@ARTICLE{9151265,
author={Xu, Han and Ma, Jiayi and Jiang, Junjun and Guo, Xiaojie and Ling, Haibin},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
title={U2Fusion: A Unified Unsupervised Image Fusion Network},
year={2022},
volume={44},
number={1},
pages={502-518},
doi={10.1109/TPAMI.2020.3012548}}
SCI A1;IF 23.6
论文地址
代码github
RoadScene数据集
📖论文解读
💭核心思想
训练阶段使用DenseNet提取源图像特征(包括了浅层特征和深层特征),然后对这些特征图求信息度量(特征梯度),由信息度量求处信息保留度(一个概率权重),将信息保留度与源信息(源图像)结合求损失函数。
损失函数=相似性损失(结构相似性+强度分布)+持续学习损失
🪢网络结构

①U2Fusion的pipeline如上图所示。
I
1
I_1
I1和
I
2
I_2
I2分别表示源图像,训练DenseNet以生成融合图像
I
f
I_f
If。特征提取的输出是特征图
ϕ
C
n
(
I
m
)
\phi_{C_n}(I_m)
ϕCn(Im)。
②对这些特征图进行信息度量得到两个度量值
g
I
1
g_{I_1}
gI1和
g
I
2
g_{I_2}
gI2
③经过处理后,得到两个信息保留度
ω
1
\omega_1
ω1和
ω
2
\omega_2
ω2
④损失函数由
I
1
I_1
I1、
I
2
I_2
I2、
ω
1
\omega_1
ω1和
ω
2
\omega_2
ω2组成,并不需要ground truth
⑤训练阶段,估计
ω
1
\omega_1
ω1和
ω
2
\omega_2
ω2,并用于损失函数
⑥测试阶段,
ω
1
\omega_1
ω1和
ω
2
\omega_2
ω2固定
摘要
①提出了一种新颖的【统一】【无监督】【端到端】图像融合网络U2Fusion,可以解决多模态、多曝光、多聚焦等不同的融合问题。
②通过【特征提取】和【信息度量】,U2Fusion可以【自动估计】对应源图像的【重要程度】,并给出【自适应信息保持度】。基于自适应度,训练好的网络可以保留融合图像和源图像的自适应相似性。因此解决了基于DL的图像融合中需要【ground truth】和【特定的设计规则】的问题。
③通过避免顺序地训练不同任务单模型时损失之前的融合能力,不同的融合任务可以在统一的网络框架下完成。
④发布了RoadScene数据集
关键词
- Image fusion 图像融合
- unified model 统一模型
- unsupervised learning 无监督学习
