在没有过拟合的情况下,相同模型结构下,一般模型的参数量和计算量与最终的性能成正比,在比较不同模型性能时,最好能保持模型参数量和计算量在相同水平下,因此相应参数的统计很重要。这里只进行理论计算,最终的效果(内存和速度)还和网络结构,代码实现方式、应用的平台性能等条件有关系,例如使用GEMM实现CNN时会增加内存,但实际的计算速度会加快。相同条件下,GRU由于时序依赖关系不能并行加速,实际速度会比CNN更慢。
1. 指标
1. 1 Parameters(参数量)
参数量一般指模型的可训练的参数个数,参数量和内存成正比。
1.2 计算量
衡量计算量的指标比较多,用来衡量模型的运行速度。
1.2.1 FLOPs
FLOPs(Floating Point Operations)浮点运算次数
1.2.2 MACs
MACs(Multiply–Accumulate Operations) 乘加累积次数,1MACs等于1个乘法和1个加法
1.2.3 MAC
MAC(Memory access Cost)内存访问成本
2 .理论计算
2.1 Parameters 和 Flops
- FLOPS: 注意全大写,是
floating point operations per second的缩写,意指每秒浮点运算次数,理解为计算速度。是一个衡量硬件性能的指标。计算公式:
对卷积层:(K_h * K_w * C_in * C_out) * (H_out * W_out)
对全连接层:C_in * C_out
- FLOPs:
注意s小写,是floating point operations的缩写(s表复数),意指浮点运算数,理解为计算量。可以用来衡量算法/模型的复杂度
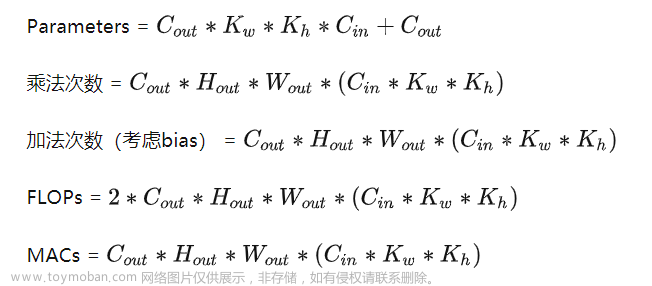
注意:
- 1.params只与你定义的网络结构有关,和forward的任何操作无关。即定义好了网络结构,参数就已经决定了。FLOPs和不同的层运算结构有关。如果forward时在同一层(同一名字命名的层)多次运算,FLOPs不会增加
- 2.
Model_size = 4*params模型大小约为参数量的4倍
2.2 MAC

3 . 代码实现
3.1 Parameters 和 Flops计算
方法1-使用torchsummary库
- 首先申明一个网络
model = torchvision.models.vgg16()
device = torch.device('cpu')
model.to(device)
- pip安装库
pip install torchsummary
- 使用torchsummary可以查看模型的参数和输入输出尺寸,但不能看Flops
import torchsummary
torchsummary.summary(model.cpu(),(3,224,224))
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 224, 224] 1,792
ReLU-2 [-1, 64, 224, 224] 0
Conv2d-3 [-1, 64, 224, 224] 36,928
ReLU-4 [-1, 64, 224, 224] 0
MaxPool2d-5 [-1, 64, 112, 112] 0
Conv2d-6 [-1, 128, 112, 112] 73,856
ReLU-7 [-1, 128, 112, 112] 0
Conv2d-8 [-1, 128, 112, 112] 147,584
ReLU-9 [-1, 128, 112, 112] 0
MaxPool2d-10 [-1, 128, 56, 56] 0
Conv2d-11 [-1, 256, 56, 56] 295,168
ReLU-12 [-1, 256, 56, 56] 0
Conv2d-13 [-1, 256, 56, 56] 590,080
ReLU-14 [-1, 256, 56, 56] 0
Conv2d-15 [-1, 256, 56, 56] 590,080
ReLU-16 [-1, 256, 56, 56] 0
MaxPool2d-17 [-1, 256, 28, 28] 0
Conv2d-18 [-1, 512, 28, 28] 1,180,160
ReLU-19 [-1, 512, 28, 28] 0
Conv2d-20 [-1, 512, 28, 28] 2,359,808
ReLU-21 [-1, 512, 28, 28] 0
Conv2d-22 [-1, 512, 28, 28] 2,359,808
ReLU-23 [-1, 512, 28, 28] 0
MaxPool2d-24 [-1, 512, 14, 14] 0
Conv2d-25 [-1, 512, 14, 14] 2,359,808
ReLU-26 [-1, 512, 14, 14] 0
Conv2d-27 [-1, 512, 14, 14] 2,359,808
ReLU-28 [-1, 512, 14, 14] 0
