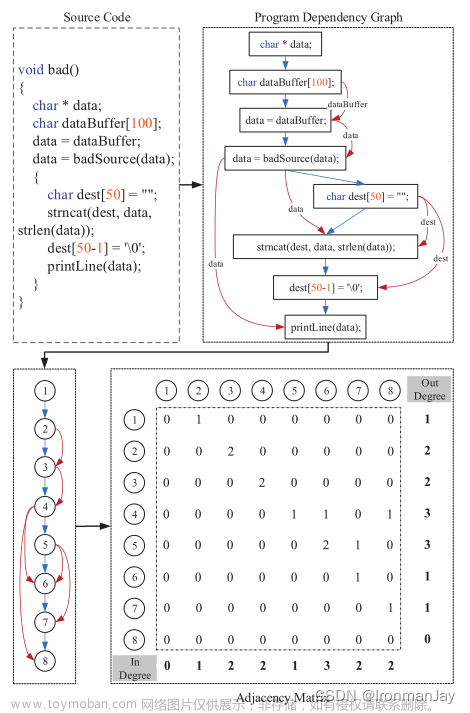
混合存储模型:
只有少量meta-data(加密哈希)存在链上,原始数据外包给链下的存储服务商
贡献
提出了一个新的ADS
1.首先提出了抑制默克尔倒置(Merkle inv)索引,该索引仅在链上维护部分 ADS 结构,可以使用对数加密证明进行安全更新。
2.提出了一个变色龙倒置(Chameleon inv)索引,它利用变色龙向量承诺来实现恒定的维护成本。它使用Bloom过滤器进一步优化,以增强查询和验证性能。
问题:
1.要支持完整性保证的数据检索
2.ADS要是更新高效的(即可以被智能合约高效维护,且计算和存储成本低)
3.GEM2-tree支持范围查询,不支持关键字查询和相似查询
4.GEM2-tree会存储很多中间数据
解决1
Merkel inv index
1.每个关键字对应一棵MBTree,这个index用来索引对应objects的ID
2.搜索时的输入是合取范式,这可以看作是每个连接组件的结果的并集
3.每个连接组件,可以作为可认证的连接查询,在查询关键字的MBTree上进行处理
带来问题:
存储操作过多,在链上智能合约维护这个index开销很大
Suppressed Merkle inv index
主要思想:智能合约只维护 Merkle inv index中每个 MB-tree 的根摘要。
因为:在可认证的关键字查询时只有链上ADS中的根摘要用到了
更新时,有新数据进来,SP发送update proof给智能合约,由可认证的信息组成,来安全计算新的根摘要
存储操作变成常数级别(贵)
内存操作变成对数级别(便宜)
Chameleon inverted (Chameleon inv) index
index的作用:恒定维护成本
CVC作用:
1.可以公开验证存储在向量中的数据。
2.数据所有者可以通过使用秘密陷门来更新向量而不改变其承诺
所以用CVC可以构建具有不变根承诺的变色龙树。
在这个index里,每个关键词是一棵Chameleon树
智能合约使用这个index的一些辅助数据维护根承诺,SP 维护完整的index以进行高效的查询处理。
两者概述:
Suppressed Merkle inv index:在智能合约维护ADS中,减少gas
Chameleon inverted (Chameleon inv) index:进一步减少ADS维护成本到一个恒定值,且仍然高效查询
问题定义

