4篇应用解耦表示学习的文章,这里只关注如何解耦,更多细节不关注,简单记录一下。
1.Robust Multimodal Brain Tumor Segmentation via Feature Disentanglement and Gated Fusion
Chen C, Dou Q, Jin Y, et al. Robust multimodal brain tumor segmentation via feature disentanglement and gated fusion[C]//Medical Image Computing and Computer Assisted Intervention–MICCAI 2019: 22nd International Conference, Shenzhen, China, October 13–17, 2019, Proceedings, Part III 22. Springer International Publishing, 2019: 447-456.
【核心思想】
通过特征解耦和门控融合技术,提高了在部分成像模态缺失时的分割准确性。方法是将输入的多种成像模态解耦为模态特定的外观代码和模态不变的内容代码,然后将它们融合为一个共享表示。这种方法增强了面对缺失数据时分割过程的鲁棒性,并在多种缺失模态的场景中显示出显著的改进。论文还使用了BRATS挑战数据集来验证方法的有效性,并展示了与当前最先进方法相比的竞争性能。
这篇文章中的解耦在于对不同模态使用各自独立的encoder编码为内容编码和样式编码
【网络结构】
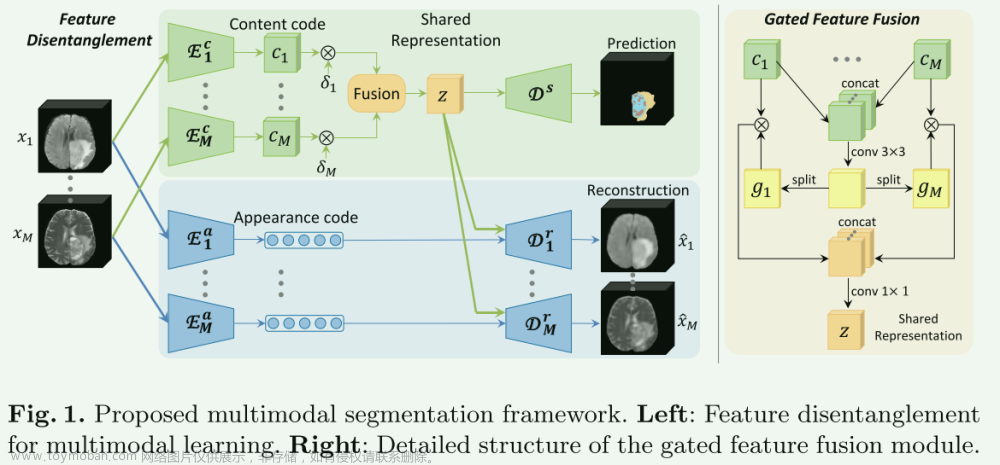
模型关键在于它采用了创新的特征解耦和门控融合技术,这里只关注特征解耦,另外的部分在我另外一篇博客中有记录。
-
特征解耦部分:负责将不同成像模态(如MRI)的数据分解为模态特定的外观特征和跨模态的内容特征。
对于外观代码,并将其设置为8位向量,假设其先验分布是中心各向同性高斯 N ( 0 , I ) N(0, I) N(0,I),使用KL散布逼近。
对于模态不变性的内容编码,将它们融合成表达肿瘤基本语义内容的集成表示。为保证解耦是有效性,所获得的内容表示 z z z 应该能够在给定某种模态的任何外观代码的情况下重建原始图像。为了鼓励这种重建能力,论文通过引入一组特定于模态的解码器来设计伪循环一致性损失(使用 L1-Norm 来减轻生成的图像变得模糊的情况。
为了模拟缺失模态,使用了modality 级别的dropout,也就是图中的 δ i \delta_{i} δi,这种思路在后续很多的论文中被采用,如mmFormer(MICCAI,2022),MMMViT(Biomedical Signal Processing and Control,2024)…
2.Disentangle domain features for cross-modality cardiac image segmentation
Pei C, Wu F, Huang L, et al. Disentangle domain features for cross-modality cardiac image segmentation[J]. Medical Image Analysis, 2021, 71: 102078.
