Chapter 1: Machine Learning

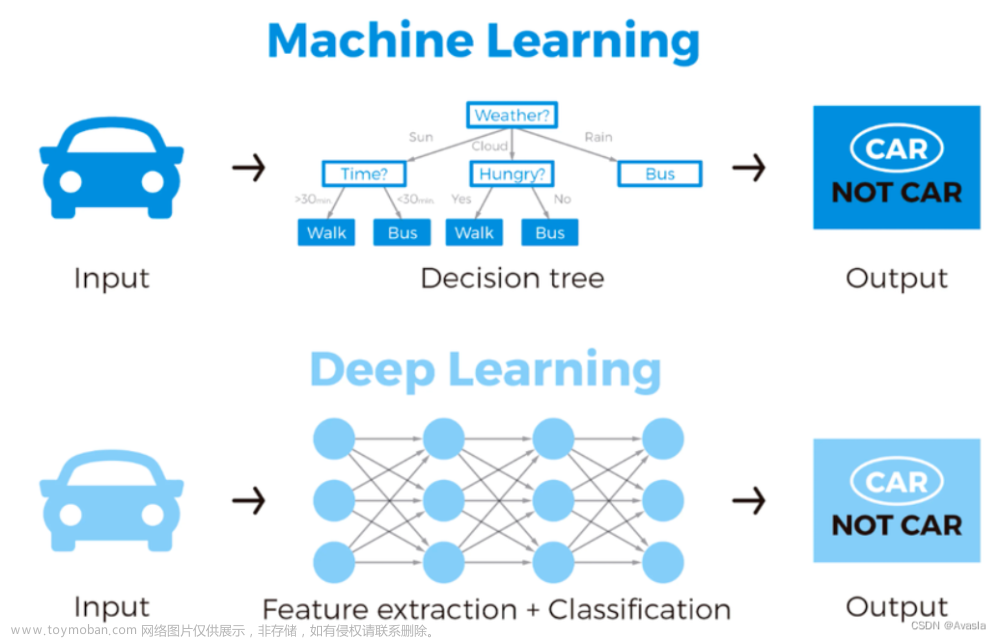
- 深度学习是一种机器学习,而机器学习是一种人工智能。
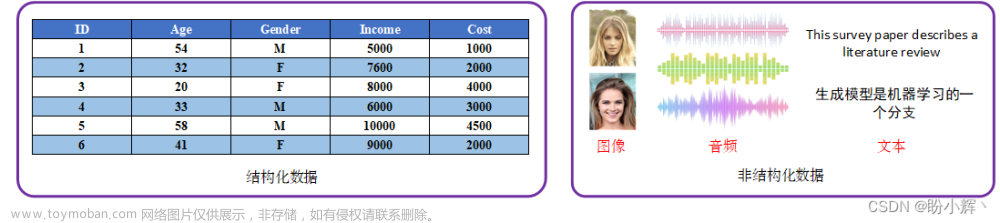
机器学习的本质:机器学习是一种从“数据”中找到“模型”的技术。在这里,数据的字面意思是指文档、音频、图像等信息。这个“模型”是机器学习的最终产物。

- 机器学习的创建是为了
解决分析模型几乎不可用的问题。机器学习的主要思想是在方程和定律不好时使用训练数据实现一个模型.

- 但是由于训练的数据与得出的模型是存在不同的

存在的问题
过拟合Overfitting
- 训练数据中始终会存在异常点,这些异常点会影响边界的分类,机器识别是不能识别这些异常点的,这就会造成,当你将训练数据全部考虑的时候,就会得到通用性较低的模型


以上面的图为例子:对于图一,似乎拟合的十分成功,但是对于应用在图二的身上的正确性就有待确认
解决过拟合 regularization and validation
regularization 正则化
- 正则化是一种尽可能
简单地试图构建模型结构的数值方法。简化的模型可以在较小的性能代价下避免过拟合的影响。
validation 验证
- 验证是一个保留一部分训练数据并使用其来监控性能的过程。验证集不用于培训过程。当训练后的模型对保留数据输入的性能水平较低时,模型被过拟合。在这种情况下,我们将修改模型,以防止过拟合。

机器学习的验证的过程:
1.将训练数据分为两组:一组用于训练,另一组用于验证。根据经验,训练集与验证集的比率是8:2。
2.用训练集来训练模型。
3.使用验证集来评估模型的性能。
a.如果该模型的表现令人满意,则完成训练。
b.如果性能不能产生足够的结果,则修改模型并重复步骤2中的过程。
交叉验证:交叉验证是验证过程中的一个细微变化。它仍然将训练数据分成组进行训练和验证,但不断改变数据集。交叉验证不是保留最初的划分集,而是重复对数据的划分。这样做的原因是,当模型是固定的时,模型也会过度拟合。由于交叉验证保持了验证数据集的随机性,它可以更好地检测模型的过拟合。

机器学习的类型
- 根据训练方法,这些机器学习技术可以分为三种类型
有监督学习(Supervised Learning),无监督学习(Unsupervised Learning),强化学习(Reinforcement Learning)


有监督学习
有监督学习步骤:
1.选择一个练习问题。运用现有的知识来解决这个问题。比较一下答案和解决方案。
2.如果答案是错误的,请修改当前的知识。
3.对所有的练习问题,重复步骤1和步骤2。
- 在监督学习中,每个训练数据集都应该由
输入对和正确的输出对组成。正确的输出是模型应该为给定的输入而产生的输出。- 在监督学习中,学习就是对模型进行一系列修正,以减少相同输入的正确输出和模型输出之间的差异。
分类Classification
分类问题的重点是从实际上查找数据所属的类。
垃圾邮件过滤服务➔分类邮件定期或垃圾邮件
数字识别服务➔分类数字图像到0-9
人脸识别服务➔人脸图像分类的注册用户之一
- 监督学习需要输入和正确的输出的训练数据。同样,分类问题的训练数据是:{ 输入,类别}
- 数据对用类代替了与输入对应的正确输出。
- 例子:我们希望机器学习回答的模型是用户的输入坐标(X,Y)属于这两个类(∆和)中的哪一个

