目录
一:下载Flink,并制作parcel包
1.相关资源下载
2. 修改配置
准备工作一:
准备工作二:
3. 开始build
二:开始在CDH页面分发激活
三:CDH添加Flink-yarn 服务
四:启动不起来的问题解决
五:CDH6.3.2集群集成zookeeper3.6.3
六:重新适配Flink服务
环境说明:
cdh版本:cdh6.3.2
组件版本信息如下:
| 组件 | 版本 |
|---|---|
| Cloudera Manager | 6.3.1 |
| Flume | 1.9.0+cdh6.3.2 |
| Hadoop | 3.0.0+cdh6.3.2 |
| HBase | 2.1.0+cdh6.3.2 |
| Hive | 2.1.1+cdh6.3.2 |
| Hue | 4.2.0+cdh6.3.2 |
| Impala | 3.2.0+cdh6.3.2 |
| Kafka | 2.2.1+cdh6.3.2 |
| Solr | 7.4.0+cdh6.3.2 |
| spark | 2.4.0+cdh6.3.2 |
| Sqoop | 1.4.7+cdh6.3.2 |
| ZooKeeper | 3.4.5+cdh6.3.2 |
一:下载Flink,并制作parcel包
1.相关资源下载
1.1) flink下载地址: https://archive.apache.org/dist/flink/flink-1.17.0/flink-1.17.0-bin-scala_2.12.tgz
1.2) parcel制作工具:https://github.com/pkeropen/flink-parcel.git
1.3) cm验证工具:https://github.com/cloudera/cm_ext.git
说明: 需要用到maven,unzip,确保已安装并配置mvn环境变量,需要提前下载上面的两个工具和flink.到本地,然后上传到服务器。

红框里面的是下载下来,重命名,解压放到 flink-parcel目录里面的。黄框里的是后面制作是生成的。下载好的包放入flink-parcel目录里面需要将名字和图片一致。
用到的命令:
mvn -version #验证本地maven安装环境变量配置是否OK.
unzip flink-parcel-master.zip # 解压包到当前目录
mv ./flink-parcel-master/* ./ flink-parcel #重命名
chmod +x ./build.sh #将build.sh 文件赋予可执行
unzip ./cm_ext-master.zip #解压包到当前目录
mv ./cm_ext-master ./cm_ext #重命名
mv ./cm_ext /opt/install/flink-parcel/ #移动到flink-parcel目录下
mv ./flink-1.17.0-bin-scala_2.12.tgz /opt/install/flink-parcel/ #移动到flink-parcel目录下
2. 修改配置
修改flink-parcel.properties为以下内容:
#FLINK 下载地址 此地址写上只是为了脚本取值时有值可取,是否正确无所谓,因为目录里面已经包含了下载好的包,会用下载好的包。此行注释掉,后面脚本运行会报错。
FLINK_URL=https://mirrors.tuna.tsinghua.edu.cn/apache/flink/flink-1.17.0/flink-1.17.0-bin-scala_2.12.tgz#flink版本号
FLINK_VERSION=1.17.0
#扩展版本号
EXTENS_VERSION=BIN-SCALA_2.12
#操作系统版本,以centos为例
OS_VERSION=7
#CDH 小版本
CDH_MIN_FULL=5.2
CDH_MAX_FULL=6.3.3
#CDH大版本
CDH_MIN=5
CDH_MAX=6
准备工作一:
执行脚本时会有一个报错,已查阅
/opt/cloudera/parcels/FLINK/lib/flink/bin/flink-yarn.sh: line 17: rotateLogFilesWithPrefix: command not found