本文的核心思想是提出一种新的跨模态医学图像分割方法,它通过特征分离技术解决了源域和目标域数据之间的差异。这种方法将图像特征分为领域不变特征(DIFs)和领域特定特征(DSFs),通过创新的零损失函数和自注意力模块来增强特征的表现力。文章通过在心脏图像分割任务上的实验验证了其有效性,展示了在处理不同成像模式的医学图像时的优越性能。

源域的有标签数据集表示为 $ X_s = {(x_{si}, y_{si}) | i = 1, \ldots, n} $,目标域的无标签数据集表示为 $ X_t = {x_{tj} | j = 1, \ldots, m}$。作者提出了一种特征分离的方法,以学习两个域的领域不变特征(DIFs)和领域特定特征(DSFs)该框架首先使用四个编码器将每个域的特征分离为DIFs和DSFs(其中style也是从标准正态分布中采样的8bits向量)。然后,它们交换DIFs并将其解码为具有保持解剖结构和交换风格(域/成像方式)的特定于域的图像。作者对生成的图像进行重复的编码和解码操作,形成了CycleGAN的改进版本。为了增强特征分离操作,作者进一步采用了零损失,迫使从源域图像中提取的目标域特定特征的值为零,反之亦然(背后的假设是,如果编码器只能从源域中提取 DSF,那么它将从目标域的图像中提取零信息)。成功分离特征后,可以使用DIFs和相应的标签来训练分割模型。为了实现更准确的分割,作者引入了一个额外的判别器,以限制生成分割的解剖形状。为了模拟图像区域间的长距离、多层次依赖关系,作者引入了自注意力模块。
3.Unsupervised domain adaptation via disentangled representations: Application to cross-modality liver segmentation
Yang J, Dvornek N C, Zhang F, et al. Unsupervised domain adaptation via disentangled representations: Application to cross-modality liver segmentation[C]//Medical Image Computing and Computer Assisted Intervention–MICCAI 2019: 22nd International Conference, Shenzhen, China, October 13–17, 2019, Proceedings, Part II 22. Springer International Publishing, 2019: 255-263.
本论文的核心思想是提出了一种无监督领域适应方法,通过使用解离表示来处理跨模态医学图像(如CT和MRI)之间的转换。这个方法通过将图像分解到一个共享的、与域无关的内容空间和一个特定于域的风格空间,实现了在不同医学成像模态之间有效适应。这样的设计旨在维护不同领域间复杂的语义信息,同时在具体的医学图像分割任务,如肝脏分割上,展现出卓越的性能和泛化能力。

- 解耦表示学习模块:该模块由两个主要组件组成,一个用于重建的变分自动编码器(VAE)和一个用于对抗训练的生成对抗网络(GAN)。训练 VAE 组件进行域内重建,其中重建损失最小化,以鼓励编码器和生成器彼此相反。用于跨域翻译的 GAN 组件经过训练,可以鼓励潜在空间的解开,将其分解为内容和风格子空间。模块由几个联合训练的编码器 E c 1 E_{c1} Ec1, E c 2 E_{c2} Ec2, E s 1 E_{s1} Es1, E s 1 E_{s1} Es1,生成器 G 1 G_1 G1, G 2 G_2 G2和判别器 D 1 D_1 D1, D 2 D_2 D2组成。生成器试图通过使用交换样式代码成功的跨域生成来欺骗鉴别器。由于解开的样式代码 si ∈Si,底层映射被假定为多对多。收敛时有 p ( c 1 ) = p ( c 2 ) p\left(c_{1}\right)=p\left(c_{2}\right) p(c1)=p(c2),这是保存解剖信息的共享内容空间。
- 纯内容图像的域适应:一旦学习到解离的表示后,可以仅使用内容代码ci而不使用风格代码si来重建仅包含内容的图像。对于CT和MR,它们的内容代码都嵌入在一个共享的潜在空间中,该空间包含解剖结构信息并排除模态外观信息。论文在来自CT领域的仅包含内容的图像上训练一个分割模型,并直接将其应用于来自MR领域的仅包含内容的图像。
4.Disentangled representation learning in cardiac image analysis
Chartsias A, Joyce T, Papanastasiou G, et al. Disentangled representation learning in cardiac image analysis[J]. Medical image analysis, 2019, 58: 101535.