- 那么输入的数据的形式就是

回归Regression
- 回归并不能决定类别。相反,它
估计了一个值。- 例如,如果您有年龄和收入的数据集(用a表示),并且想要找到按年龄估计收入的模型,它就变成一个回归问题

- 那么就有输入的数据的形式就是{ 年龄 ,收入 }

无监督学习
- 相比之下,无监督学习的训练数据
只包含没有正确输出的输入。- 无监督学习通常用于
研究数据的特征和对数据进行预处理。这个概念类似于一个学生,他只是通过构造和属性来分类问题,而不学习如何解决它们,因为没有已知的正确输出
聚类
- 聚类是无监督学习的代表性应用之一。
它调查了个体数据的特征,并对相关数据进行了分类。这很容易混淆聚类和分类,因为它们的结果是相似的。虽然它们产生相似的输出,但它们是两种完全不同的方法。我们必须记住,聚类和分类是完全不同的术语。当你遇到聚类这个术语时,只要提醒自己它关注的是无监督学习
强化学习
- 强化学习采用输入、一些输出和等级作为训练数据。它通常在需要最佳交互时使用,如控制和游戏玩法。
Chapter 2: Neural Network
- 我们用
神经网络代替模型,用学习规则代替机器学习。在神经网络的背景下,确定模型(神经网络)的过程被称为学习规则。

神经网络的结点Nodes of a Neural Network
- 神经网络模仿了大脑的作用机制。由于大脑是由许多
神经元的连接组成的,所以神经网络是由节点的连接构成的,这些节点是与大脑中的神经元相对应的元素。神经网络利用权重值来模拟神经元的关联,这是大脑最重要的机制。

- 神经网络的结点一般有输入,权重,偏差,输出组成
神经网络的信息以权值和偏差的形式存储起来

- 到达结点的输入是全部输入的加权和以及加上偏差(权重越大的结点对该结点的影响更大)

- 那么总的式子是可以用矩阵表示的

- 获得的输入会经过激活函数,然后输出(
激活函数决定了结点的行为)

- 那么就会有一个总的一个结点的行为

神经网络层Layers of Neural Network
- 根据节点的连接方式,可以创建多种神经网络。最常用的神经网络类型之一是节点分层结构。

- 正方形节点组称为
输入层。输入层的节点仅仅作为将输入信号传输到下一个节点的通道。因此,他们不计算加权和和激活函数。这就是它们用正方形表示并与其他圆形节点不同的原因。- 最右边的节点组被称为
输出层。从这些节点得到的输出成为神经网络的最终结果。- 位于输入层和输出层之间的图层被称为
隐藏层。它们被赋予这个名字是因为它们不能从神经网络的外部访问。
- 只有输入层和输出层,这被称为
单层神经网络。- 当隐藏层添加到单层神经网络时,就产生
多层神经网络。因此,多层神经网络由输入层、隐层和输出层组成。- 具有单一隐藏层的神经网络被称为
浅层神经网络或普通神经网络。- 一个包含两个或两个以上隐藏层的多层神经网络被称为
深度神经网络。


分层神经网络的工作:分层神经网络中,信号进入输入层,通过隐藏层,然后通过输出层离开。在这个过程中,信号一层地推进。换句话说,一层上的节点同时接收信号,并同时将处理后的信号发送到下一层

- 这里我们假设激活函数是一个线性函数


- 那么就有第一个结点的输出是 6 ,下面的那个隐藏结点的输出是 11
- 利用矩阵计算

文章来源:https://www.toymoban.com/news/detail-798744.html
- W 是权重矩阵,x 是输入向量,b 是偏差向量

- 那么对于下一层的计算:

- 可以说除了输入来自隐藏层,计算的过程是一样的
- 在该例子中,(由于我们使用了线性的激活函数)多层神经网络是可以看成一个单层神经网络
 文章来源地址https://www.toymoban.com/news/detail-798744.html
文章来源地址https://www.toymoban.com/news/detail-798744.html
神经网络的监督学习Supervised Learning of a Neural Network
神经网络的监督学习过程:
1.使用足够的值初始化权重。
2.从训练数据中取“输入”,格式化为{输入,正确输出},然后输入神经网络。从神经网络中获得输出,并从正确的输出中计算误差。
3.调整重量以减少误差。
4.对所有训练数据重复步骤2-3(个人觉得就是要提取输入与正确的输出,然后对权重进行相对应的调整)
- 与监督学习的联系与区别:这些步骤基本上与“机器学习类型”部分的监督学习过程相同。这是有意义的,因为有监督学习的训练是一个
修改模型的过程,以减少正确的输出和模型的输出之间的差异。唯一的区别是,对模型的修改变成了神经网络的权值的变化。
单层神经网络的训练Training of a Single-Layer Neural Network
Delta Rule 德尔塔定律
- 根据给定的信息来修改权值的系统方法称为
学习规则。
Chapter 3: Training of Multi-Layer Neural Network
Chapter 4: Neural Network and Classification
Chapter 5: Deep Learning
Chapter 6: Convolutional Neural Network
到了这里,关于MATLAB Deep learning的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!