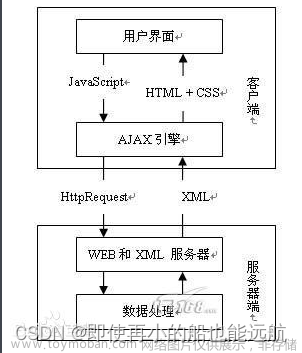
所需要的库
import time
from selenium import webdriver
from selenium.webdriver.common.by import By首先明确所要爬取的网页,选择调用方法,增加无界面模式的无头参数,然后调用,获取网址,使页面放大,为最大化窗口
url="https://maoyan.com/board/4"
options=webdriver.ChromeOptions()#选择调用方法
options.add_argument("--headless")#无界面模式的无头参数
driver=webdriver.Chrome(options=options)#让无参数调用
driver.get(url)#打开页面输入地址并确认
driver.maximize_window()#使页面放大,最大化页面窗口
time.sleep(3)#停留时间获取数据运用XPATH函数,将获取的数据作为item,运用XPATH函数获取,
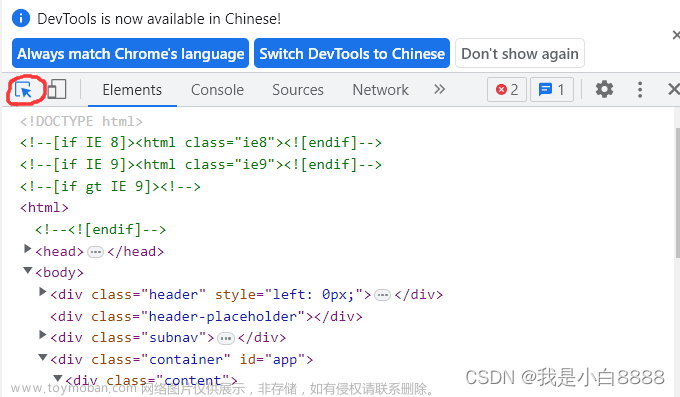
//*[@id='app']/div/div/div[1]/dl/dd为运用谷歌浏览器,在更多工具中找到开发者工具,点击图片选择的位置,将鼠标放在你想要爬取的数据上点击,自动跳转代码,查看代码,对代码行进行右击,选择copy,copy xpath。
文章来源地址https://www.toymoban.com/news/detail-799035.html
def get_data():
item_list=driver.find_elements(By.XPATH,"//*[@id='app']/div/div/div[1]/dl/dd")#xpath是数字是div,selector是函数直接是class里的
for list in item_list:
item={}
info_list=list.text.split("\n")#每爬取一行换行
item['number']=info_list[0]
item['name'] = info_list[1]
item['star'] = info_list[2]
item['time'] = info_list[3]
item['score'] = info_list[4]
print(item)
pass模仿人点击下一页,运用 for语句,每10个一点,停留5秒
for i in range(10):
time.sleep(5)
get_data()
driver.find_element(By.LINK_TEXT,"下一页").click()
time.sleep(10)
driver.quit()#结束同样寻找下一页所在位置,如果是这样写By.LINK_TEXT,click()为点击的意思

如果是如下界面,注意ID位置,有ID写ID,没有就写By.LINK_TEXT,click()。例如
driver.find_element(By.ID,"su").click()
.send_key写内容例如,同样注重ID
driver.find_element(By.ID,"kw").send_keys("白鹿")代码总结
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
url="https://maoyan.com/board/4"
options=webdriver.ChromeOptions()#调用方法
options.add_argument("--headless")#无界面模式无头参数
driver=webdriver.Chrome(options=options)#让无参数调用
driver.get(url)#打开页面输入地址并确认
driver.maximize_window()#使页面放大,最大化页面窗口
time.sleep(3)#
def get_data():
item_list=driver.find_elements(By.XPATH,"//*[@id='app']/div/div/div[1]/dl/dd")#xpath是数字是div,selector是函数直接是class里的
for list in item_list:
item={}
info_list=list.text.split("\n")
item['number']=info_list[0]
item['name'] = info_list[1]
item['star'] = info_list[2]
item['time'] = info_list[3]
item['score'] = info_list[4]
print(item)
pass
#模仿点击下一页
for i in range(10):
time.sleep(5)
get_data()
driver.find_element(By.LINK_TEXT,"下一页").click()
time.sleep(10)
driver.quit()#结束
如果有错误请告诉一下,谢谢!文章来源:https://www.toymoban.com/news/detail-799035.html
到了这里,关于selenium爬取网页内容,对网页内容进行点击的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!