宽高粗略匹配先验框和特征点
(2)使用SimOTA自适应精确选取每个真实框对应多少个先验框
正样本匹配的概念: 寻找哪些先验框被认为有对应的真实框,并且负责这个真实框的预测。
a. 不再使用iou进行正样本的匹配,而是直接采用高宽比进行匹配。
b. SimOTA自适应匹配
在yolov7中,会计算一个Cost代价矩阵,代表每个真实框和每个特征点之间的代价关系,Cost代价矩阵由两个部分组成:
(1)每个真实框和当前特征点预测框的重合程度;
(2)每个真实框和当前特征点预测框的种类预测准确度;
以上两个值越高,Cost代价越小。文章来源地址https://www.toymoban.com/news/detail-796953.html
3、计算loss
- Reg部分,由第2部分知道每个真实框对应的先验框,获取到每个框对应的先验框后,取出该先验框对应的预测框,利用真实框和预测框计算CIOU损失,作为Reg部分的Loss组成。
- Obj部分,所有真实框对应的先验框都是正样本,剩余的先验框均为负样本,根据正负样本和特征点的是否包含物体的预测结果计算交叉熵损失,作为Obj部分的Loss组成。
- Cls部分,获取每个框的先验框后,取出该先验框的种类预测结果,根据真实框的种类和先验框的种类预测结果计算交叉熵损失,作为Cls部分的Loss组成。
到了这里,关于yolov7论文学习——创新点解析、网络结构图的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!