Fig.1
O object
id
{wi} 一组与object关联的关键词
v object的内容
新对象到了之后,DO发送给
SP:<id, {wj}, vi>
区块链:<id, {wj}, h(oi)>
👇
作用:保证数据完整性的同时降低了存储
SP和智能合约都维护ADS,DO调用智能合约维护链上的ADS,SP同步更新区块链上最新确认的对象
ADS的digest就是SP和智能合约共享的认证信息(authenticated information)
本文的查询:关键字查询
查询输入:单调布尔表达式Q,是DNF
用户检索得到的输出:R = {oi = <id, {wj}, vi> | Q({wj}) = true}
Q = q1 ∨ q2 ∨ · · · ∨ qn
qi = w1 ∧ w2 ∧ · · · ∧ wl
查询过程:
客户端向SP发送关键字查询请求->SP用ADS计算查询结果和验证对象VOsp
result和VOsp都发送给客户
验证过程:
客户从区块链检索认证摘要VOchain,客户通过VOchian和VOsp验证result的正确性
提出问题:
integrity
soundness
completeness
本文中研究的问题是:如何设计能够由链上智能合约有效维护的 ADS,在 gas 成本方面,同时有效地支持混合中的认证关键字搜索-存储区块链。
原文中,第 III 节中提供了一些初步信息,然后介绍了一个baseline解决方案,然后在第 IV 节和第 V 节中介绍了两种节能 ADS 方案。
基础前提
密码学原语
MHT:
1.每个叶节点是索引对象的digest
2.根哈希由DO签名并公开
3.可以用来认证数据对象的任意子集是否被存在叶节点,复杂度是对数级别
4.在关系型数据库里,已经从二叉树扩展到了多路树
Vector Commitment(VC)
1.把变长向量映射成定长的承诺
2.可以证明mi是第i个承诺信息
3.
• Gen(1λ, q):q为向量大小,输出-公共参数pp
• Compp(<m1, m2, · · · , mq>, r):<>内为有q个message的向量,输出-承诺c、辅助信息aux
• Openpp(i, m, aux):当且仅当m是向量(vector w.r.t. c)里第i个message时,返回一个证明π
• Verpp(c, i, m, π): 当且仅当π通过验证——c是根据消息序列来计算的,这个消息序列m在位置i,这个函数返回1
CVC
不改变承诺c的情况下改变m
CGen(1λ, q):输出pp和td(trapdoor)
CColpp(c, i, m, m’, td, aux):计算出一个新aux’,当不是m而是m’在第i个位置的时候,承诺还是c
Openpp(i, m’, aux’):输出π’
Verpp(c, i, m’, π’):输出1,证明m’是c向量存的第i个message
可认证关键字搜索过程

两个MB-Tree上的可认证连接处理:
S和R是两个表,里面的内容用树Ts和Tr索引
1.从Tr树的r1作为目标开始,在树Ts的匹配对象是s3,边界对象是s4
2.下一轮,交换Ts和Tr的角色
3.目标变为s4,检索到边界对象r2
4…角色切换一直到目标为r5,它的左边界对象是s12,s12是Ts的最后一个叶节点
结果验证:
1.所有匹配和边界对象,以及它们的Merkel proof(图中阴影部分),都添加到VO
2.客户把每棵树根据这些阴影部分重新构建,对比DO签名的根,来证明匹配的和边界目标的完整性
3.客户端检查每一轮的目标是否是上一轮的右边界,并且在对应的边界内,确保没有丢失任何信息
Suppressed Merkle inv index
先介绍倒排索引
倒排索引:
由一个关键字字典组成,每个关键字都指向一个包含该关键字的对象列表
1.为了支持可认证的关键字查询,给每个关键字的对象列表构建一个 MB-tree,这个ADS就是(Merkle inv) index
2.每个 MB-tree的搜索键就是对象ID(且假设对象id递增,比如用时间戳)
3.当有一个新object进入这个ADS时,这个object的ID和hash值<oi.id, h(oi)>会被插入每个相关关键词的MB-tree
Suppressed Merkle inv Index:
链上的MBTrees只存根哈希,以减少维护成本
SP上存MBTrees的完整结构,以支持高效查询
问题:
智能合约怎样能在不知道完整MBTree结构的情况下维护根哈希?
1.让SP,在新对象插入时构造一个UpdVO
2.UpdVO由足够的可认证信息组成
3.然后被发送到智能合约进行根哈希的更新
下面部分详细介绍UpdVO怎么构造、怎么用它更新根哈希

构造(算法1):SP从上往下遍历,如果不是叶节点,就把它的孩子,除了最右的孩子append进UpdVO,直到叶节点,这个叶节点就是最新进来的object的ID,因为是按照时间戳的

智能合约验证UpdVO:
1.对比UpdVO一起发来的新object的哈希和DO发来的哈希
2.对比SP发来的其他信息,也就是根据UpdVO自底向上重建,然后与存在链上的对比,匹配上了就可以证明UpdVO的完整性

智能合约更新MB-Tree的根哈希(算法2):验证了UpdVO的完整性后再更新。
1.与插入类似,先计算叶节点的哈希,然后逐层向上计算
2.如果因为溢出拆分节点,用内存变量h’记录更新后的哈希值(如果没有分裂),用h1’和h2’记录两个拆分的节点的哈希(如果分裂了,要分别重新计算再存储)
3.最后,更新的根哈希被智能合约存储到链上
4.如果成功,智能合约发送一个事件指示更新操作的完成,如“Successful update for UpdVO.h(o)”
5.SP收到这个事件后才能用更新后的ADS进行后续的查询操作

每一个关键字的MBTree更新需要的消耗:
1.UpdVO由SP送给智能合约,有交易成本
2.UpdVO的完整性验证(验证新Object和树的每一层)
3.更新MBTree的根哈希,并且有可能要拆分
4.智能合约把根哈希更新到链上
成本低的操作,系数是对数级的,成本高的操作,系数是常数级的
Chameleon inverted (Chameleon inv) index
因为MBTree的结构,Merkel inv index还是对数级别的花费
Chameleon inv index可以使花费变成常数级别
A:Overview of the Chameleoninv Index

