参考:HuggingFace
参考:https://jalammar.github.io/illustrated-stable-diffusion/
一、什么是 Stable Diffusion
Stable Diffusion 这个模型架构是由 Stability AI 公司推于2022年8月由 CompVis、Stability AI 和 LAION 的研究人员在 Latent Diffusion Model 的基础上创建并推出的。
其原型是(Latent Diffusion Model),一般的扩散模型都需要直接在像素空间训练和运行,训练可能需要上百个 GPUs,在测试推理的时候也需要很多硬件支持。所以就有了 LDM 这个模型的提出,通过平衡【降低复杂度】和【保持图像细节】,能在保持保真度的同时实现模型的加速。
Stable Diffusion 是什么:
- Stable Diffusion 是一种基于扩散过程的图像生成模型,可以生成高质量、高分辨率的图像
- 有较强的稳定性和可控性,可以生成具有多样化效果且良好视觉效果的图片
Stable Diffusion 和 Midjourney 的对比:
- 开源情况:Stable Diffusion 开源,Midjourney 闭源
- 质量情况:Midjourney 生成的图片的质量更高
- 可控情况:Stable Diffusion 生成图片的可控性更高
当图片尺寸变大时,需要的计算能力也随之增加。这种现象在自注意力机制(self-attention)这种操作的影响下尤为突出,因为操作数随着输入量的增大呈平方地增加。一个 128px 的正方形图片有着四倍于 64px 正方形图片的像素数量,所以在自注意力层就需要16倍的内存和计算量。这是高分辨率图片生成任务的普遍问题。
隐式扩散致力于克服这一难题,它使用一个独立的模型 Variational Auto-Encoder(VAE)压缩图片到一个更小的空间维度。这背后的原理是,图片通场都包含了大量的冗余信息。因此,我们可以训练一个 VAE,并通过大量足够的图片数据训练,使得它可以将图片映射到一个较小的隐式空间,并将这个较小的特征映射回原图片。SD 模型中的 VAE 接收一个三通道图片输入,生成出一个四通道的隐式表征,同时每一个空间维度上都减少为原来的八分之一。比如,一个 512px 的正方形图片将会被压缩到一个 4×64×64 的隐式表征上。
通过在隐式表征上(而不是完整图像上)进行扩散过程,我们可以使用更少内存、减少 UNet 层数、加速生成。同时我们仍能把结果输入 VAE 的解码器,解码得到高分辨率图片。这一创新点极大地降低了训练和推理成本。
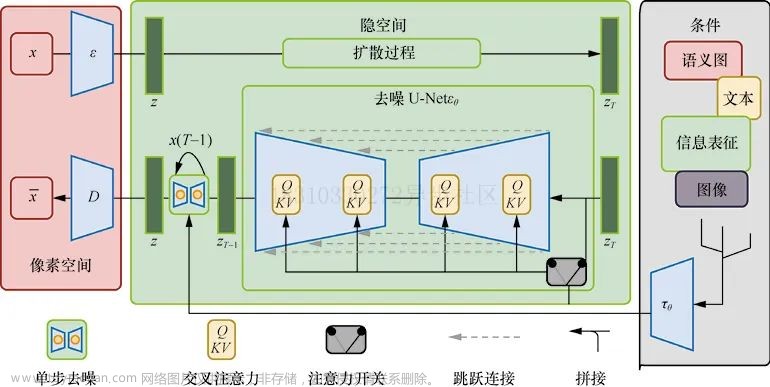
这里再回顾一下基础模型 LDM:
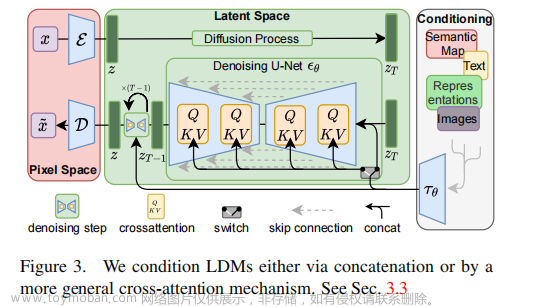
- 输入 Image 为 x x x,输出生成的 Image 为 x ~ \tilde{x} x~
- 先看上面向右传播的这行, ϵ \epsilon ϵ 为编码器,将输入图片编码到潜在空间,然后进行前向扩散加噪,得到 z T z_T zT。这里的编码器使用的 VAE
- 然后看最右侧的黑线框,展示的不同的输入,包括语义图、文本、图像等等,经过 domain-space 的编码器 τ θ \tau_{\theta} τθ 的处理后,输入去噪网络
- 最后看下面这行逆向扩散的这行,在去噪网络中,级联了多个 U-Net 网络,具体数量取决于 T T T 的值,在每个时刻都使用 U-Net 的结构,U-Net 的每个中间层的输入都是 τ θ ( y ) \tau_{\theta}(y) τθ(y) 和 z T z_T zT。D 是从潜在空间又解码到图像空间,最后得到了生成的图片