- continual learning 连续学习
1.引言
-
背景介绍
①背景:图像融合从安全到工业和民用领域有着重要的应用意义。
②挑战:因为硬件设备或光学成像的限制,使用单一传感器(拍摄)只能捕获单一信息。
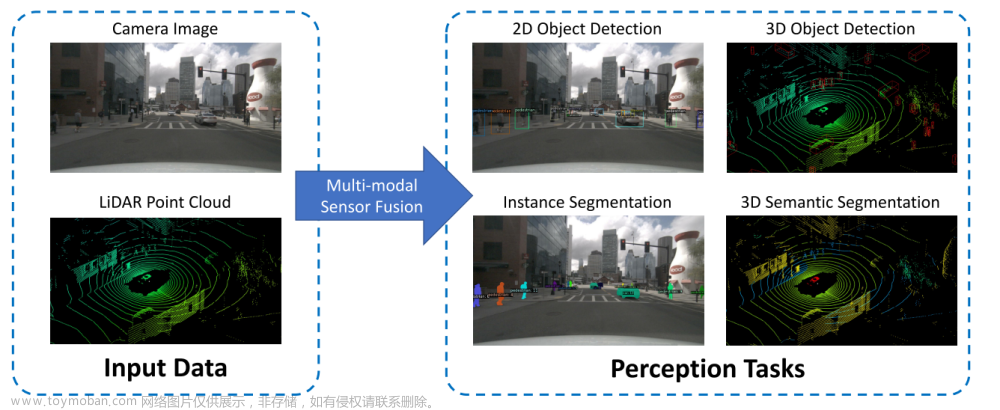
③ 定义:图像融合的目标是通过融合由多个传感器采集到的多个源图像的互补信息来生成融合图像。如图1所示。
④ 意义:具有更好场景表达和视觉感知的融合图像,更适合下游视觉任务如视频监控、场景理解和目标重识别。
-
引出挑战1
①图像融合分类:多模态、多曝光、多聚焦。
② 算法分类:基于传统融合框架、基于端到端的模型。
③ 承上启下:尽管这些算法在各自领域结果不错,但是仍然存在一些问题。
④ 传统缺陷:融合规则选择的有限性、人工设计的复杂度太高
⑤ 端到端缺陷:监督学习时过于依赖ground truth、无监督学习时过于依赖特定设计指标(specifically designed metrics)。
⑥挑战:缺乏多任务的通用ground truth和参考评价指标,阻碍了统一模型和有/无监督学习的发展 -
引出挑战2
① 相同:不同融合任务融合目标相同,即综合多张源图像的重要信息和互补信息合成融合图像
② 不同:不同融合任务源图像类型不同,需要融合的信息差异很大
③ 挑战:因为神经网络强大的特征表达能力可以统一表示各种信息,可以提出一个统一的融合框架 -
统一模型优点
①原因:不同融合问题可以相互促进,例如的训练好的用于多曝光融合的网络,可以有效改善多模态或多聚焦任务中曝光不足或曝光过度的问题
②总结:通过整合多任务的优势,统一模型可以为每个单融合任务实现更好的结果,并具有更强的泛化能力 -
贡献
① 方案:为了解决以上我呢提,提出了一个统一的无监督图像融合网络U2Fusion
②流程:- 为了保留信息,首先采用特征提取器来提取丰富而全面的特征;
- 为了定义这些特征的重要性,度量特征中的信息丰富程度。从而反应了源图像和融合结果的相似性关系,相似度越高,信息保留程度越高
③方法:使用DenseNet模块来训练不需要ground truth的网络
④具体贡献:- 用统一框架和参数解决了多图像融合任务问题。解决了【不同任务不同解决方案的问题】、【训练的存储和计算问题】以及【连续学习的遗忘问题】;
- 提出了U2Fusion。通过约束源图像和融合图像相似性解决了图像融合任务中缺乏统一ground truth和参考评估指标的问题。
⑤发布了RoadScene数据集。为图像融合基准评估提供了新的选择。
⑥在多个数据集下进行了多任务实验。验证了U2Fusion的有效性和通用性。
2. 相关工作
2.1 图像融合方法
2.1.1 传统融合框架方法
-
传统方法介绍:此类算法主要由【特征提取】和【特征融合】两个重要因素组成(【特征重建】往往是特征提取的逆过程),通过改进这两个因素可以使其应用于多模态、多曝光、多聚焦等任务。如图2所示。

