写在前面
本期内容:基于scrapy+mysql爬取博客信息并保存到数据库中
实验需求
- anaconda丨pycharm
- python3.11.4
- scrapy
- mysql
项目下载地址:https://download.csdn.net/download/m0_68111267/88740730
实验描述
本次实验实现了:使用Scrapy框架爬取博客专栏的目录信息并保存到MySQL数据库中,实验主要涉及到Python的爬虫技术以及MySQL的基本操作,需要有一定的基础。
实验框架
- Scrapy

实验需求
- Scrapy: Scrapy是一个基于Python的开源网络爬虫框架,用于快速、高效地获取网页数据。它具有强大的抓取能力,支持多线程和分布式爬虫,能够并行爬取多个网页。Scrapy提供了方便的API和丰富的功能,可以自定义爬虫规则和处理流程,支持数据的持久化存储和导出。它还提供了可视化的调试工具和强大的反爬虫策略,可以帮助开发者更轻松地构建和管理网络爬虫。Scrapy是一个成熟、稳定和广泛应用的爬虫框架,被广泛用于数据抓取、搜索引擎和大数据分析等领域。
- MySQL: MySQL是一个开源的关系型数据库管理系统,由Oracle Corporation开发和维护。它具有高性能、可靠性和稳定性,能够在各种不同规模的应用中存储和管理大量的数据。MySQL使用SQL语言进行数据操作和查询,支持多用户并发操作和事务处理,提供了丰富的功能和灵活的配置选项。它可以在多种操作系统上运行,并且与多种编程语言和开发工具兼容。MySQL被广泛应用于Web应用、企业级应用和大数据分析等领域。
实验内容
1.安装依赖库
本次实验需要安装scrapy库,如果没有scrapy库的话可以运行下面的命令进行安装哦~
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scrapy
2.创建Scrapy项目
- 在终端输入以下命令可以创建一个scrapy项目:
scrapy startproject myblog
- 项目框架如下:(此时你们应该没有"db.py"和"sp_blogs.py"文件)

- spiders:spiders 文件夹是 Scrapy 框架中存放爬虫代码的目录。在 spiders 文件夹中,会包含一个或多个 Python 文件,每个 Python 文件代表一个独立的爬虫。每个爬虫文件都需要继承自 Scrapy 的 Spider 类,并定义爬虫的名称、起始 URL、解析页面的方法等。在爬虫文件中,还可以定义一些其他的属性和方法,来实现对网页的抓取和解析。Scrapy 框架通过读取 spiders 文件夹中的爬虫文件来识别和启动爬虫。在运行爬虫时,可以指定要运行的爬虫名称,Scrapy 将会找到对应的爬虫文件并执行相应的代码。spiders 文件夹是 Scrapy 爬虫的核心部分,开发者可以根据需要在该文件夹下创建多个爬虫文件,以支持同时抓取和解析多个网站。
- items.py:items.py文件是Scrapy框架中用于定义数据模型的文件,用于指定爬取的数据结构。它定义了爬虫需要爬取和保存的数据字段,类似于数据库表的结构,方便数据的提取和存储。在items.py文件中,使用Python的类来定义数据模型,每个类的属性对应一个需要爬取和保存的字段。
- middlewares.py:middlewares.py文件是Scrapy框架中用于处理请求和响应的中间件文件。中间件是Scrapy框架的一个重要组成部分,用于对请求进行预处理、对响应进行处理或者是处理异常情况。middlewares.py文件中定义了多个中间件类,每个中间件类都有特定的功能,例如设置请求头、代理设置、处理重定向等。通过在settings.py中配置中间件的顺序,Scrapy框架会按照顺序依次使用不同的中间件对请求和响应进行处理。
- pipelines.py:pipelines.py文件是Scrapy框架中用于处理数据的管道文件。在Scrapy中,管道是一个用于处理爬取到的数据的组件,可以对数据进行清洗、验证、存储或者是发送到其他系统。pipelines.py文件中定义了多个管道类,每个管道类都有特定的功能,例如将数据存储到数据库、写入文件、发送邮件等。通过在settings.py中配置管道的优先级,Scrapy框架会按照优先级顺序依次使用不同的管道对爬取到的数据进行处理。
- settings.py:settings.py 文件是 Scrapy 框架中的配置文件,用于管理和配置爬虫的各种设置选项。在 settings.py 文件中,可以设置爬虫的名称、启用或禁用的中间件、管道、下载器、并发请求数、延迟、日志级别等。settings.py 文件包含了许多可配置的选项,可以根据实际需求进行调整。通过修改 settings.py 文件,可以改变爬虫的行为,并对其进行个性化定制。此外,settings.py 文件还提供了一些默认的全局配置选项,这些选项可以决定爬虫的运行方式和输出结果。
- 在终端输入以下命令创建爬虫文件
scrapy genspider sp_blogs "https://want595.blog.csdn.net/category_12039968_1.html"
该命令将使用Scrapy生成一个名为"sp_blogs"的爬虫,并将爬虫的起始URL设置为"https://want595.blog.csdn.net/category_12039968_1.html"。(本次实验需要爬取的就是这个专栏的目录)
输入完这个命令后,在spiders的目录下就会出现"sp_blogs.py"这个文件啦~
3.配置系统设置
打开"settings.py"文件,配置系统设置:



4.配置管道文件
"pipelines.py"文件,主要用于编写代码处理爬取的数据,例如存放到文件中,数据库中等等