Stable Diffusion模型中使用变分自编码器(VAE)作为编码器的原因主要有以下几点:
-
生成模型:VAE是一种生成模型,能够学习数据的潜在表示,并且可以从这个潜在空间中抽样来生成新的数据。这与Stable Diffusion的目标,即学习复杂数据分布并从中抽样,非常契合。
-
变分推理:VAE利用变分推理进行参数估计和优化。这使得它能够有效地处理大规模和高维度的数据,这对于许多实际应用(如图像和文本)来说是非常重要的。
-
损失函数:VAE具有结构化的损失函数,包括重构损失和KL散度。这使得我们可以明确地控制重构质量与潜在表示之间的平衡。
-
鲁棒性:由于其随机性质,VAE通常比确定性方法更鲁棒,在面对噪声或缺失值时表现更好。
-
连续潜在空间:VAE假设一个连续的潜在空间,并试图将输入映射到此空间上。连续性使得我们可以通过插值和外推等操作来探索未知区域,并可能帮助改善生成结果的质量。
VAE 是什么:
是一种生成模型,它使用深度学习技术来提供数据的紧凑连续潜在表示。VAE由编码器和解码器两部分组成。
-
编码器:编码器将输入数据(例如图像)映射到一个潜在空间。每个输入都被映射为该空间中的一个点,或者更准确地说,是一个分布。这个分布通常假设为高斯分布,由均值和方差定义。
-
解码器:解码器则执行相反的操作,它从潜在空间中取样,并将这些样本映射回原始数据空间(例如生成图像)。解码过程也是随机的,在给定潜在变量的情况下,输出是原始数据空间上的一个条件分布。
VAE通过最大化下界(ELBO, Evidence Lower BOund)进行训练。ELBO包含两部分:
- 重构损失:测量解码后的输出与原始输入之间的差异。
- KL散度:测量编码后得到的高斯分布与标准正态分布之间的差异。
通过优化这两项内容使得模型能够有效地学习出数据背后复杂且有用的特征,并且保证了潜在空间具有良好结构性质以便于采样和推理。
总结一句话就是, VAE 是一种利用深度神经网络进行参数化并利用变分推理进行训练以学习复杂数据集隐含结构并能从中生成新样本 的生成模型。
二、Diffusers 库
Diffusers 库如何使用:
git clone https://github.com/huggingface/diffusers.git
#可以使用 diffusers 这个 image 起容器
nvcr.io/nvidia/pytorch:22.08-py3
# 然后在容器中安装,为了更方便看内部,我使用了 -e . 的安装方式,每次调用库都会进入我自己的 diffusers 库
cd diffusers
pip install -e .
Diffusers 库是什么:
- diffusers 是 Hugging Face 推出的一个扩散模型库,它提供了简单方便的推理、训练 pipeline,同时拥有一个模型和数据社区,代码可以像 torchhub 一样直接从指定的仓库去调用别人上传的数据集和 pretrain checkpoint
- diffusers 库包括了 SOTA 的扩散模型的管道,只需几行代码就可以在推理中运行,生成想要的图像
- 可使用不同的噪声调度器,用于平衡不同的扩散速度和输出质量。
- 有很多预训练好的模型,可以作为构建模块使用,并与调度器结合,以创建自己的端到端扩散系统。
扩散模型的主要步骤:
- 获取一批数据
- 添加随机噪声
- 将数据输入模型
- 将模型预测与干净图像进行比较,以计算loss
- 更新模型的参数
一个简单的示例如下:
# Dataloader (you can mess with batch size)
batch_size = 128
train_dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
# How many runs through the data should we do?
n_epochs = 3
# Create the network
net = BasicUNet()
net.to(device)
# Our loss finction
loss_fn = nn.MSELoss()
# The optimizer
opt = torch.optim.Adam(net.parameters(), lr=1e-3)
# Keeping a record of the losses for later viewing
losses = []
# The training loop
for epoch in range(n_epochs):
for x, y in train_dataloader:
# Get some data and prepare the corrupted version
x = x.to(device) # Data on the GPU
noise_amount = torch.rand(x.shape[0]).to(device) # Pick random noise amounts
noisy_x = corrupt(x, noise_amount) # Create our noisy x
# Get the model prediction
pred = net(noisy_x)
# Calculate the loss
loss = loss_fn(pred, x) # How close is the output to the true 'clean' x?
# Backprop and update the params:
opt.zero_grad()
loss.backward()
opt.step()
# Store the loss for later
losses.append(loss.item())
# Print our the average of the loss values for this epoch:
avg_loss = sum(losses[-len(train_dataloader):])/len(train_dataloader)
print(f'Finished epoch {epoch}. Average loss for this epoch: {avg_loss:05f}')
# View the loss curve
plt.plot(losses)
plt.ylim(0, 0.1);

🤗 Diffusers 的核心 API 被分为三个主要部分:
- 管线: 从高层出发设计的多种类函数,旨在以易部署的方式,能够做到快速通过主流预训练好的扩散模型来生成样本。
- 模型: 训练新的扩散模型时用到的主流网络架构,e.g. UNet.
- 管理器 (or 调度器): 在推理中使用多种不同的技巧来从噪声中生成图像,同时也生成在训练中所需的带噪图像。这两个步骤都是由 调度器(scheduler) 来处理的。
利用使用 DDPM 的调度器:
from diffusers import DDPMScheduler
noise_scheduler = DDPMScheduler(num_train_timesteps=1000)
# 可以使用 noise_scheduler.add_noise 功能来添加不同程度的噪声
timesteps = torch.linspace(0, 999, 8).long().to(device)
noise = torch.randn_like(xb)
noisy_xb = noise_scheduler.add_noise(xb, noise, timesteps)
print("Noisy X shape", noisy_xb.shape)
show_images(noisy_xb).resize((8 * 64, 64), resample=Image.NEAREST)

扩散模型的 UNet:
大多数扩散模型使用的模型结构都是一些 [U-net] 的变种

简单来说,一个U-net模型大致会有以下三个特征:
- 输入模型中的图片会经过几个由 ResNetLayer 构成的层,其中每层都使图片的尺寸减半。
- 在这之后,同样数量的上采样层会将图片的尺寸恢复到原始规模。
- 残差连接模块会将特征图分辨率相同的上采样层和下采样层连接起来。
U-net模型一个关键特征是输出图片的尺寸与输入图片相同,而这正是我们在扩散模型中所需要的。
Diffusers 为我们提供了一个易用的 UNet2DModel 类,用来在 PyTorch 中创建我们所需要的结构。
我们来使用 U-net 为我们生成目标大小的图片吧。 注意这里 down_block_types 对应下采样模块 (上图中绿色部分), 而 up_block_types 对应上采样模块 (上图中红色部分):
from diffusers import UNet2DModel
# Create a model
model = UNet2DModel(
sample_size=image_size, # the target image resolution
in_channels=3, # the number of input channels, 3 for RGB images
out_channels=3, # the number of output channels
layers_per_block=2, # how many ResNet layers to use per UNet block
block_out_channels=(64, 128, 128, 256), # More channels -> more parameters
down_block_types=(
"DownBlock2D", # a regular ResNet downsampling block
"DownBlock2D",
"AttnDownBlock2D", # a ResNet downsampling block with spatial self-attention
