随着实时分析需求的不断增加,数据的时效性对于企业的精细化运营越来越重要。借助海量数据,实时数仓在有效挖掘有价值信息、快速获取数据反馈、帮助企业更快决策、更好的产品迭代等方面发挥着不可替代的作用。
在这种情况下,Apache Doris 作为一个实时 MPP 分析数据库脱颖而出,它具有高性能和易用性,并且支持多种数据导入方式。结合 Apache Flink,用户可以从 MySQL 等上游数据库快速导入来自 Kafka 和 CDC(Change Data Capture) 的非结构化数据。 Apache Doris 还提供了亚秒级的分析查询能力,可以有效满足多维分析、仪表盘、数据服务等多种实时场景的需求。
挑战
通常,实时数据仓库要保证端到端的高并发和低延迟存在很多挑战,例如:
-
如何保证秒级的端到端数据同步?
-
如何快速保证数据可见性?
-
高并发情况下小文件写入问题如何解决?
-
如何保证端到端的Exactly-Once?
在上述挑战中,我们对用户使用 Flink 和 Doris 构建实时数仓的业务场景进行了深入研究。在抓住用户痛点后,我们在Doris 1.1版本中进行了针对性的优化,大大提升了用户体验,提高了稳定性。 Doris的资源消耗也得到了极大的优化。
优化
流式写入
Flink Doris Connector 最初的做法是在接收到数据后将数据缓存到内存批处理中。数据写入的方法是保存批处理,同时使用batch.size和batch.interval等参数来控制 Stream Load 写入的时机。
通常在参数合理的情况下运行稳定。无论参数不合理,都会导致频繁的Stream Load和不及时的compaction,导致版本错误过多(-235)。另一方面,当数据过多时,为了降低 Stream Load 的写入频率,将batch.size设置过大也可能导致 OOM。
为了解决这个问题,我们引入流式写入:
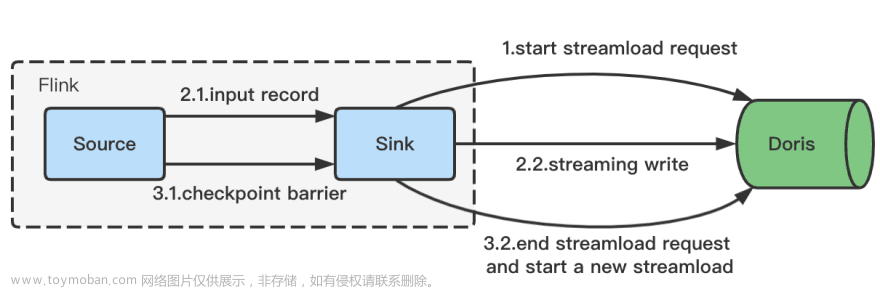
-
Flink任务启动后,会异步发起Stream Load Http请求。
-
收到数据后,会通过Http的Chunked传输编码,不断的传输给Doris。
-
Http 请求将在 Checkpoint 结束并完成 Stream Load 写入。下一个 Stream Load 请求将同时异步发起。
-
继续接收数据,后续流程同上。
由于采用 Chunked 机制传输数据,因此避免了批处理的内存压力。并且写入的时间与Checkpoint绑定,使得Stream Load的时间可控,为后面的Exactly-Once语义提供了基础。
恰好一次
Exactly-Once 意味着数据不会被重新处理或丢失,甚至不会出现机器或应用程序故障。 Flink 很早就支持 End-to-End 的 Exactly-Once 场景,主要是通过两阶段提交协议来实现 Sink 算子的 Exactly-Once 语义。
在 Flink 两阶段提交的基础上,借助 Doris 1.0 的 Stream Load 两阶段提交,Flink Doris Connector 实现了 Exactly Once 语义。具体原则如下:
- Flink任务启动时,会发起Stream Load PreCommit请求。这时候会先开启一个事务,通过Http的Chunked机制不断向Doris发送数据。