Conv2d-29 [-1, 512, 14, 14] 2,359,808
ReLU-30 [-1, 512, 14, 14] 0
MaxPool2d-31 [-1, 512, 7, 7] 0
AdaptiveAvgPool2d-32 [-1, 512, 7, 7] 0
Linear-33 [-1, 4096] 102,764,544
ReLU-34 [-1, 4096] 0
Dropout-35 [-1, 4096] 0
Linear-36 [-1, 4096] 16,781,312
ReLU-37 [-1, 4096] 0
Dropout-38 [-1, 4096] 0
Linear-39 [-1, 1000] 4,097,000
================================================================
Total params: 138,357,544
Trainable params: 138,357,544
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 218.78
Params size (MB): 527.79
Estimated Total Size (MB): 747.15
----------------------------------------------------------------
方法2-使用thop库
- 安装库
pip install thop
- 使用thop可以显示总的FLOPs和总参数量params,但不能显示每层的结构
import torchvision
import torch
from thop import profile
from thop import clever_format
model = torchvision.models.vgg16()
device = torch.device('cpu')
model.to(device)
myinput = torch.zeros((1,3,224,224)).to(device)
flops,params = profile(model.to(device),inputs=(myinput,))
flops,params = clever_format([flops,params],"%.3f")
print(flops,params)

方法2-使用torchstat库
在PyTorch中,可以使用torchstat这个库来查看网络模型的一些信息,包括总的参数量params、MAdd、显卡内存占用量和FLOPs等
- 安装库
pip install torchstat
from torchstat import stat
from torchvision.models import resnet50
model = resnet50()
stat(model, (3, 224, 224))
module name input shape output shape params memory(MB) MAdd Flops MemRead(B) MemWrite(B) duration[%] MemR+W(B)
0 conv1 3 224 224 64 112 112 9408.0 3.06 235,225,088.0 118,013,952.0 639744.0 3211264.0 2.64% 3851008.0
1 bn1 64 112 112 64 112 112 128.0 3.06 3,211,264.0 1,605,632.0 3211776.0 3211264.0 2.37% 6423040.0
2 relu 64 112 112 64 112 112 0.0 3.06 802,816.0 802,816.0 3211264.0 3211264.0 0.26% 6422528.0
3 maxpool 64 112 112 64 56 56 0.0 0.77 1,605,632.0 802,816.0 3211264.0 802816.0 1.58% 4014080.0
4 layer1.0.conv1 64 56 56 64 56 56 4096.0 0.77 25,489,408.0 12,845,056.0 819200.0 802816.0 1.32% 1622016.0
5 layer1.0.bn1 64 56 56 64 56 56 128.0 0.77 802,816.0 401,408.0 803328.0 802816.0 0.00% 1606144.0
6 layer1.0.conv2 64 56 56 64 56 56 36864.0 0.77 231,010,304.0 115,605,504.0 950272.0 802816.0 0 0.77 200,704.0 200,704.0 802816.0 802816.0 0.26% 1605632.0
...
...