此脚本里面缺少俩个方法,添加上。
参考:flink/config.sh at release-1.11.6 · apache/flink · GitHub
# Auxilliary functions for log file rotation
rotateLogFilesWithPrefix() {
dir=$1
prefix=$2
while read -r log ; do
rotateLogFile "$log"
# find distinct set of log file names, ignoring the rotation number (trailing dot and digit)
done < <(find "$dir" ! -type d -path "${prefix}*" | sed s/\.[0-9][0-9]*$// | sort | uniq)
}
rotateLogFile() {
log=$1;
num=$MAX_LOG_FILE_NUMBER
if [ -f "$log" -a "$num" -gt 0 ]; then
while [ $num -gt 1 ]; do
prev=`expr $num - 1`
[ -f "$log.$prev" ] && mv "$log.$prev" "$log.$num"
num=$prev
done
mv "$log" "$log.$num";
fi
}将上述俩个方法加到/opt/cloudera/parcels/FLINK/lib/flink/bin/flink-yarn.sh 脚本里面,加到readMasters() 这个方法上面。其实加到哪个方法前应该都可以,看上面官方,这俩个方法是在这个方法上面,所以不乱自操作。加入后,俩个方法和上面官方可以对比下代码,看是否有偏差。
准备工作二:
在安装flink的机器上环境变量加上 vim /etc/profile
export HADOOP_CLASSPATH=`hadoop classpath`
source /etc/profile #使生效
echo ${HADOOP_CLASSPATH} #验证
3. 开始build
cd /opt/install/flink-parcel
./build.sh parcel
#maven会下载很多依赖,打包完成后会在当前目录生成FLINK-1.17.0-BIN-SCALA_2.11_build文件里面就包含了三个文件:
FLINK-1.17.0-BIN-SCALA_2.12-el7.parcel
FLINK-1.17.0-BIN-SCALA_2.12-el7.parcel.sha
manifest.json
构建flink-yarn csd包
./build.sh csd_on_yarn
执行完回生成FLINK_ON_YARN-1.17.0.jar文件
好了,制作完成了,下面就是加入到CDH里面。(我是在cdh03上做的,但是/opt/cloudera/parcel-repo 这个目录只在cdh01上有,scp拷贝到01上的)
(1)将FLINK-1.17.0-BIN-SCALA_2.11_build里的文件放到/opt/cloudera/parcel-repo,并修改所属用户和组
(2)将FLINK_ON_YARN-1.17.0.jar 放到 /opt/cloudera/csd/,并修改所属用户和组
cd /opt/cloudera/parcel-repo
mv manifest.json manifest.json.bak #先将已有的备份
cp /opt/install/flink-parcel/FLINK-1.17.0-BIN-SCALA_2.12_build/* ./
chown cloudera-scm. ./*
cp /opt/install/flink-parcel/FLINK_ON_YARN-1.17.0.jar /opt/cloudera/csd/
cd /opt/cloudera/csd/
chown cloudera-scm. FLINK_ON_YARN-1.17.0.jar
二:开始在CDH页面分发激活
点击Parcel,然后右上角点击 检查新Parcel.


