优化前 mysql响应慢,导致算子中数据输出追不上输入,导致显示cpu busy:100%
优化后效果两个图对应两个时刻:
-

-
-- 优化前
select l.id,JSON_EXTRACT(r.msg,'$$.key1') as msgv
(select id,uid from tb1 l where id=?) join (select uid,msg from tb2) r on l.uid=r.uid;
-- 优化后 分两次查询mysql 并且jdbc解析通过flink而不是mysql where的条件都创建了mysql索引
select id,uid from tb1 l where id=? ;
select uid,msg from tb2 where uid=? ;guava
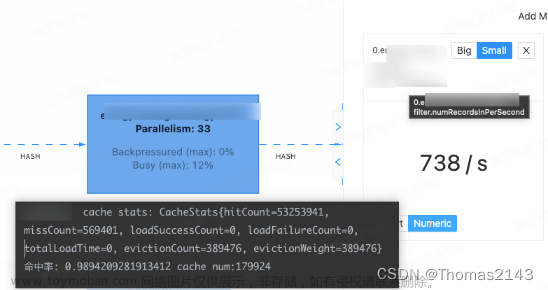
图中guava cache命中率是通过guava自带统计,打印出来的.文章来源:https://www.toymoban.com/news/detail-798534.html
1 guava缓存数据量上限 = 类中配置的guava缓存数据上线 * task个数(即flink并行度)
缓存越久 命中率越高 数据越陈旧 这个需要结合业务和命中率综合考虑文章来源地址https://www.toymoban.com/news/detail-798534.html
到了这里,关于flink1.15 维表join guava cache和mysql方面优化的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!