124 avgpool 2048 7 7 2048 1 1 0.0 0.01 0.0 0.0 0.0 0.0 1.58% 0.0
125 fc 2048 1000 2049000.0 0.00 4,095,000.0 2,048,000.0 8204192.0 4000.0 0.26% 8208192.0
total 25557032.0 109.69 8,219,637,272.0 4,118,537,216.0 8204192.0 4000.0 100.00% 332849216.0
===================================================================================================================================================================
Total params: 25,557,032
-------------------------------------------------------------------------------------------------------------------------------------------------------------------
Total memory: 109.69MB
Total MAdd: 8.22GMAdd
Total Flops: 4.12GFlops
Total MemR+W: 317.43MB
比较推荐优先使用这个工具
方法3-使用 ptflops
ptflops:https://github.com/sovrasov/flops-counter.pytorch
#pip install ptflops
from ptflops import get_model_complexity_info
from torchvision.models import resnet50
model = resnet50()
flops, params = get_model_complexity_info(model, (3, 224, 224), as_strings=True, print_per_layer_stat=True)
print('Flops: ' + flops)
print('Params: ' + params)
ResNet(
25.56 M, 100.000% Params, 4.12 GMac, 100.000% MACs,
(conv1): Conv2d(9.41 k, 0.037% Params, 118.01 MMac, 2.863% MACs, 3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(128, 0.001% Params, 1.61 MMac, 0.039% MACs, 64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(0, 0.000% Params, 802.82 KMac, 0.019% MACs, inplace=True)
(maxpool): MaxPool2d(0, 0.000% Params, 802.82 KMac, 0.019% MACs, kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
215.81 k, 0.844% Params, 680.39 MMac, 16.507% MACs,
(0): Bottleneck(
75.01 k, 0.293% Params, 236.43 MMac, 5.736% MACs,
(conv1): Conv2d(4.1 k, 0.016% Params, 12.85 MMac, 0.312% MACs, 64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, 0.001% Params, 401.41 KMac, 0.010% MACs, 64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(36.86 k, 0.144% Params, 115.61 MMac, 2.805% MACs, 64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, 0.001% Params, 401.41 KMac, 0.010% MACs, 64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(16.38 k, 0.064% Params, 51.38 MMac, 1.247% MACs, 64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, 0.002% Params, 1.61 MMac, 0.039% MACs, 256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(0, 0.000% Params, 1.2 MMac, 0.029% MACs, inplace=True)
(downsample): Sequential(
16.9 k, 0.066% Params, 52.99 MMac, 1.285% MACs,
(0): Conv2d(16.38 k, 0.064% Params, 51.38 MMac, 1.247% MACs, 64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(512, 0.002% Params, 1.61 MMac, 0.039% MACs, 256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
70.4 k, 0.275% Params, 221.98 MMac, 5.385% MACs,
(conv1): Conv2d(16.38 k, 0.064% Params, 51.38 MMac, 1.247% MACs, 256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, 0.001% Params, 401.41 KMac, 0.010% MACs, 64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(36.86 k, 0.144% Params, 115.61 MMac, 2.805% MACs, 64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, 0.001% Params, 401.41 KMac, 0.010% MACs, 64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(16.38 k, 0.064% Params, 51.38 MMac, 1.247% MACs, 64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, 0.002% Params, 1.61 MMac, 0.039% MACs, 256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(0, 0.000% Params, 1.2 MMac, 0.029% MACs, inplace=True)
)
....
...