按照提示,会进行分配,然后点击激活就可以

三:CDH添加Flink-yarn 服务
主页点击添加服务。如果这时候点击过去没有看到 flink-yarn 的服务,需要将CDH重启,此时我的就是没有,先是在CDH的主节点重启 systemctl stop cloudera-scm-server。发现停不掉。就直接整个大重启了,因为是新搭建好的,还没有放入数据和任务。所以就直接全部重启了。先在CDH页面上停掉了Cloudera Management Service 服务,然后又把集群所有的服务都停掉了,然后每台机器的cloudera-scm-server、cloudera-scm-agent也都停掉了,重启按照反的顺序重启。然后就可以看到有flink-yarn服务了。

选择部署的主机,然后进入配置页面。下面俩项不予配置,不给验证。点击继续。启动。

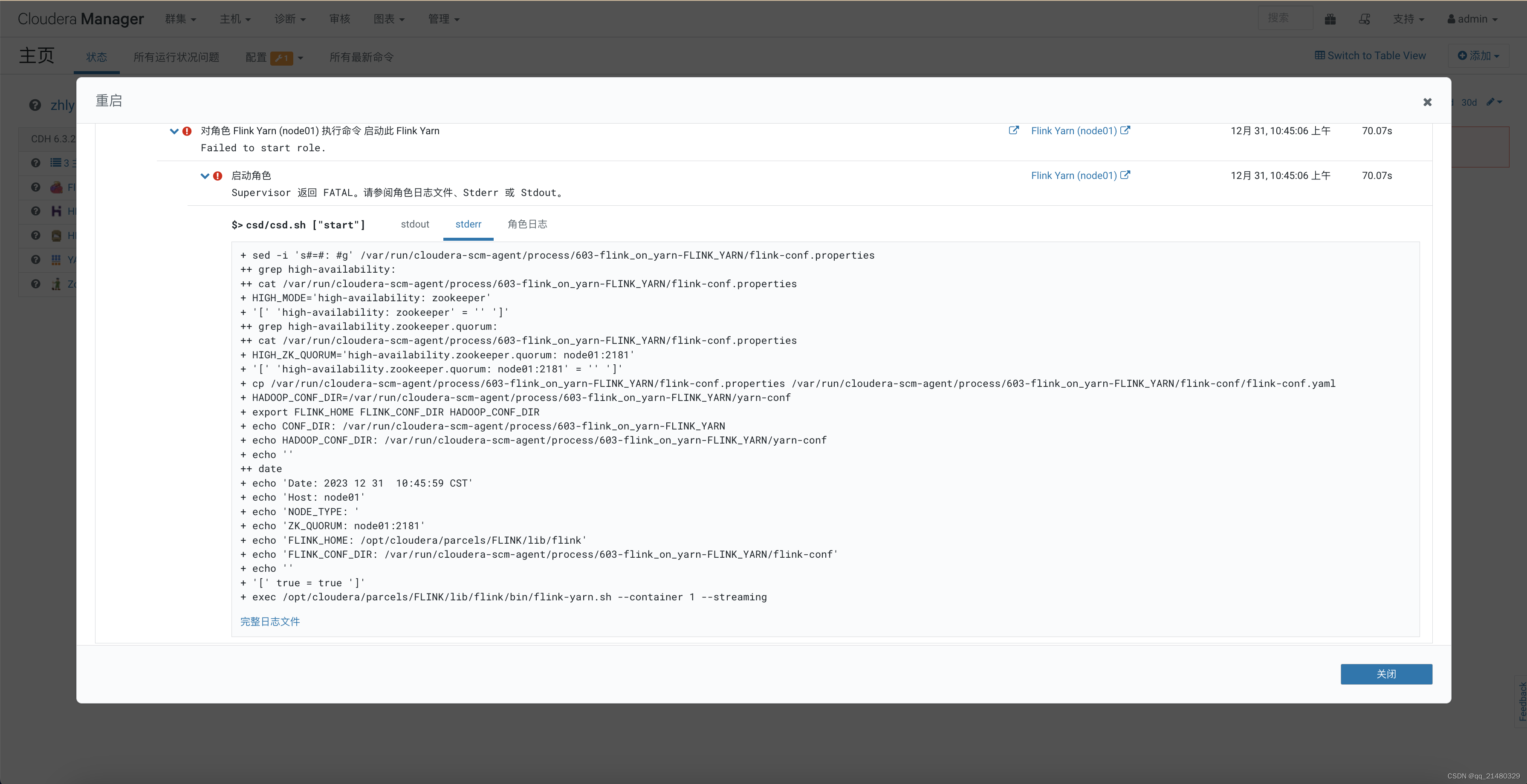
四:启动不起来的问题解决
启动时会提示一个 HBASE_CONF_DIR 没有设置。这时候关闭本页面,直接进入CDH主页,点击flin-yarn组件,进入,点击配置 输入 Flink-yarn 服务环境高级配置代码段(安全阀)添加如下:
HADOOP_USER_NAME=flink
HADOOP_CONF_DIR=/etc/hadoop/conf
HADOOP_HOME=/opt/cloudera/parcels/CDH
HADOOP_CLASSPATH=/opt/cloudera/parcels/CDH/jars/*
HBASE_CONF_DIR=/etc/hbase/conf

