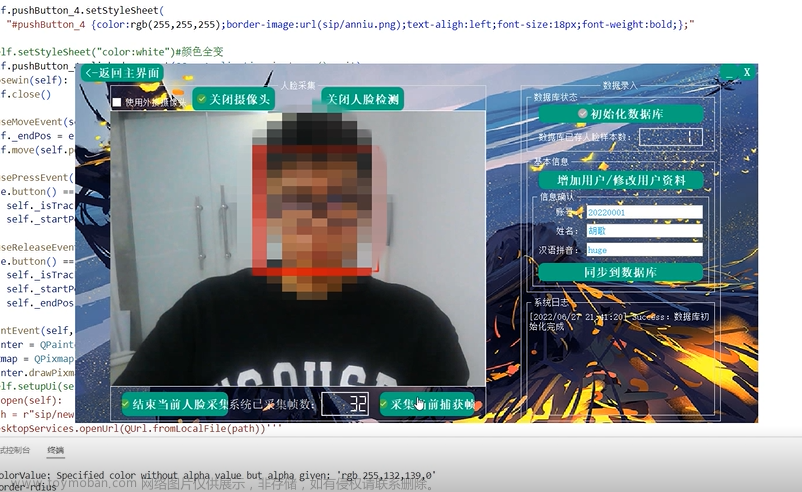
人脸识别
OpenCV 中的人脸识别通常基于哈尔特征分类器(Haar Cascade Classifier)进行。以下是 OpenCV 人脸识别的基本原理:
-
Haar Cascade Classifier:
- 特征分类器:Haar 特征是一种基于矩形区域的特征,可以用于图像中的对象检测。这些特征可以表示边缘、线和区域的变化等。
- 级联分类器:Haar 级联分类器是由大量的弱分类器组成的级联结构,每个弱分类器用于检测图像的一个特定特征。级联分类器能够快速排除非目标区域,提高效率。
-
训练分类器:
- Haar 分类器需要经过训练,使用正样本(包含人脸的图像)和负样本(不包含人脸的图像)进行训练。OpenCV 提供了工具来训练这些分类器。
-
人脸检测过程:
- 图像灰度化:首先,图像被转换为灰度图像,简化处理。
- 级联分类器应用:Haar 分类器通过图像的不同区域以固定的步长和缩放应用。在每个区域,级联分类器检测是否有人脸特征。
- 人脸候选区域:检测到的候选区域被保留,其中可能包含人脸。
- 非极大值抑制:对于重叠的候选区域,采用非极大值抑制,选择最具代表性的人脸区域。
-
人脸识别:
- 识别是通过使用预训练的人脸识别模型进行的。在检测到人脸的区域中,可以使用各种方法(如基于模板的匹配或深度学习模型)进行人脸识别。
首先安装依赖
pip install opencv-python
pip install opencv-contrib-python
pip install numpy
pip install pillow
拍照采集人脸
cv2.ideoCapture(0)的0是默认摄像头,如果外置摄像头可以换其他数字试试,这段代码其实就是通过opencv来拍照并保存用于后面的数据训练。
# 导入模块
import cv2
# 摄像头
cap = cv2.VideoCapture(0)
flag = 1
num = 1
while cap.isOpened():
ret, frame = cap.read()
cv2.imshow('frame', frame)
k = cv2.waitKey(1) & 0xFF
if k == ord('s'): # 按下s键,保存图片
cv2.imwrite('./images/faces/name/{}.jpg'.format(num), frame)
print('{}.jpg saved'.format(num))
num += 1
elif k == ord(' '): # 按下空格键退出
break
cap.release() # 释放摄像头
cv2.destroyAllWindows() # 关闭窗口
数据训练
haarcascade_frontalface_default.xml需要下载opencv的源码文件来获取。
下载地址:Releases - OpenCV
主要通过getImageAndLabel来解析对应图片的特征值保存到face_trainer.yml中用于后期的人脸检测。在/images/faces的文件夹下的路径应该是id.人名拼音/图片文件,用id来关联人脸名称,必须是整型数字,图片名称没有要求,最好给识别人物的照片多准备一些,识别效果会好一些。
import os
import cv2
from PIL import Image
import numpy as np
def getImageAndLabel(path):
# 人脸数据路径
faceSamples = []
# id
ids = []
# 获取当前路径的文件夹
dirs = os.listdir(path)
# 加载分类器
faceCascade = cv2.CascadeClassifier('./data/haarcascades/haarcascade_frontalface_default.xml')
# 遍历文件夹
for dir in dirs:
# 获取文件夹路径
dir_path = os.path.join(path, dir)
# 获取文件夹下的图片
imagePaths = [os.path.join(dir_path, f) for f in os.listdir(dir_path)]
# 获取id
id = int(dir.split('.')[0])
# 遍历图片
for imagePath in imagePaths:
# 转换为灰度图
PIL_img = Image.open(imagePath).convert('L')
# 转换为数组
img_numpy = np.array(PIL_img, 'uint8')
# 人脸检测
faces = faceCascade.detectMultiScale(img_numpy)
# 遍历人脸
for (x, y, w, h) in faces:
# 添加人脸数据
faceSamples.append(img_numpy[y:y + h, x:x + w])
# 添加id
ids.append(id)
# 返回人脸数据和id
return faceSamples, ids
if __name__ == '__main__':
# 获取人脸数据和姓名
faces, ids = getImageAndLabel('./images/faces')
# 导入人脸识别模型
recognizer = cv2.face.LBPHFaceRecognizer_create()
# 训练模型
recognizer.train(faces, np.array(ids))
# 保存模型
recognizer.save('./data/face_trainer.yml')
人脸识别
可以通过图片,视频,摄像头来进行人脸检测,识别成功后会返回id,根据id索引来对应人物名称。多次识别失败后会触发警报,这里没有对应的通报代码,可以自行添加。
由于中文无法直接通过opencv添加,所以这里使用cv2ImgAddText将文字转为图片后加到原图上。文章来源:https://www.toymoban.com/news/detail-799268.html
# -*- coding: utf-8 -*-
import cv2
import numpy as np
