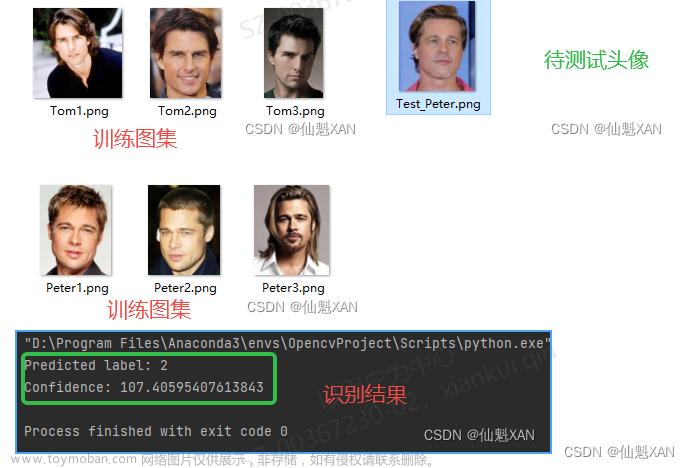
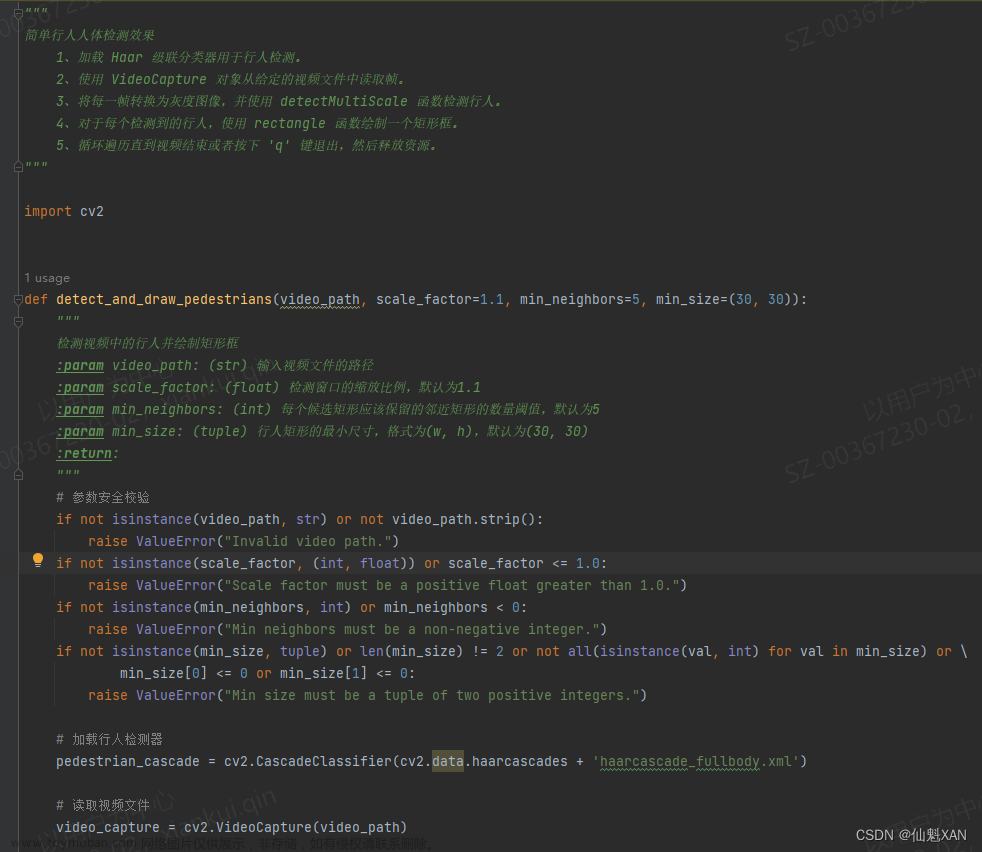
1. 面部跟踪概述
面部跟踪主要是从图像或视频中检测出人脸并输出人脸位置及其大小等有效信息,并在后续帧中继续捕获人脸的位置及其大小等信息,实时跟踪人脸。此技术可用于海关、机场、视频会议、拍照对焦、面部打码等业务场景。(与人脸识别是不同范畴)
本文主要利用opencv读取摄像头或视频文件信息,通过mediapipe对opencv读取的图像数据进行人脸检测跟踪。其中每张人脸都表示为一个检测原型消息。输出结果包含一个边界框:xmin,ymin,width,height 和 6 个关键点(右眼、左眼、鼻尖、嘴巴中心、右耳垂体和左耳垂体),模型有两种模式,一种是距离摄影机2米以内的面的短距离模型,一种是距离摄影机5米以内的面的全范围模型。
2. 面部跟踪python代码实现
首先利用opencv模块中的VideoCapture类创建一个待检测视频对象
cap = cv2.VideoCapture(vido)
入参vido可以是数字0或1代表调用摄像头,也可以是路径加视频文件名称代表使用视频文件。
然后调用mediapip模块中的mp.solutions.face_detection模块,使用FaceDetection类创建一个人面部跟踪对象:
mpFace = mp.solutions.face_detection
face = mpFace.FaceDetection(min_detection_confidence=0.5, model_selection=0)
其中两个参数分别代码置信度和检测模式,置信度取值[0,1]的float类型值,取值越高,检测越准确。
模式取值0或1的int类型,使用0则是选择最适合距离摄影机2米以内的面的短距离模型。使用1则是选择最适合距离摄影机5米以内的面的全范围模型。
最后,使用调用face对象的proc方法,得到检测结果:
results = face.process(img_rgb)
遍历results结果中的值,分别能够得到面部矩形框和6个关键点坐标,注意,这里的坐标都是百分比相对值,实际像素坐标需要乘以图片的长宽像数值。代码如下所示:
import time
import mediapipe as mp
import cv2
def face_detection(vido):
pTime = 0
cap = cv2.VideoCapture(vido)
mpFace = mp.solutions.face_detection
face = mpFace.FaceDetection(
min_detection_confidence=0.5, # 人脸检测模型中的最小置信值
model_selection=0) # 使用0选择最适合距离摄影机2米以内的面的短距离模型,使用1选择最适合距离摄影机5米以内的面的全范围模型
myDraws = mp.solutions.drawing_utils
keypointStyle = myDraws.DrawingSpec(color=(0, 0, 255), thickness=3)
bboxStyle = myDraws.DrawingSpec(color=(0, 255, 0), thickness=2)
while True:
ret, img = cap.read()
if ret:
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
results = face.process(img_rgb)
if results.detections:
for detection in results.detections:
boxLms = detection.location_data.relative_bounding_box