(3): Bottleneck(
280.06 k, 1.096% Params, 220.17 MMac, 5.341% MACs,
(conv1): Conv2d(65.54 k, 0.256% Params, 51.38 MMac, 1.247% MACs, 512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, 0.001% Params, 200.7 KMac, 0.005% MACs, 128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(147.46 k, 0.577% Params, 115.61 MMac, 2.805% MACs, 128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, 0.001% Params, 200.7 KMac, 0.005% MACs, 128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(65.54 k, 0.256% Params, 51.38 MMac, 1.247% MACs, 128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1.02 k, 0.004% Params, 802.82 KMac, 0.019% MACs, 512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(0, 0.000% Params, 602.11 KMac, 0.015% MACs, inplace=True)
)
)
(layer3): Sequential(
7.1 M, 27.775% Params, 1.47 GMac, 35.678% MACs,
(0): Bottleneck(
1.51 M, 5.918% Params, 374.26 MMac, 9.080% MACs,
(conv1): Conv2d(131.07 k, 0.513% Params, 102.76 MMac, 2.493% MACs, 512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, 0.002% Params, 401.41 KMac, 0.010% MACs, 256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(589.82 k, 2.308% Params, 115.61 MMac, 2.805% MACs, 256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, 0.002% Params, 100.35 KMac, 0.002% MACs, 256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(262.14 k, 1.026% Params, 51.38 MMac, 1.247% MACs, 256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2.05 k, 0.008% Params, 401.41 KMac, 0.010% MACs, 1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(0, 0.000% Params, 451.58 KMac, 0.011% MACs, inplace=True)
(downsample): Sequential(
526.34 k, 2.059% Params, 103.16 MMac, 2.503% MACs,
(0): Conv2d(524.29 k, 2.051% Params, 102.76 MMac, 2.493% MACs, 512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(2.05 k, 0.008% Params, 401.41 KMac, 0.010% MACs, 1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
...
...
(1): Bottleneck(
1.12 M, 4.371% Params, 219.27 MMac, 5.320% MACs,
(conv1): Conv2d(262.14 k, 1.026% Params, 51.38 MMac, 1.247% MACs, 1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, 0.002% Params, 100.35 KMac, 0.002% MACs, 256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(589.82 k, 2.308% Params, 115.61 MMac, 2.805% MACs, 256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, 0.002% Params, 100.35 KMac, 0.002% MACs, 256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(262.14 k, 1.026% Params, 51.38 MMac, 1.247% MACs, 256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2.05 k, 0.008% Params, 401.41 KMac, 0.010% MACs, 1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(0, 0.000% Params, 301.06 KMac, 0.007% MACs, inplace=True)
)
(2): Bottleneck(
1.12 M, 4.371% Params, 219.27 MMac, 5.320% MACs,