from PIL import ImageFont, ImageDraw, Image
import ffmpeg
import threading
import time
import subprocess
# 加载分类器
recognizer = cv2.face.LBPHFaceRecognizer_create()
# 读取训练数据
recognizer.read('./data/face_trainer.yml')
# 名称
names = ['未知', '刘德华', '成龙', '胡歌', '刘亦菲']
# 警报全局变量
warningtime = 0
# 设置字体相关参数
font_path = './data/font/simfang.ttf'
def cv2ImgAddText(img, text, left, top, textColor=(0, 0, 255), textSize=20):
"""
文字转换为图片并添加到图片上
"""
if (isinstance(img, np.ndarray)): # 判断是否OpenCV图片类型
img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
# 创建一个可以在给定图像上绘图的对象
draw = ImageDraw.Draw(img)
# 字体的格式
fontStyle = ImageFont.truetype(
font_path, textSize, encoding="utf-8")
# 绘制文本
draw.text((left, top), text, textColor, font=fontStyle)
# 转换回OpenCV格式
return cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGR)
# 人脸检测
def detect_face(src_img):
# 导入人脸检测模型
face_cascade = cv2.CascadeClassifier('./data/haarcascades/haarcascade_frontalface_alt2.xml')
# 灰度转换
gray = cv2.cvtColor(src_img, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray) # 灰度图像,缩放因子,最小邻域,最大邻域,最小尺寸,最大尺寸
# 绘制人脸矩形
for (x, y, w, h) in faces:
cv2.rectangle(src_img, (x, y), (x + w, y + h), (0, 0, 255), 2) # 图片,左上角坐标,右下角坐标,颜色,线宽
# 人脸识别
id, confidence = recognizer.predict(gray[y:y + h, x:x + w])
print(id)
# 判断是否为本人
if confidence < 70:
name = names[id]
confidence = "{0}%".format(round(100 - confidence))
else:
name = "unknown"
confidence = "{0}%".format(round(100 - confidence))
# 绘制姓名
src_img = cv2ImgAddText(src_img, name, x + 5, y + 5, (255, 0, 0), 50)
print(name)
# 绘制置信度
src_img = cv2ImgAddText(src_img, confidence, x + 5, y + h - 30, (255, 0, 0), 50)
# 判断是否为本人
if name == "unknown":
# 警报
global warningtime
warningtime += 1
# 警报超过3次
if warningtime > 3:
# 发送邮件
# sendEmail()
print("警报")
# 重置警报次数
warningtime = 0
return src_img
# 关闭
if __name__ == '__main__':
# 读取摄像头
cap = cv2.VideoCapture(0) # 0代表默认摄像头编号,如果有多个摄像头,可以尝试1,2,3等等
# cap = cv.VideoCapture("./images/video.mp4")#读取视频文件
# cap = cv2.VideoCapture('rtmp://') # 读取视频流
cap.set(cv2.CAP_PROP_FPS, 30) # 设置帧率
cap.set(cv2.CAP_PROP_BUFFERSIZE, 1) # 设置缓冲区大小为1,你可以根据需要调整
# 人脸检测
while True:
ret, frame = cap.read()
if ret:
img = detect_face(frame)
# 显示图片
cv2.imshow("img", img)
time.sleep(0.1)
# 等待键盘输入
if cv2.waitKey(1) == ord('q'):
break
# 释放资源
cap.release()
cv2.destroyAllWindows()
# # 读取图片
# img = cv2.imread("./images/img_5.png")
# img = detect_face(img) # # 修改图片大小
# img = cv2.resize(img, (800, 600))
# cv2.imshow("face_detect", img)
# cv2.waitKey(0)
# cv2.destroyAllWindows()

上面内容已经包含全部需要代码和需要资源获取方法,但如果需要也可以通过这个地址获取完整代码和资源:
csdn资源地址文章来源地址https://www.toymoban.com/news/detail-799268.html
到了这里,关于【opencv】python实现人脸检测和识别训练的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!