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
import pymysql
from twisted.enterprise import adbapi
class MyblogPipeline:
def __init__(self, dbpool):
self.dbpool = dbpool
@classmethod
def from_settings(cls, settings):
dbparams = dict(
host=settings['MYSQL_HOST'], # 读取settings中的配置
db=settings['MYSQL_DBNAME'],
user=settings['MYSQL_USER'],
passwd=settings['MYSQL_PASSWD'],
charset='utf8', # 编码要加上,否则可能出现中文乱码问题
cursorclass=pymysql.cursors.DictCursor,
use_unicode=False,
)
dbpool = adbapi.ConnectionPool('pymysql', **dbparams) # **表示将字典扩展为关键字参数,相当于host=xxx,db=yyy....
return cls(dbpool) # 相当于dbpool付给了这个类,self中可以得到
# pipeline默认调用
def process_item(self, item, spider):
query = self.dbpool.runInteraction(self.insert, item) # 调用插入的方法
query.addErrback(self.error, item, spider) # 调用异常处理方法
return item
# 写入数据库中
def insert(self, db, item):
# print item['name']
sql = "insert ignore into blogs(title,url) values(%s,%s)"
params = (item["name"], item["url"])
db.execute(sql, params)
# 错误处理方法
def error(self, failue, item, spider):
print(failue)
该代码是一个Twisted框架下的MySQL数据库存储的Pipeline。Twisted是一个事件驱动的网络框架,使用异步的方式处理网络请求。
该代码中的MyblogPipeline类继承自object类,并且实现了__init__、from_settings、process_item、insert和error方法。
-
__init__方法初始化了一个数据库连接池dbpool,并将其赋值给self.dbpool。 -
from_settings方法从配置文件中读取数据库的相关配置信息,并利用这些信息创建一个数据库连接池dbpool。 -
process_item方法是Pipeline默认调用的方法,用于处理item并存储到数据库中。在该方法中,首先调用self.dbpool.runInteraction()方法创建一个操作数据库的事务,并调用self.insert方法将item插入到数据库中。然后,通过addErrback方法添加了一个异常处理方法self.error。 -
insert方法接收两个参数,一个是数据库连接对象db,一个是item。在该方法中,定义了一个SQL语句和参数,并通过db.execute()方法执行了数据库插入操作。 -
error方法用于处理插入数据库时的异常情况,将异常信息打印出来。
总体而言,该代码实现了将爬取的数据存储到MySQL数据库中的功能。
5.连接数据库
新建一个"db.py"文件,输入以下代码连接到本地数据库,运行后创建一个表,用于保存等会爬取的数据。
import pymysql
from scrapy.utils.project import get_project_settings # 导入seetings配置
class DBHelper:
def __init__(self):
self.settings = get_project_settings() # 获取settings配置,设置需要的信息
self.host = self.settings['MYSQL_HOST']
self.port = self.settings['MYSQL_PORT']
self.user = self.settings['MYSQL_USER']
self.passwd = self.settings['MYSQL_PASSWD']
self.db = self.settings['MYSQL_DBNAME']
# 连接到具体的数据库(settings中设置的MYSQL_DBNAME)
def connectDatabase(self):
conn = pymysql.connect(host=self.host,
port=self.port,
user=self.user,
passwd=self.passwd,
db=self.db,
charset='utf8') # 要指定编码,否则中文可能乱码
return conn
# 创建表
def createTable(self, sql):
conn = self.connectDatabase()
cur = conn.cursor()
try:
cur.execute(sql)
cur.close()
conn.close()
print("创建表成功!")
except:
print("创建表失败!")