Chameleon Tree
1.是一个q叉树,每个节点对应一个object和位置pos,从上到下从左到右数数来分配pos
2.根节点:没有对应对象,它只包括一个CVC,计算见橙色波浪线(q+1个0组成的message向量,sk是DO的私钥,w是关键字)
3.(见Fig.8) 每个非根节点:由四个部分组成 {h(o), Cpos, πpos, ρpar,j},Cpos的计算与根不同,多并入了pos;
πpos证明h(o)是存储在更新后的Cpos向量里的第一个元素;
ρpar,j证明这个节点链接到了父节点第j个子节点par的位置,父节点位置是par,证明这个节点是par的子节点中的第j个
πpos和ρpar,j的生成? B部分
自上而下遍历可以很快验证O C部分
1.初始节点都是用q+1个0组成的常数,和固定的数预定义的,之后用陷门更新,向量改变,CVC不改变
2.更新了(插入了新object)的节点总是从左往右与父节点相连
由以上两点,给定对象总数,就能确定Chameleon Tree的结构
所以链上维护的是cnt的值,是常数级的。
Chameleon inv index中,每个关键字一棵Chameleon tree
智能合约只要维护根CVC(不变)和cnt,只有这两者在可认证关键字查找里有作用,作为可认证信息
B:Maintenance of the Chameleoninv Index
Chameleon inv index的维护
初始化,由DO创建初始的Chameleon tree:(算法3)
1.从创建必要的keys开始创建,比如sk、td、pp(比如pp就是Gen函数生成的),且sk和td需要DO保管好,不然就可以篡改index了
2.这些keys生成好后就可以计算出根节点的CVC
3.把w(关键词)和这个CVC(C0)发送给链和SP
插入新O:(算法4)
1.给O创建一个新节点
①分配一个新pos,并计算初始CVC(Cpos)
②DO用td找到CVC的collision,更新向量的第一个元素变为对象的哈希h(o)
③生成πpos
2.链接到对应的父节点
①DO定位父节点npar(par暂且认为就是object的ID)和CVC里的j
②npar里的Cpar要重新计算,找一个collision第j+1个元素,更新为Cpos(第一个元素存自己的h(o),后面的存子节点的C?标号:j和j+1)
③计算相应证明ρpar,j,证明npos是npar的第j个子节点
3.<cpos, πpos, ρpar,j>作为新Object的插入证明,DO把这个插入证明、cnt、O、h(o)发送给SP,把cnt、w发给区块链



π是自己(即第1个element)的collision证明,ρ是父节点的,替换父节点的第j+1个位置(还是第j个?)一个节点有两个message向量吗
是第j+1,向量也是p+1个分量
C: Authenticated Keyword Search with Chameleoninv Index
认证关键字查询
成员资格测试(证明pos位置上有一个object存在)
1.SP生成一个membership prrof,包括:前面的插入证明+所有除根节点的祖先节点(自己的C、π、 ρ,祖先的C、ρ)
2.客户验证:自下而上递归
①自己的π证明自己存在,
②自己的ρ证明是父节点的第i个孩子,
③父节点的ρ和根节点的C(这个C从链上得到)证明父节点是根的第i个孩子,验证完成
认证关键字搜索(算法5)
给每个Chameleon tree建一个object ID和位置的映射哈希表
连接过程:
1.连接也在两棵树之间轮换
2.每一轮,目标、匹配、边界的objects都被加入VOsp
3.两棵树切换角色以找到匹配的对象,直到到达一棵树的末端。
客户端验证(算法6)类似于两个树的连接过程:(注意到这个连接和Fig.4的连接略有不同)
1.客户端检索每个相关的C0和cnt(也就是VOchain)
2.客户端检查每轮连接的VOsp
①本轮的目标的位置是否为1或者上一轮的边界的位置
②用membership proof证明边界对象的完整性
③用membership proof证明目标的完整性,并且如果这个ID和左边界ID匹配就加入到结果
④验证目标对象ID在左右边界ID之间
⑤最后一轮时,客户端额外检查中止位置不能比cnt小
②③保证了健全性(都存在) ①④⑤保证了完整性(无遗漏)


 文章来源:https://www.toymoban.com/news/detail-799644.html
文章来源:https://www.toymoban.com/news/detail-799644.html
论文笔记仅为个人观点,仅供参考文章来源地址https://www.toymoban.com/news/detail-799644.html
到了这里,关于论文笔记-Authenticated Keyword Search in Scalable Hybrid-Storage Blockchains的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!