这时不报这个错误了,但是还报了个其他的错误,找不到具体的报错信息了。
解决是将 flink-shaded-hadoop-3-uber-3.1.1.7.2.9.0-173-9.0.jar 放到了 /opt/cloudera/parcels/FLINK/lib/flink/lib 目录下。https://mvnrepository.com/artifact/org.apache.flink/flink-shaded-hadoop-3-uber
中间还遇到端口被占,改了rest.port 端口 8082。并且在服务器上 /opt/cloudera/parcels/FLINK/lib/flink/conf master也改了 localhost:8082。
Flink启动时报错:NoSuchMethodError: org.apache.commons.cli.Option.builder
【问题与解决】Flink启动时报错:NoSuchMethodError: org.apache.commons.cli.Option.builder_flink程序报错nosuchfielderror: runtime_mode_MomentNi的博客-CSDN博客
并且还有个启动报错,然后我这个flink服务安装到了有 JobHistoryServer 的服务的节点上。是后来将之前的flink-yarn换了节点部署。直接从节点上删除了然后重新添加的角色实例。
这时才遇到了版本的错误:
flink的启动日志在:/var/log/flink/flink-yarn.out 里面。下面是全部的报错日志。也怀疑过其他问题,但是最让我先想到的应该是zk版本不兼容。本来想的是直接在flink配置上去掉zk.但是提示,必须要勾选ZK.后面准备集成高版本zk到集群然后配置flink,看是否有其他问题。
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/FLINK-1.17.0-BIN-SCALA_2.12/lib/flink/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/jars/hive-jdbc-2.1.1-cdh6.3.2-standalone.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/jars/log4j-slf4j-impl-2.8.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/jars/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/jars/avro-tools-1.8.2-cdh6.3.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/jars/parquet-tools-1.9.0-cdh6.3.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/jars/slf4j-simple-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
ERROR StatusLogger Reconfiguration failed: No configuration found for '6e0be858' at 'null' in 'null'
17:09:35.425 [main] ERROR org.apache.flink.yarn.cli.FlinkYarnSessionCli - Error while running the Flink session.
org.apache.flink.client.deployment.ClusterDeploymentException: Couldn't deploy Yarn session cluster
at org.apache.flink.yarn.YarnClusterDescriptor.deploySessionCluster(YarnClusterDescriptor.java:437) ~[flink-dist-1.17.0.jar:1.17.0]
at org.apache.flink.yarn.cli.FlinkYarnSessionCli.run(FlinkYarnSessionCli.java:608) ~[flink-dist-1.17.0.jar:1.17.0]
at org.apache.flink.yarn.cli.FlinkYarnSessionCli.lambda$main$4(FlinkYarnSessionCli.java:869) ~[flink-dist-1.17.0.jar:1.17.0]
at java.security.AccessController.doPrivileged(Native Method) ~[?:1.8.0_181]
at javax.security.auth.Subject.doAs(Subject.java:422) ~[?:1.8.0_181]
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1898) ~[flink-shaded-hadoop-3-uber-3.1.1.7.2.9.0-173-9.0.jar:3.1.1.7.2.9.0-173-9.0]
at org.apache.flink.runtime.security.contexts.HadoopSecurityContext.runSecured(HadoopSecurityContext.java:41) ~[flink-dist-1.17.0.jar:1.17.0]
at org.apache.flink.yarn.cli.FlinkYarnSessionCli.main(FlinkYarnSessionCli.java:869) [flink-dist-1.17.0.jar:1.17.0]
Caused by: org.apache.flink.yarn.YarnClusterDescriptor$YarnDeploymentException: The YARN application unexpectedly switched to state FAILED during deployment.
Diagnostics from YARN: Application application_1686298921271_0006 failed 1 times in previous 10000 milliseconds (global limit =2; local limit is =1) due to AM Container for appattempt_1686298921271_0006_000001 exited with exitCode: 239
Failing this attempt.Diagnostics: [2023-06-09 17:09:35.204]Exception from container-launch.
Container id: container_e05_1686298921271_0006_01_000001
Exit code: 239[2023-06-09 17:09:35.208]Container exited with a non-zero exit code 239. Error file: prelaunch.err.
Last 4096 bytes of prelaunch.err :[2023-06-09 17:09:35.209]Container exited with a non-zero exit code 239. Error file: prelaunch.err.
Last 4096 bytes of prelaunch.err :For more detailed output, check the application tracking page: http://cdh02:8088/cluster/app/application_1686298921271_0006 Then click on links to logs of each attempt.
. Failing the application.
If log aggregation is enabled on your cluster, use this command to further investigate the issue:
yarn logs -applicationId application_1686298921271_0006
at org.apache.flink.yarn.YarnClusterDescriptor.startAppMaster(YarnClusterDescriptor.java:1253) ~[flink-dist-1.17.0.jar:1.17.0]
at org.apache.flink.yarn.YarnClusterDescriptor.deployInternal(YarnClusterDescriptor.java:626) ~[flink-dist-1.17.0.jar:1.17.0]