-
传统融合方法分类
①多尺度变换:- Laplacian pyramid (LP),
- ratio of low-pass pyramid (RP)
- gradient pyramid (GP)
- discrete wavelet (DWT)
- discrete cosine (DCT) [13],
- curvelet transform (CVT)
- shearlet, etc.;
②稀疏表达
③子空间分析- independent component analysis (ICA)
- principal component analysis (PCA)
- nonnegative matrix factorization (NMF), etc.
④混合方式
⑤缺点:人工设计的特征提取方法过于复杂,增加了特征融合规则设计的难度;针对不同的任务,方法也要相应进行修改。还需要确保特征提取方法的恰当性以确保特征的完整性。(总之就是很麻烦)
⑥应对方法:为了克服缺点,一些方法引入了CNN(作为整体或者作为一个子模块) -
融合规则的设定
①融合规则的设定基于特征提取规则
②常用方法:- 最大值
- 最小值
- 相加
- L1范数等
③挑战:手动设计的融合规则性能会被限制
-
其他方法
①其他方法:- 基于梯度转移和总变差最小的VIF方法
- 优化结构相似性指数的多曝光融合方法
- 密集SIFT的多聚焦融合方法
②挑战:专用于特定的融合任务,泛化性不好
2.1.2 端到端方法
-
提出原因:为了避免设计融合规则
-
多模态图像融合
① FusionGAN,通过使用GAN,保留了IR图像的像素强度分布和VIS图像细节
② DDcGAN,通过引入双鉴别器结构,提升了热目标的突出性
③挑战:- VIF关注的问题在于像素强度分布和细节,在其他融合任务中并不适用。
- 此类任务缺乏ground truth
-
多曝光图像融合
① Deepfuse,采用了无参考度量的MEF-SSIM作为损失函数(丢弃了亮度分量,因为亮度分量在MEF任务中不重要),但是只适用于MEF
②缺点:没有ground truth -
多聚焦图像融合
① FuseGAN,生成器直接产生二元聚焦掩膜(binary focus mask),鉴别器区分mask和ground truth(使用归一化的原盘点扩展函数分离前景和背景)
②挑战:- 聚焦图/掩膜只使用MFIF,在其他任务不重要甚至不适用
- 此类方法基本都是基于监督学习
-
本文方法
① 引出:针对上述局限性,提出了U2Fusion
②模型特点:- 不受人工设计限制的端到端模型
- 可以解决多融合任务的统一模型
- 无监督模型,不需要ground truth
- 使用持续学习解决新任务的同时不会忘记旧任务(使用统一参数解决不同任务)
2.2 连续学习
①在持续学习中,学习被认为使一系列任务
②训练阶段,权重会在不忘记之前内容的前提下调整更新
③为了避免从之前任务中存储训练数据,许多弹性权重整合(elastic weight consolidation,EWC)方法被提出,使用一个正则化项约束参数与训练之前任务时保持相似。
④这项技术广泛应用于实际问题,如人员重识别、实时车辆检测、情感识别等。我们使用这项技术来解决多任务图像融合问题
3. 方法
①本方法允许使用不同传感器(拍摄设置)从相同机位采集图像。
②结构:本节介绍了问题公式化、损失函数设计、EWC和网络结构
3.1 问题公式化
-
目的介绍
①问题及方法:针对图像融合主要目标(保存源图像中重要信息),我们模型基于度量来确定信息丰富程度。
②原因:如果源图像包含了丰富的信息,融合结果应该于源图像高度相似
③核心问题:探索一个统一的度量方式来确定源图像的信息保存度。并不是使融合图像和ground truth相似性最大化,而是利用信息保存度使结果【自适应相似】(理解:即不是单纯的让相似性最大化,而是根据“信息保存度”,自适应决定相似性,以前是max{similarity},现在是 f 信息保存度 \mathcal f_{信息保存度} f信息保存度{similarity})