核心思想是开发一种新的医学影像处理方法,特别是针对心脏影像。该方法通过空间解剖网络(SDNet)将医学影像分解为两个组成部分:一个空间解剖因子和一个非空间方式因子。这种方法使得医学影像的分析更为有效,适用于半监督分割、多任务分割和回归、以及影像到影像的合成。这种解耦表示不仅提高了分割任务的性能,而且为医学影像分析提供了更具解释性和多样性的方法。

首先使用解剖编码器 f a n a t o m y f_{anatomy} fanatomy 将输入图像编码为多通道空间表示,即解剖因子 s s s 。然后 s s s 可以用作分割网络 h h h 的输入,以生成多类分割掩码(或某些其他特定于任务的网络)。模态编码器 f f f 模态使用因子 s s s 和输入图像来生成表示成像模态的潜在向量 z z z。将两个表示 s s s 和 z z z 组合起来,通过解码器网络 g g g 重建输入图像。
- 解剖编码器:U-Net。空间表示是一个由相同空间尺寸的多个二进制通道组成的特征图。一些通道包含单独的解剖(心脏)子结构,而其他对重建必要的结构则自由分布在剩余通道中,而其余通道包含了周围的图像结构(尽管更混合,解剖上不那么明显)。空间表示是通过使用softmax激活函数得到的,以强制每个像素在通道间的激活值之和为一。
- 模态表示:输入解剖因子和原始图像,学习后验分布。论文采用VAE 学习低维潜在空间,使得学习到的潜在表示与设置为各向同性多元高斯 p ( z ) = N ( 0 , 1 ) p(z)=\mathcal{N}(0,1) p(z)=N(0,1) 的先验分布匹配。
基于以上四篇论文可以对Disentangled representation learning简要总结如下:
Disentangled representation learning 是一种机器学习方法,旨在从复杂数据集中学习出表示,这些表示能够揭示数据中的基础结构和变化因素。该领域的关键思想是将真实世界数据中的变化因素(如物体的位置、大小、颜色、纹理、解剖结构等)分离出来,并以一种方式表示,使得这些因素相互独立。以下是该领域的一些常见做法和应用:
常见做法
- 变分自编码器(VAEs): 通过潜在空间的学习来表示数据。在这个潜在空间中,不同的维度尝试捕捉数据的不同特征。
- 生成对抗网络(GANs): 在GANs中,可以进行修改以鼓励潜在空间的不同维度表示不同的数据特征。
- 信息瓶颈(Information Bottleneck): 这种方法通过限制模型可以访问的信息量,迫使模型学习更有效的数据表示。
- 约束优化: 在模型训练过程中引入特定的约束,例如正则化项,以鼓励表示的分离。
- 监督或半监督学习: 使用带标签的数据来引导学习过程,确保潜在空间中的不同维度对应于特定的、有意义的变化。
应用文章来源:https://www.toymoban.com/news/detail-797603.html
- 图像处理: 在图像编辑、风格转换、面部表情生成等领域,分离表示学习使得可以独立地操纵图像的不同特征。
- 数据压缩: 通过学习数据的有效表示,可以实现更高效的数据压缩。
- 强化学习: 在强化学习中,分离表示可以帮助更好地理解环境状态和决策因素。
- 异常检测: 分离的表示可以用于识别数据中的异常或偏差,因为它们可能不遵循正常数据的分布。
- 生物医学数据分析: 在这个领域,分离表示可以用于识别不同的生物标志物或疾病特征。
这些方法和应用展示了分离表示学习在理解和操作复杂数据方面的潜力。通过这种方法,可以更容易地识别和利用数据中的关键特征,从而在各种任务中实现更好的性能文章来源地址https://www.toymoban.com/news/detail-797603.html
到了这里,关于【论文阅读笔记】4篇Disentangled representation learning用于图像分割的论文的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!