at org.apache.flink.yarn.YarnClusterDescriptor.deploySessionCluster(YarnClusterDescriptor.java:430) ~[flink-dist-1.17.0.jar:1.17.0]
... 7 more------------------------------------------------------------
The program finished with the following exception:org.apache.flink.client.deployment.ClusterDeploymentException: Couldn't deploy Yarn session cluster
at org.apache.flink.yarn.YarnClusterDescriptor.deploySessionCluster(YarnClusterDescriptor.java:437)
at org.apache.flink.yarn.cli.FlinkYarnSessionCli.run(FlinkYarnSessionCli.java:608)
at org.apache.flink.yarn.cli.FlinkYarnSessionCli.lambda$main$4(FlinkYarnSessionCli.java:869)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1898)
at org.apache.flink.runtime.security.contexts.HadoopSecurityContext.runSecured(HadoopSecurityContext.java:41)
at org.apache.flink.yarn.cli.FlinkYarnSessionCli.main(FlinkYarnSessionCli.java:869)
Caused by: org.apache.flink.yarn.YarnClusterDescriptor$YarnDeploymentException: The YARN application unexpectedly switched to state FAILED during deployment.
Diagnostics from YARN: Application application_1686298921271_0006 failed 1 times in previous 10000 milliseconds (global limit =2; local limit is =1) due to AM Container for appattempt_1686298921271_0006_000001 exited with exitCode: 239
Failing this attempt.Diagnostics: [2023-06-09 17:09:35.204]Exception from container-launch.
Container id: container_e05_1686298921271_0006_01_000001
Exit code: 239[2023-06-09 17:09:35.208]Container exited with a non-zero exit code 239. Error file: prelaunch.err.
Last 4096 bytes of prelaunch.err :[2023-06-09 17:09:35.209]Container exited with a non-zero exit code 239. Error file: prelaunch.err.
Last 4096 bytes of prelaunch.err :For more detailed output, check the application tracking page: http://cdh02:8088/cluster/app/application_1686298921271_0006 Then click on links to logs of each attempt.
. Failing the application.
If log aggregation is enabled on your cluster, use this command to further investigate the issue:
yarn logs -applicationId application_1686298921271_0006
at org.apache.flink.yarn.YarnClusterDescriptor.startAppMaster(YarnClusterDescriptor.java:1253)
at org.apache.flink.yarn.YarnClusterDescriptor.deployInternal(YarnClusterDescriptor.java:626)
at org.apache.flink.yarn.YarnClusterDescriptor.deploySessionCluster(YarnClusterDescriptor.java:430)
... 7 more
后来换高版本的切换不上去,还用自带的zookeeper启动起来了,只是一会,立刻就会失败,在yarn上看到了任务直接是失败了,查看日志如下:
然后在flink配置里面添加
重启启动再次尝试 ,报错有变化:
还是版本有问题哈。
Curator 框架与 Zookeeer 版本 适配_curator兼容_KK架构的博客-CSDN博客
flink源码包里面使用的是5.2.0版本的
参考:Flink 报错:unable to generate a JAAS configuration file_flink 找不到tmp下文件目录_兔帮大人的博客-CSDN博客flink on yarn模式出现The main method caused an error: Could not deploy Yarn job cluster问题排查+解决_微电子学与固体电子学-俞驰的博客-CSDN博客【问题与解决】Flink启动时报错:NoSuchMethodError: org.apache.commons.cli.Option.builder_flink程序报错nosuchfielderror: runtime_mode_MomentNi的博客-CSDN博客https://www.cnblogs.com/braveym/p/16364148.htmlhttps://www.cnblogs.com/lebaishi/p/15852002.html#_label0_0cdh6.2+ 集成flink1.14.4_问道9527的博客-CSDN博客rotatelogfileswithprefix: command not found · Issue #5 · pkeropen/flink-parcel · GitHub
五:CDH6.3.2集群集成zookeeper3.6.3
参考:cdh升级zookeeper3.6.3集成parcels包cloudera Manager_柠檬味的鱼°的博客-CSDN博客
最后在启动时,会报错:
[root@cdh07 log]# cd /var/log/zookeeper/
[root@cdh07 zookeeper]# cat zookeeper-server-cdh07.log
Error occurred during initialization of VM
Initial heap size set to a larger value than the maximum heap size
然后查看启动时设置的大小,

修改配置文件应该也可以,但是机器是有内存的,直接修改CDH上的配置,给加大。

默认是1G,调到4G,然后启动成功。
六:重新适配Flink服务
将之前已有的flink角色实例,删掉,重新添加,准备换zk。

后来不管怎么配置,这里始终都只能选择这一个,没有第二个可以选择。并且在配置文件里面配置后来添加进来的zk角色列表,都会在启动flink服务时,被覆盖掉。在哪里修改都不好使。并且想了下,其实很简单的,只需要一个flink包就可以 flink on yarn 执行,在cdh上集成后,开启集群,flink在提交on yarn 任务时,会冲突,并没有什么实际意义。故放弃在CDH上集成高版本flink。可以尝试直接升级CDH自带的ZK版本,这样应该是可以适配flink高版本的。 但又有可能会对其他组件有兼容性问题,还是谨慎尝试。文章来源:https://www.toymoban.com/news/detail-798200.html
CDH 组件升级:zookeeper升级到 3.4.14_cdh升级zookeeper_根哥的博客的博客-CSDN博客文章来源地址https://www.toymoban.com/news/detail-798200.html
到了这里,关于CDH6.3.2 集成 Flink 1.17.0 失败过程的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!