④意义:作为一种无监督模型,适用于ground truth难以获得的多融合问题 -
难点介绍
①难点:得到理想度量的难度在于,不同类型源图像【主要信息】差距大。- IR和PET图像:主要信息为热辐射信息和功能相应,以【像素强度】分布反应出来
- VIS和MRI图像:反射光和由【图像梯度】表示的结构内容
- 多聚焦:景深(depth-of-field , DoF)
- 多曝光:可以提高的场景内容
②解决方法:综合考虑源图像的多方面性质,提取浅层特征(纹理、局部结构)和深度特征(内容、空间结构)来估计信息度量。
-
U2Fusion的pipeline
①U2Fusion的pipeline如图3所示。 I 1 I_1 I1和 I 2 I_2 I2分别表示源图像,训练DenseNet以生成融合图像 I f I_f If。特征提取的输出是特征图 ϕ C n ( I m ) \phi_{C_n}(I_m) ϕCn(Im)。
②对这些特征图进行信息度量得到两个度量值 g I 1 g_{I_1} gI1和 g I 2 g_{I_2} gI2
③经过处理后,得到两个信息保留度 ω 1 \omega_1 ω1和 ω 2 \omega_2 ω2
④损失函数由 I 1 I_1 I1、 I 2 I_2 I2、 ω 1 \omega_1 ω1和 ω 2 \omega_2 ω2组成,并不需要ground truth
⑤训练阶段,估计 ω 1 \omega_1 ω1和 ω 2 \omega_2 ω2,并用于损失函数
⑥测试阶段, ω 1 \omega_1 ω1和 ω 2 \omega_2 ω2固定
3.1.1 特征提取
- 特征提取网络
①原因:其他计算机视觉任务训练使用的数据集更大更多样化,特征提取能力更强(与融合任务模型相比)
②方法:采用VGG16提取特征,如图4所示。模型输入I修改为单通道,复制成3份,变成3通道输入VGG16。
① 为了直观分析,多曝光图像对的特征图如图5所示。
②因为欠曝光图像亮度低,所以过曝光图像包含更多的纹理细节或者更大的梯度。
③图5中
ϕ
C
1
\phi_{C_1}
ϕC1和
ϕ
C
2
\phi_{C_2}
ϕC2是浅层特征(纹理和形状细节),在浅层特征中,过曝光特征图比欠曝光特征图信息更多
④
ϕ
C
4
\phi_{C_4}
ϕC4和
ϕ
C
5
\phi_{C_5}
ϕC5为深层特征(内容和空间结构),对比信息和额外信息出现在前曝光特征图里。
⑤浅层特征和深层特征结合,形成了人类视觉感知系统难以感知的综合表征。
3.1.2 信息度量
①方法:使用梯度进行特征图中的信息度量
②介绍:图像梯度是一种感受野小、基于局部空间结构的度量
③原因:在DL中,梯度计算和存储都更高效,更适合用于CNN的信息度量。其公式为:
其中,
ϕ
C
j
(
I
)
\phi_{C_j}(I)
ϕCj(I)为第j个最大池化层前卷积层的特征图。k是
D
j
D_j
Dj通道的第k个通道,
∣
∣
⋅
∣
∣
F
||·||_F
∣∣⋅∣∣F代表弗罗本尼乌斯范数(Frobenius norm),
∇
{\nabla}
∇是拉普拉斯算子。
3.1.3 信息保留度
①目的:为了保留源图像信息,求两个自适应权重作为信息保存度。信息保存度定义了融合图像和源图像相似度的权重。权重越高,期望的相似度越高,对应源图像的信息保存度越高。
②原因及公式:因为
g
I
1
g_{I_1}
gI1和
g
I
2
g_{I_2}
gI2的差是绝对值而不是相对值,与其本身相比差值可能太小。因此增强和体现权重差异,使用一个正值超参数C来缩放
g
I
1
g_{I_1}
gI1和
g
I
2
g_{I_2}
gI2,从而得到更好的权重分配。故
ω
1
\omega_1
ω1和
ω
2
\omega_2
ω2计算公式为:
使用softmax函数使值为0至1的实数,并保证
ω
1
\omega_1
ω1和
ω
2
\omega_2
ω2和为1。
3.2 损失函数
- 损失函数定义