(conv1): Conv2d(262.14 k, 1.026% Params, 51.38 MMac, 1.247% MACs, 1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, 0.002% Params, 100.35 KMac, 0.002% MACs, 256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(589.82 k, 2.308% Params, 115.61 MMac, 2.805% MACs, 256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, 0.002% Params, 100.35 KMac, 0.002% MACs, 256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(262.14 k, 1.026% Params, 51.38 MMac, 1.247% MACs, 256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2.05 k, 0.008% Params, 401.41 KMac, 0.010% MACs, 1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(0, 0.000% Params, 301.06 KMac, 0.007% MACs, inplace=True)
)
(4): Bottleneck(
1.12 M, 4.371% Params, 219.27 MMac, 5.320% MACs,
(conv1): Conv2d(262.14 k, 1.026% Params, 51.38 MMac, 1.247% MACs, 1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, 0.002% Params, 100.35 KMac, 0.002% MACs, 256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(589.82 k, 2.308% Params, 115.61 MMac, 2.805% MACs, 256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, 0.002% Params, 100.35 KMac, 0.002% MACs, 256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(262.14 k, 1.026% Params, 51.38 MMac, 1.247% MACs, 256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2.05 k, 0.008% Params, 401.41 KMac, 0.010% MACs, 1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(0, 0.000% Params, 301.06 KMac, 0.007% MACs, inplace=True)
)
(conv2): Conv2d(2.36 M, 9.231% Params, 115.61 MMac, 2.805% MACs, 512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(1.02 k, 0.004% Params, 50.18 KMac, 0.001% MACs, 512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(1.05 M, 4.103% Params, 51.38 MMac, 1.247% MACs, 512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(4.1 k, 0.016% Params, 200.7 KMac, 0.005% MACs, 2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(0, 0.000% Params, 150.53 KMac, 0.004% MACs, inplace=True)
)
(avgpool): AdaptiveAvgPool2d(0, 0.000% Params, 100.35 KMac, 0.002% MACs, output_size=(1, 1))
(fc): Linear(2.05 M, 8.017% Params, 2.05 MMac, 0.050% MACs, in_features=2048, out_features=1000, bias=True)
)
Flops: 4.12 GMac
方法4-使用 fvcore
fvcore是Facebook开源的一个轻量级的核心库,它提供了各种计算机视觉框架中常见且基本的功能。其中就包括了统计模型的参数以及FLOPs等。
项目开源地址:
https://github.com/facebookresearch/fvcore
在python环境中安装fvcore
pip install fvcore
示例:
假设我需要计算以下resnet50的参数数量以及FLOPs参数。
import torch
from torchvision.models import resnet50
from fvcore.nn import FlopCountAnalysis, parameter_count_table
# 创建resnet50网络
model = resnet50(num_classes=1000)
# 创建输入网络的tensor
tensor = (torch.rand(1, 3, 224, 224),)
# 分析FLOPs
flops = FlopCountAnalysis(model, tensor)
print("FLOPs: ", flops.total())
# 分析parameters
print(parameter_count_table(model))
终端输出结果如下,FLOPs为4089184256,模型参数数量约为25.6M(这里的参数数量和我自己计算的有些出入,主要是在BN模块中,这里只计算了beta和gamma两个训练参数,没有统计moving_mean和moving_var两个参数),具体可以看下我在官方提的issue。
通过终端打印的信息我们可以发现在计算FLOPs时并没有包含BN层,池化层还有普通的add操作(我发现计算FLOPs时并没有统一的规定,在github上看的计算FLOPs项目基本每个都不同,但计算出来的结果大同小异)。
Skipped operation aten::batch_norm 53 time(s)
Skipped operation aten::max_pool2d 1 time(s)
Skipped operation aten::add_ 16 time(s)
Skipped operation aten::adaptive_avg_pool2d 1 time(s)
FLOPs: 4089184256
| name | #elements or shape |
