使用 Python 内置的 urllib 库获取网页的 html 信息。注意,urllib 库属于 Python 的标准库模块,无须单独安装,它是 Python 爬虫的常用模块。
获取网页 HTML 信息
1) 获取响应对象
向百度(http://www.baidu.com/)发起请求,获取百度首页的 HTML 信息,代码如下:
#导包,发起请求使用urllib库的request请求模块
import urllib.request
# urlopen()向URL发请求,返回响应对象,注意url必须完整
response=urllib.request.urlopen('http://www.baidu.com/')
print(response)
上述代码会返回百度首页的响应对象, 其中 urlopen() 表示打开一个网页地址。注意:请求的 url 必须带有 http 或者 https 传输协议。
输出结果,如下所示:<http.client.HTTPResponse object at 0x032F0F90>
上述代码也有另外一种导包方式,也就是使用 from,代码如下所示:
#发起请求使用urllib库的request请求模块
from urllib import request
response=request.urlopen('http://www.baidu.com/')
print(response)
2) 输出HTML信息
在上述代码的基础上继续编写如下代码:
#提取响应内容
html = response.read().decode('utf-8')
#打印响应内容
print(html)
输出结果如下:![第一个Python程序_获取网页 HTML 信息[Python爬虫学习笔记],Python,Python爬虫,python,html,爬虫](https://imgs.yssmx.com/Uploads/2024/01/797744-1.png)
通过调用 response 响应对象的 read() 方法提取 HTML 信息,该方法返回的结果是字节串类型(bytes),因此需要使用 decode() 转换为字符串。
程序完整的代码程序如下:
import urllib.request
# urlopen()向URL发请求,返回响应对象
response=urllib.request.urlopen('http://www.baidu.com/')
# 提取响应内容
html = response.read().decode('utf-8')
# 打印响应内容
print(html)
通过上述代码获取了百度首页的 html 信息,这是最简单、最初级的爬虫程序。后续我们还学习如何分析网页结构、解析网页数据,以及存储数据等。
常用方法
使用了第一个爬虫库 urllib,下面关于 urllib 做简单总结。
1) urlopen()
表示向网站发起请求并获取响应对象,如下所示:urllib.request.urlopen(url,timeout)
urlopen() 有两个参数,说明如下:文章来源:https://www.toymoban.com/news/detail-797744.html
- url:表示要爬取数据的 url 地址。
- timeout:设置等待超时时间,指定时间内未得到响应则抛出超时异常。
2) Request()
该方法用于创建请求对象、包装请求头,比如重构 User-Agent(即用户代理,指用户使用的浏览器)使程序更像人类的请求,而非机器。重构 User-Agent 是爬虫和反爬虫斗争的第一步。之后会介绍urllib.request.Request(url,headers)
参数说明如下:文章来源地址https://www.toymoban.com/news/detail-797744.html
- url:请求的URL地址。
- headers:重构请求头。
3) html响应对象方法
bytes = response.read() # read()返回结果为 bytes 数据类型
string = response.read().decode() # decode()将字节串转换为 string 类型
url = response.geturl() # 返回响应对象的URL地址
code = response.getcode() # 返回请求时的HTTP响应码
4) 编码解码操作
#字符串转换为字节码
string.encode("utf-8")
#字节码转换为字符串
bytes.decode("utf-8")
到了这里,关于第一个Python程序_获取网页 HTML 信息[Python爬虫学习笔记]的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

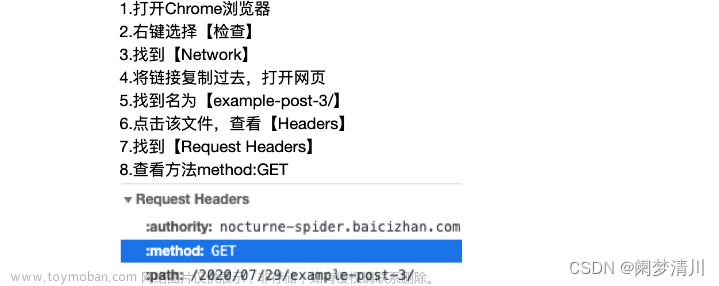
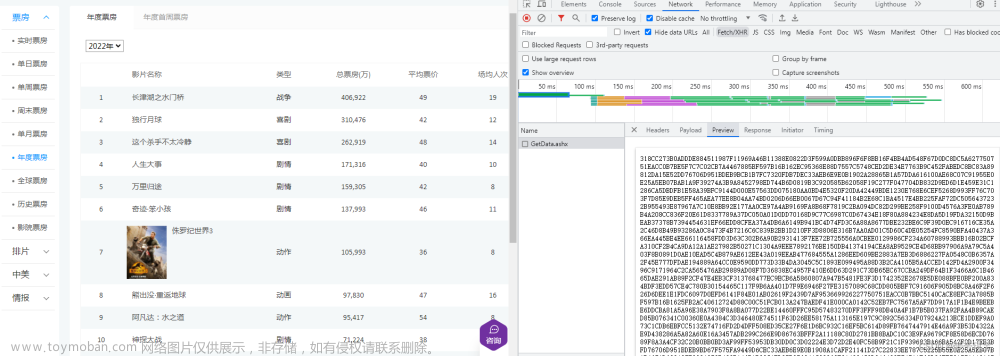





![python爬取豆瓣电影排行前250获取电影名称和网络链接[静态网页]————爬虫实例(1)](https://imgs.yssmx.com/Uploads/2024/01/415693-1.png)