θ \theta θ代表DenseNet的参数,D是训练数据集。上式第一项为融合结果和源图像的相似性损失,第二项用于持续学习,下节介绍。 λ \lambda λ是控制权衡的超参数。 -
L
s
i
m
(
θ
,
D
)
\mathcal L_{sim}(\theta,D)
Lsim(θ,D)的组成
①相似性约束有两个方面:结构相似性和强度分布。
②结构相似性指标测度(structural similarity index measure ,SSIM)由光线、对比度和结构等信息的相似度计算得出。本文使用SSIM约束 I 1 I_1 I1、 I 2 I_2 I2、 I f I_f If之间的结构相似度。使用 ω 1 \omega_1 ω1和 ω 2 \omega_2 ω2控制信息度。
S x , y \ S_{x, y} Sx,y代表两张图像的SSIM值。
③SSIM关注对比度和结构的变换,对强度分布的差异约束较弱。因此使用均方误差MSE作为补充:

3.3基于弹性权重合并(Elastic Weight Consolidation, EWC)的多融合任务单模型
-
可行性
①不同融合任务通常会导致特征提取或融合的差异,这一点可以从相同DenseNet网络结构但是不同的参数可以看出
②一些参数是冗余的,所以模型的利用率可以大大提升。
③所以使用统一的参数训练单个模型应对多个任务是可行的。 -
实现方法
①有两种实现方法:【联合训练】、【顺序训练】。如图6所示。
②联合训练:在整个训练过程中保存所有训练数据。在每个batch中,不同任务的数据随机被选取用于训练,但是随着任务数增多会产生两个问题:- 总是保留之前任务的训练数据导致的【存储问题】
- 使用所有数据训练导致的【计算问题】
③顺序训练:对于不同的任务使用相应的数据。解决了存储问题和计算问题。但是出现了一个新问题:【灾难性遗忘】,即网络参数会被优化以解决新任务,而忘记之前的旧任务。
④为了解决这个问题,提出了【弹性权重联合(elastic weight consolidation, EWC)】算法
-
EWC损失函数
①在EWC中,当前任务 θ \theta θ的权值和之前任务 θ ∗ \theta^* θ∗的权值的平方距离根据其相应的重要性加权。
②重要的参数给予更高的权重用来阻止从旧任务学习到的内容被遗忘,不重要的参数可以在更大程度上被修改用来学习新任务。通过这个方法,模型可以根据EWC持续学习。其损失函数为:
i代表了网络的第i个参数, μ i \mu_i μi表示相应平方距离的权重
①为了评估重要性,
μ
i
\mu_i
μi被赋值为Fisher信息矩阵的对角项,并根据计算梯度平方来逼近之前任务的数据。
D
∗
D^*
D∗代表先前任务的数据,
l
o
g
p
(
D
∗
∣
θ
∗
)
log \mathcal p(D^*|\theta^*)
logp(D∗∣θ∗)可以由
−
L
(
θ
∗
,
D
∗
)
-\mathcal L(\theta^*, D^*)
−L(θ∗,D∗)近似代替。因此上式可以写为:
②因为可以在丢弃旧数据
D
∗
D^*
D∗之前计算Fisher信息矩阵,因此训练当前任务时模型不需要
D
∗
D^*
D∗
③如果有多个先前任务存在,那么
L
e
w
c
(
θ
,
D
)
\mathcal L_{ewc}(\theta,D)
Lewc(θ,D)根据具体任务和相应数据自适应调整。然后对这些梯度的平方求均值得到最终的
μ
i
\mu_i
μi。如图7所示。
5.
①在多任务图像融合中,
θ
\theta
θ为DenseNet的参数。
②首先,通过最小化公式6中的损失函数来训练DenseNet以解决任务1,即多模态图像融合问题。再增加求解任务2,即多曝光图像融合问题时,首先计算重要相关权重
μ
i
\mu_i
μi。
μ
i
\mu_i
μi表示DenseNet中各参数对多模态图像融合的重要性。
③然后,通过最小化公式3中的
L
e
w
c
\mathcal L_{ewc}
Lewc来使重要参数被固化,从而避免灾难性遗忘。
④通过最小化相似性损失
L
s
i
m
\mathcal L_{sim}
Lsim,更新不重要的权重,来解决多曝光图像融合任务。
⑤最后,训练多聚焦图像融合时,根据前两个任务计算
μ
i
\mu_i
μi,ewc策略与之前一样。
⑥通过这个方法,EWC可以根据多任务自适应图像融合的场景来改变。
3.4 网络结构
- 网络结构
①使用 I 1 I_1 I1和 I 2 I_2 I2拼接(concat)输入DenseNet生成融合图像 I f I_f If。因此是一个不需要设计融合规则的端到端模型。如图8所示。
②在卷积前使用反射填充减少边界伪影,为避免信息损失没有池化层。
- 密集连接CNN
①实验证明,如果在接近输入和输出层的地方加入跳接,CNN可以被训练的更好。因此在前7层使用了密集连接CNN。
②意义:- 减少梯度消失
- 减少参数的同时,增强特征传播
3.5 处理RGB输入
①RGB被转换为YCrCb。使用Y(亮度)通道进行融合,因为结构细节和亮度变换在此通道更明显。
②Cb和Cr中的数据使用传统方法融合,如下式:
C
1
C_1
C1和
C
2
C_2
C2分别代表图像1和图像2的
C
b
Cb
Cb或
C
r
Cr
Cr通道值。
C
f
C_f
Cf为融合结果对应的通道。
(这块没太看明白,原文:Data in the Cb and Cr (chrominance) channels are fused traditionally as 上式,where C1 and C2 are the Cb/Cr channel values of the first and second source image, respectively. Cf is the corresponding channel of the fusion result.)
(应该是在Cb通道时,C1为图像1的Cb,C2为图像2的Cb,然后融合结果Cf就是融合图像的Cb。在Cr通道时,C1为图像1的Cr,C2为图像2的Cr,融合结果为融合图像的Cr。🚀不知道理解对不对,评论区可以讨论一下)
τ
\tau
τ被设置为128。
③通过逆变换,融合图像可以被转换到RGB空间。因此,所有的任务统一为单通道图像融合任务。
RGB2YCbCr参考连接
3.6 处理多输入
对源图像顺序融合,然后将中间结果与下一张源图像融合。如此操作理论上可以处理任意多的输入源图像。如图9和图10所示。