print(boxLms)
face_key_points = []
for i in range(6):
face_key_point = mpFace.get_key_point(detection, mpFace.FaceKeyPoint(i))
face_key_point = [i, face_key_point.x, face_key_point.y]
face_key_points.append(face_key_point)
print(face_key_points)
myDraws.draw_detection(img, detection, keypointStyle, bboxStyle)
cv2.putText(img, f'score:{int(detection.score[0] * 100)}%',
(int(boxLms.xmin * img.shape[1]) - 20, int(boxLms.ymin * img.shape[0]) - 20),
cv2.FONT_HERSHEY_PLAIN, 3, (0, 255, 0), 2)
cTime = time.time()
fps = 1 / (cTime - pTime)
pTime = cTime
cv2.putText(img, f"FPS:{int(fps)}", (30, 50), cv2.FONT_HERSHEY_PLAIN, 3, (255, 0, 0), 3)
cv2.imshow("Frame", img)
if cv2.waitKey(1) == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
def main():
face_detection(0)
# face_mesh(0)
if __name__ == "__main__":
main()三、最终效果
代码运行效果如下,能够有效检测并追踪人脸面部,对多人面部检测追踪也非常有效,效率极高,对硬件要求低。可根据此方法进行海关、监控等摄像头的人脸检测,能够有效压缩存储空间(画面中无人脸的视频段可不用存储),视频处理人脸马赛克,换头像等应用。值得注意的是,本文讲诉的方法和调用的类库只是人脸检测,人脸识别是另一个范畴,有机会笔者在进行介绍。人脸检测追踪具体效果如下:
xmin: 0.37054682
ymin: 0.56353134
width: 0.2559849
height: 0.341313
[[0, 0.44780921936035156, 0.6519981026649475],
[1, 0.5592537522315979, 0.6494688391685486],
[2, 0.5099092721939087, 0.7245292067527771],
[3, 0.5084657669067383, 0.7989646792411804],
[4, 0.3766010105609894, 0.6967787742614746],
[5, 0.6136240363121033, 0.6912295818328857]]
 文章来源:https://www.toymoban.com/news/detail-797583.html
文章来源:https://www.toymoban.com/news/detail-797583.html
 文章来源地址https://www.toymoban.com/news/detail-797583.html
文章来源地址https://www.toymoban.com/news/detail-797583.html
到了这里,关于基于opencv与mediapipe的面部跟踪(人脸检测追踪)python代码实现的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!