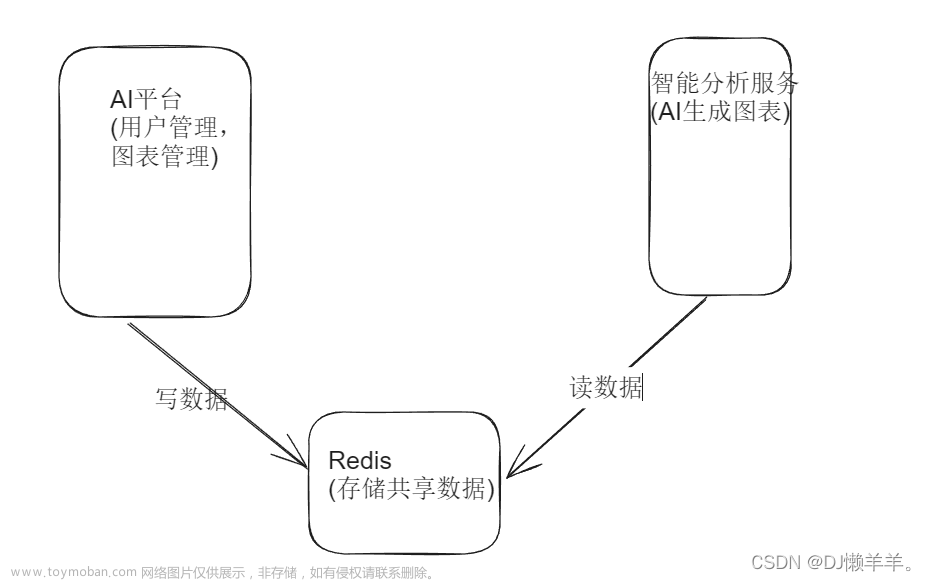
通过搭建集群保证高可用
RabbitMQ的集群模式:
普通集群,镜像集群(开发时用的多),仲裁集群
普通集群(标准集群)会在各个节点间共享部分数据(交换机和队列元信息),但不包含队列里的消息;如果队列不在该节点,会从数据所在节点传递到当前节点并返回;当所在节点宕机,队列中的消息就会丢失。
镜像集群:本质是主从模式。
镜像集群特征如下:
交换机、队列、队列中的消息会在各个MQ的镜像节点之间同步备份。
创建队列的节点称为该队列的主节点,备份的其他节点叫该队列的镜像节点。
一个队列的主节点可能是另一个队列的镜像节点。
所有操作丢失主节点完成,然后同步给镜像节点(不然数据不就不一致了吗)
主节点宕机后,镜像节点会替代它成为新的主节点。保证了高可用性
数据还没有同步完成,主节点宕机了,就会造成数据丢失。所以采用仲裁队列。
仲裁集群:文章来源:https://www.toymoban.com/news/detail-799167.html
主从同步采用的Raft协议,强一致性。文章来源地址https://www.toymoban.com/news/detail-799167.html
到了这里,关于RabbitMQ的高可用机制的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!