4 实验结果与解释
本节通过定性定量分析,与其他最先进的算法分别在多任务和多数据集上做了对比试验。
4.1 训练设置细节
1.数据集
①U2Fusion三个任务:多模态图像融合(可见光-红外,医学(PET-MRI))、多曝光、多聚焦
②训练数据集:
- 任务1:RoadScene(红外-可见光)、Harvard(PET-MRI)
- 任务2:SICE(多曝光)
- 任务3:Lytro(多聚焦)
③测试数据集:
TNO(红外-可见光)
EMPA HDR(多曝光)
- RoadScene
在FLIR Video的基础上,发布了对齐的红外与可见光数据集RoadScene,共有221对对齐的图像对。 - 其他细节
训练图像被裁剪为64*64,多聚焦图像不足,所以采用了放大、翻转来进行数据增强。
α = 20 \alpha=20 α=20, λ = 8 e 4 f \lambda=8e4f λ=8e4f, c = 3 e 3 , 3.5 e 3 , 1 e 2 c=3e3,3.5e3,1e2 c=3e3,3.5e3,1e2
4.2 多模态图像融合
4.2.1 可见光与红外图像融合

4.2.2 医学图像融合

4.3 多曝光图像融合

4.4 多聚焦图像融合

5 消融实验
5.1 EWC消融实验

5.2 不同任务之间相互促进的统一模型

5.3 自适应信息保持度的消融研究

5.4 Effect of Training Order

5.5 U2Fusion与FusionDN

6 结论
①提出了统一无监督端到端的图像融合网络U2Fusion,该模型使用自适应信息保存度作为源图像中所包含信息的度量,并以此保持融合结果和源图像之间自适应的相似性。(即不再是最大化相似度,而是自适应相似度)
②使用EWC解决了持续学习中灾难性遗忘的问题,使统一参数的模型可以应对多任务
③发布了RoadScene
🚀传送门
📑图像融合相关论文阅读笔记
📑[FusionGAN: A generative adversarial network for infrared and visible image fusion]
📑[PIAFusion: A progressive infrared and visible image fusion network based on illumination aw]
📑[Visible and Infrared Image Fusion Using Deep Learning]
📑[CDDFuse: Correlation-Driven Dual-Branch Feature Decomposition for Multi-Modality Image Fusion]
📑[U2Fusion: A Unified Unsupervised Image Fusion Network]
📚图像融合论文baseline总结
📚[图像融合论文baseline及其网络模型]
📑其他论文
[3D目标检测综述:Multi-Modal 3D Object Detection in Autonomous Driving:A Survey]
🎈其他总结
🎈[CVPR2023、ICCV2023论文题目汇总及词频统计]
✨精品文章总结
✨[图像融合论文及代码整理最全大合集]
✨[图像融合常用数据集整理]文章来源:https://www.toymoban.com/news/detail-799158.html
如有疑问可联系:420269520@qq.com;
码字不易,【关注,收藏,点赞】一键三连是我持续更新的动力,祝各位早发paper,顺利毕业~文章来源地址https://www.toymoban.com/news/detail-799158.html
到了这里,关于图像融合论文阅读:U2Fusion: A Unified Unsupervised Image Fusion Network的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!