|:-----------------------|:---------------------|
| model | 25.6M |
| conv1 | 9.4K |
| conv1.weight | (64, 3, 7, 7) |
| bn1 | 0.1K |
| bn1.weight | (64,) |
| bn1.bias | (64,) |
| layer1 | 0.2M |
| layer1.0 | 75.0K |
| layer1.0.conv1 | 4.1K |
| layer1.0.bn1 | 0.1K |
| layer1.0.conv2 | 36.9K |
| layer1.0.bn2 | 0.1K |
| layer1.0.conv3 | 16.4K |
| layer1.0.bn3 | 0.5K |
| layer1.0.downsample | 16.9K |
| layer1.1 | 70.4K |
| layer1.1.conv1 | 16.4K |
| layer1.1.bn1 | 0.1K |
| layer1.1.conv2 | 36.9K |
| layer1.1.bn2 | 0.1K |
| layer1.1.conv3 | 16.4K |
| layer1.1.bn3 | 0.5K |
| layer1.2 | 70.4K |
| layer1.2.conv1 | 16.4K |
| layer1.2.bn1 | 0.1K |
| layer1.2.conv2 | 36.9K |
| layer1.2.bn2 | 0.1K |
| layer1.2.conv3 | 16.4K |
| layer1.2.bn3 | 0.5K |
| layer2 | 1.2M |
| layer2.0 | 0.4M |
| layer2.0.conv1 | 32.8K |
| layer2.0.bn1 | 0.3K |
| layer2.0.conv2 | 0.1M |
| layer2.0.bn2 | 0.3K |
| layer2.0.conv3 | 65.5K |
| layer2.0.bn3 | 1.0K |
| layer2.0.downsample | 0.1M |
| layer2.1 | 0.3M |
| layer2.1.conv1 | 65.5K |
| layer2.1.bn1 | 0.3K |
| layer2.1.conv2 | 0.1M |
| layer2.1.bn2 | 0.3K |
| layer2.1.conv3 | 65.5K |
| layer2.1.bn3 | 1.0K |
| layer2.2 | 0.3M |
| layer2.2.conv1 | 65.5K |
| layer2.2.bn1 | 0.3K |
| layer2.2.conv2 | 0.1M |
| layer2.2.bn2 | 0.3K |
| layer2.2.conv3 | 65.5K |
| layer2.2.bn3 | 1.0K |
| layer2.3 | 0.3M |
| layer2.3.conv1 | 65.5K |
| layer2.3.bn1 | 0.3K |
| layer2.3.conv2 | 0.1M |
| layer2.3.bn2 | 0.3K |
| layer2.3.conv3 | 65.5K |
| layer2.3.bn3 | 1.0K |
| layer3 | 7.1M |
| layer3.0 | 1.5M |
| layer3.0.conv1 | 0.1M |
| layer3.0.bn1 | 0.5K |
| layer3.0.conv2 | 0.6M |
| layer3.0.bn2 | 0.5K |
| layer3.0.conv3 | 0.3M |
| layer3.0.bn3 | 2.0K |
| layer3.0.downsample | 0.5M |
| layer3.1 | 1.1M |
| layer3.1.conv1 | 0.3M |
| layer3.1.bn1 | 0.5K |
| layer3.1.conv2 | 0.6M |
| layer3.1.bn2 | 0.5K |
| layer3.1.conv3 | 0.3M |
| layer3.1.bn3 | 2.0K |
| layer3.2 | 1.1M |
| layer3.2.conv1 | 0.3M |
| layer3.2.bn1 | 0.5K |
| layer3.2.conv2 | 0.6M |
| layer3.2.bn2 | 0.5K |
| layer3.2.conv3 | 0.3M |
| layer3.2.bn3 | 2.0K |
| layer3.3 | 1.1M |
| layer3.3.conv1 | 0.3M |
| layer3.3.bn1 | 0.5K |
| layer3.3.conv2 | 0.6M |
| layer3.3.bn2 | 0.5K |
| layer3.3.conv3 | 0.3M |
| layer3.3.bn3 | 2.0K |
| layer3.4 | 1.1M |
| layer3.4.conv1 | 0.3M |
| layer3.4.bn1 | 0.5K |
| layer3.4.conv2 | 0.6M |
| layer3.4.bn2 | 0.5K |
| layer3.4.conv3 | 0.3M |
| layer3.4.bn3 | 2.0K |
| layer3.5 | 1.1M |
| layer3.5.conv1 | 0.3M |
| layer3.5.bn1 | 0.5K |
| layer3.5.conv2 | 0.6M |
| layer3.5.bn2 | 0.5K |
| layer3.5.conv3 | 0.3M |
| layer3.5.bn3 | 2.0K |
| layer4 | 15.0M |
| layer4.0 | 6.0M |
| layer4.0.conv1 | 0.5M |
| layer4.0.bn1 | 1.0K |
| layer4.0.conv2 | 2.4M |
| layer4.0.bn2 | 1.0K |
| layer4.0.conv3 | 1.0M |
| layer4.0.bn3 | 4.1K |
| layer4.0.downsample | 2.1M |
| layer4.1 | 4.5M |
| layer4.1.conv1 | 1.0M |
| layer4.1.bn1 | 1.0K |
| layer4.1.conv2 | 2.4M |
| layer4.1.bn2 | 1.0K |
| layer4.1.conv3 | 1.0M |
| layer4.1.bn3 | 4.1K |
| layer4.2 | 4.5M |