pass
# 插入数据
def insert(self, sql, *params): # 注意这里params要加*,因为传递过来的是元组,*表示参数个数不定
conn = self.connectDatabase()
cur = conn.cursor();
cur.execute(sql, params)
conn.commit() # 注意要commit
cur.close()
conn.close()
if __name__ == "__main__":
dbHelper = DBHelper()
sql = "create table pictures(id int primary key auto_increment,name varchar(50) unique,url varchar(200))"
dbHelper.createTable(sql)
这段代码是一个用于操作MySQL数据库的助手类。它使用了Scrapy框架的get_project_settings函数来获取配置信息,然后根据配置信息连接到数据库。
在初始化方法中,它获取到了MySQL数据库的主机地址、端口号、用户名、密码和数据库名,并保存在实例变量中。
-
connectDatabase方法用于连接到具体的数据库,并返回一个数据库连接对象。 -
createTable方法用于创建表,它接受一个SQL语句作为参数,使用数据库连接对象执行SQL语句来创建表。 -
insert方法用于插入数据,它接受一个SQL语句和参数作为参数,使用数据库连接对象执行SQL语句来插入数据。
最后在主函数中,创建了一个DBHelper对象,并调用createTable方法来创建一个名为pictures的表。
6.分析要爬取的内容
本实验要爬取的是博客专栏的目录信息:


7.编写爬虫文件
编写"spiders"目录下的"sp_blogs.py"文件,实现博客信息的爬取:
import scrapy
from scrapy import Selector, cmdline
class MyblogItem(scrapy.Item):
name = scrapy.Field()
url = scrapy.Field()
class SpBlogsSpider(scrapy.Spider):
name = "sp_blogs"
allowed_domains = ["want595.blog.csdn.net"]
……请下载后查看完整代码哦
这段代码是一个基于Scrapy框架的爬虫,用于爬取一个博客网站的文章标题和链接。
首先定义了一个MyblogItem类,它继承自scrapy.Item,并定义了两个字段name和url,用于保存文章的标题和链接。
然后定义了一个SpBlogsSpider类,它继承自scrapy.Spider,表示一个具体的爬虫。在SpBlogsSpider类中,指定了爬虫的名字为sp_blogs,指定了允许爬取的域名为want595.blog.csdn.net,并指定了要爬取的起始URL。起始URL使用了一个循环生成器,生成了多个URL,用于爬取多页的数据。
parse方法是默认的回调方法,在爬取网页的响应返回后自动被调用。在parse方法中,使用Selector对象对响应进行了解析,提取出了文章的标题和链接,并将它们保存到MyblogItem对象中,然后通过yield返回给引擎。
最后,通过调用cmdline.execute函数来执行爬虫。执行时会根据给定的参数调用对应的爬虫。在这里,使用'scrapy crawl sp_blogs'参数来执行sp_blogs爬虫。(也可以在终端项目的根目录下运行scrapy crawl sp_blogs命令来执行爬虫。)
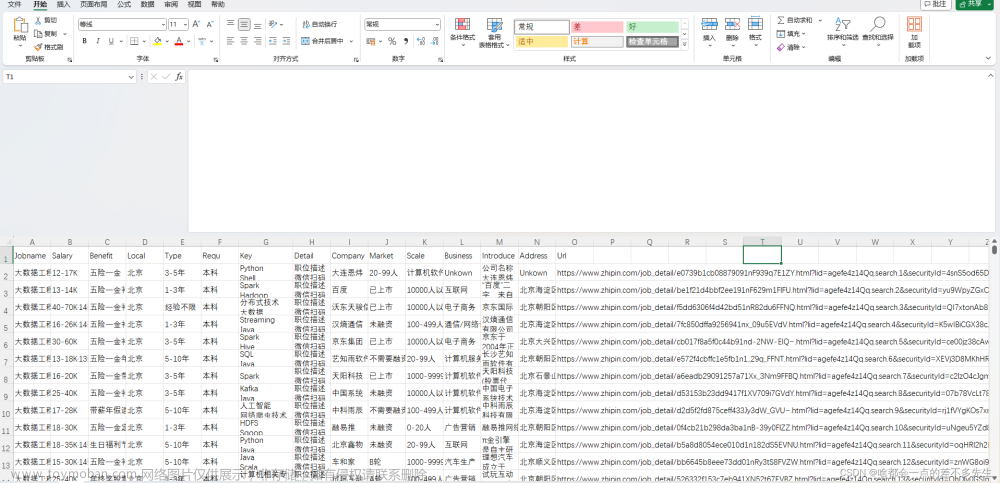
运行结果
爬取的博客信息如下:
 文章来源:https://www.toymoban.com/news/detail-797263.html
文章来源:https://www.toymoban.com/news/detail-797263.html
写在后面
我是一只有趣的兔子,感谢你的喜欢!文章来源地址https://www.toymoban.com/news/detail-797263.html
到了这里,关于网络爬虫丨基于scrapy+mysql爬取博客信息并保存到数据库中的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!