- 数据写入在 Checkpoint 结束时完成 Http 请求,并将事务状态设置为 preCommitted。数据已写入 BE,此时用户不可见。

- Checkpoint之后会发起一个Commit请求,事务状态会设置为Committed。数据将在请求后对用户可见。

- Flink 应用程序意外结束并从 Checkpoint 重启后,如果最后一个事务处于 preCommitted 状态,则会发起回滚请求,并将事务状态设置为 Aborted。
基于以上,可以使用 Flink Doris Connector 实现数据的实时存储,不丢不重。
秒级数据同步
高并发写入场景下端到端的秒级数据同步和数据的实时可见性,需要Doris具备以下能力:
- 交易处理能力
Flink 实时写入与 Doris 以 Stream Load 2pc 的形式进行交互,这需要 Doris 具备相应的事务处理能力来保证基本的 ACID 特性,并支持 Flink 在高并发场景下的秒级数据同步。
- 数据版本的快速聚合能力
Doris 中的一次导入将生成一个数据版本。在高并发写入场景下,不可避免的影响是数据版本过多,单次导入的数据量不会太大。持续的高并发小文件写入场景对实时性和Doris的数据合并性能非常考验,对Doris不友好,进而影响查询的性能。 Doris 在 1.1 版本中大幅增强了数据压缩能力,可以快速完成新数据的聚合,避免分片数据版本过多导致的 -235 错误和查询效率问题。
首先在Doris 1.1版本中引入了QuickCompaction,可以在数据版本增加时主动触发Compaction。同时,通过提高扫描分片元信息的能力,可以快速发现需要compact的分片并触发Compaction。通过主动触发和被动扫描,彻底解决了数据合并的实时性问题。
针对高频小文件Cumulative Compaction,实现Compaction任务的调度和隔离,防止重量级Base Compaction影响新数据的合并。
最后,采用梯度合并的方法对合并小文件的策略进行了优化。每次参与合并的文件属于同一数据量级,可以防止大小差异较大的版本合并,并逐步分层合并,减少单个文件参与合并的次数,可以大大节省系统的 CPU 消耗。

Doris 1.1 版本针对高并发导入、秒级数据同步、数据实时可见等场景进行了针对性的优化,极大的增加了 Flink 系统和 Doris 系统的易用性和稳定性,节省了整体资源集群。
效果
一般Flink高并发场景
在调查的一般场景中,使用 Flink 来同步上游 Kafka 中的非结构化数据。数据通过 ETL 后由 Flink Doris Connector 实时写入 Doris。
这里的客户场景非常严格。上游保持每秒10w的高频率,数据需要能够在5s内完成上下游同步,实现秒级数据可见性。 Flink 配置 20 并发,Checkpoint 间隔为 5s。 Doris 1.1 版本的性能相当出色。
具体体现在以下几个方面:
- 实时压缩
数据可以快速合并,tablet数据版本数保持在50以下,compaction分数稳定。与之前高并发导入场景下的-235问题相比,compaction效率提升了10倍以上。
[

- CPU资源消耗
Doris 1.1 版本优化了小文件的压缩策略。高并发导入场景下,CPU资源消耗降低25%。
- QPS查询延迟稳定
通过减少 CPU 使用率和数据版本数,提高了数据的整体顺序,减少了 SQL 查询的延迟。
秒级数据同步场景(超高压)
客户端单赌单平板30并发限流负载压力测试,实时数据<1s,compaction分数优化前后对比如下:

建议
实时数据可视化场景
对于延迟要求严格的场景,比如秒级数据同步,通常意味着单个导入文件很小,建议减少cumulative_size_based_promotion_min_size_mbytes。默认单位为64MB,可手动设置为8MB,即可以大大提高compaction的实时性。
高并发场景
对于高并发写入场景,可以通过增加检查点间隔来降低 Stream Load 的频率。例如,将 checkpoint 设置为 5-10s 不仅可以提高 Flink 任务的吞吐量,还可以减少小文件的生成,避免造成 compaction 更大的压力。
另外,对于数据实时性要求不高的场景,比如分钟级数据同步,可以增加checkpoint间隔,比如5-10分钟。并且 Flink Doris 连接器仍然可以通过两阶段提交和检查点机制来保证数据的完整性。
未来规划
- 实时架构更改
通过 Flink CDC 实时访问数据时,上游业务表会进行 schema 变更操作,需要在 Doris 和 Flink 任务中手动修改 schema。最终,重启任务后,新schema的数据就可以同步了。
这种方式需要人工干预,会给用户带来很大的操作负担。在后续版本中,实时schema变更将支持CDC场景,上游schema变更将实时同步到下游,全面提升schema变更效率。
- Doris 多表写作
目前 Doris Sink 算子只支持单表同步,所以对于整个数据库来说,还是要在 Flink 层面手动分流,写入多个 Doris Sink,会增加开发者的难度。在后续版本中,我们将支持单个 Doris Sink 同步多个表,大大简化了用户的操作。
- 自适应压缩参数调整
目前compaction策略的参数很多,在大部分通用场景下都能起到很好的作用,但是这些策略在一些特殊场景下仍然不能有效发挥作用。我们将在后续版本中继续优化,针对不同场景进行自适应compaction调优,不断提升各种场景下的数据合并效率和实时性。文章来源:https://www.toymoban.com/news/detail-798781.html
- 单副本压缩
目前的compaction策略是每个BE单独进行。在后续版本中,我们将实现单副本compaction,通过克隆快照实现compaction任务,减少系统负载的同时减少集群约2/3的compaction任务,将更多的系统资源留给用户侧。文章来源地址https://www.toymoban.com/news/detail-798781.html
到了这里,关于Flink实时写入Apache Doris如何保证高吞吐和低延迟的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!