| layer4.2.conv1 | 1.0M |
| layer4.2.bn1 | 1.0K |
| layer4.2.conv2 | 2.4M |
| layer4.2.bn2 | 1.0K |
| layer4.2.conv3 | 1.0M |
| layer4.2.bn3 | 4.1K |
| fc | 2.0M |
| fc.weight | (1000, 2048) |
| fc.bias | (1000,) |
Process finished with exit code 0
更多使用方法,可以去原项目中查看使用文档。
参考: https://blog.csdn.net/qq_37541097/article/details/117471650?spm=1001.2014.3001.5502
3.2 模型推理速度计算
需要克服GPU异步执行和GPU预热两个问题,下面例子使用 Efficient-net-b0,在进行任何时间测量之前,我们通过网络运行一些虚拟示例来进行“GPU 预热”。这将自动初始化 GPU 并防止它在我们测量时间时进入省电模式。接下来,我们使用 tr.cuda.event 来测量 GPU 上的时间。在这里使用 torch.cuda.synchronize() 至关重要。这行代码执行主机和设备(即GPU和CPU)之间的同步,因此只有在GPU上运行的进程完成后才会进行时间记录。这克服了不同步执行的问题。
model = EfficientNet.from_pretrained(‘efficientnet-b0’)
device = torch.device(“cuda”)
model.to(device)
dummy_input = torch.randn(1, 3, 224, 224,dtype=torch.float).to(device)
starter, ender = torch.cuda.Event(enable_timing=True), torch.cuda.Event(enable_timing=True)
repetitions = 300
timings=np.zeros((repetitions,1))
#GPU-WARM-UP
for _ in range(10):
_ = model(dummy_input)
# MEASURE PERFORMANCE
with torch.no_grad():
for rep in range(repetitions):
starter.record()
_ = model(dummy_input)
ender.record()
# WAIT FOR GPU SYNC
torch.cuda.synchronize()
curr_time = starter.elapsed_time(ender)
timings[rep] = curr_time
mean_syn = np.sum(timings) / repetitions
std_syn = np.std(timings)
mean_fps = 1000. / mean_syn
print(' * Mean@1 {mean_syn:.3f}ms Std@5 {std_syn:.3f}ms FPS@1 {mean_fps:.2f}'.format(mean_syn=mean_syn, std_syn=std_syn, mean_fps=mean_fps))
print(mean_syn)
3.3 模型吞吐量计算
神经网络的吞吐量定义为网络在单位时间内(例如,一秒)可以处理的最大输入实例数。与涉及单个实例处理的延迟不同,为了实现最大吞吐量,我们希望并行处理尽可能多的实例。有效的并行性显然依赖于数据、模型和设备。因此,为了正确测量吞吐量,我们执行以下两个步骤:(1)我们估计允许最大并行度的最佳批量大小;(2)给定这个最佳批量大小,我们测量网络在一秒钟内可以处理的实例数
要找到最佳批量大小,一个好的经验法则是达到 GPU 对给定数据类型的内存限制。这个大小当然取决于硬件类型和网络的大小。找到这个最大批量大小的最快方法是执行二进制搜索。当时间不重要时,简单的顺序搜索就足够了。为此,我们使用 for 循环将批量大小增加 1,直到达到运行时错误为止,这确定了 GPU 可以处理的最大批量大小,用于我们的神经网络模型及其处理的输入数据。
在找到最佳批量大小后,我们计算实际吞吐量。为此,我们希望处理多个批次(100 个批次就足够了),然后使用以下公式
(批次数 X 批次大小)/(以秒为单位的总时间)
这个公式给出了我们的网络可以在一秒钟内处理的示例数量。下面的代码提供了一种执行上述计算的简单方法(给定最佳批量大小)
model = EfficientNet.from_pretrained(‘efficientnet-b0’)
device = torch.device(“cuda”)
model.to(device)
dummy_input = torch.randn(optimal_batch_size, 3,224,224, dtype=torch.float).to(device)
repetitions=100
total_time = 0
with torch.no_grad():
for rep in range(repetitions):
starter, ender = torch.cuda.Event(enable_timing=True),torch.cuda.Event(enable_timing=True)
starter.record()
_ = model(dummy_input)
ender.record()
torch.cuda.synchronize()
curr_time = starter.elapsed_time(ender)/1000
total_time += curr_time
Throughput = (repetitions*optimal_batch_size)/total_time
print(‘Final Throughput:’,Throughput)
参考:
1.https://www.cnblogs.com/king-lps/p/10904552.html
2.https://blog.csdn.net/qq_29462849/article/details/121369359文章来源:https://www.toymoban.com/news/detail-799563.html
3.https://zhuanlan.zhihu.com/p/337810633
本文仅做学术分享,如有侵权,请联系删文。文章来源地址https://www.toymoban.com/news/detail-799563.html
到了这里,关于深度学习模型的参数、计算量和推理速度统计的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!