"AttnDownBlock2D",
),
up_block_types=(
"AttnUpBlock2D",
"AttnUpBlock2D", # a ResNet upsampling block with spatial self-attention
"UpBlock2D",
"UpBlock2D", # a regular ResNet upsampling block
),
)
model.to(device);
训练扩散模型:
下面是PyTorch中的一个典型的迭代优化循环过程的步骤,我们在其中逐批(batch)的输入数据,并使用优化器一步步更新模型的参数 - 在这个样例中我们使用学习率为 0.0004 的 AdamW 优化器。
对于每一批的数据,我们会:
- 随机取样几个迭代周期
- 对数据进行相应的噪声处理
- 把带噪数据输入模型
- 使用 MSE 作为损失函数来比较目标结果与模型预测结果,在这个样例中,即是比较真实噪声和模型预测的噪声之间的差距。
- 通过loss.backward ()与optimizer.step ()来更新模型参数
在这个过程中我们需要记录下每一步中的损失函数的值,用来后续绘制损失的曲线图。
# Set the noise scheduler
noise_scheduler = DDPMScheduler(
num_train_timesteps=1000, beta_schedule="squaredcos_cap_v2"
)
# Training loop
optimizer = torch.optim.AdamW(model.parameters(), lr=4e-4)
losses = []
for epoch in range(30):
for step, batch in enumerate(train_dataloader):
clean_images = batch["images"].to(device)
# Sample noise to add to the images
noise = torch.randn(clean_images.shape).to(clean_images.device)
bs = clean_images.shape[0]
# Sample a random timestep for each image
timesteps = torch.randint(
0, noise_scheduler.num_train_timesteps, (bs,), device=clean_images.device
).long()
# Add noise to the clean images according to the noise magnitude at each timestep
noisy_images = noise_scheduler.add_noise(clean_images, noise, timesteps)
# Get the model prediction
noise_pred = model(noisy_images, timesteps, return_dict=False)[0]
# Calculate the loss
loss = F.mse_loss(noise_pred, noise)
loss.backward(loss)
losses.append(loss.item())
# Update the model parameters with the optimizer
optimizer.step()
optimizer.zero_grad()
if (epoch + 1) % 5 == 0:
loss_last_epoch = sum(losses[-len(train_dataloader) :]) / len(train_dataloader)
print(f"Epoch:{epoch+1}, loss: {loss_last_epoch}")
模型训练好之后如何生成图像:
方法一:建立一个管道
from diffusers import DDPMPipeline
image_pipe = DDPMPipeline(unet=model, scheduler=noise_scheduler)
pipeline_output = image_pipe()
pipeline_output.images[0]
# 将模型保存
image_pipe.save_pretrained("my_pipeline")
# ls my_pipeline
# model_index.json scheduler unet
方法二:写一个采样循环
从完全随机的噪声图像开始,从最大噪声往最小噪声方向运行调度器,根据模型的预测每一步去除少量噪声:
# Random starting point (8 random images):
sample = torch.randn(8, 3, 32, 32).to(device)
for i, t in enumerate(noise_scheduler.timesteps):
# Get model pred
with torch.no_grad():
residual = model(sample, t).sample
# Update sample with step
sample = noise_scheduler.step(residual, t, sample).prev_sample
show_images(sample)

三、微调、引导、条件生成
3.1 微调
从头训练一个扩散模型耗费的时间相当长!尤其是当你使用高分辨率图片时,从头训练模型所需的时间和数据量可能多得不切实际。幸运的是,我们还有个解决方法:从一个已经被训练过的模型去开始训练!这样,我们从一个已经学过如何去噪的模型开始,希望能相比于随机初始化的模型能有一个更好的起始点。一般而言,当你的新数据和原有模型的原始训练数据多多少少有点相似的时候,微调效果会最好(比如你想生成卡通人脸,那你用于微调的模型最好是个在人脸数据上训练过的模型)。
3.2 引导
无条件模型一般没有对生成能内容的掌控。我们可以训练一个条件模型(更过内容将会在下节讲述),接收额外输入,以此来操控生成过程。但我们如何使用一个已有的无条件模型去做这件事呢?我们可以用引导这一方法:生成过程中每一步的模型预测都将会被一些引导函数所评估,并加以修改,以此让最终的生成结果符合我们所想。
这个引导函数可以是任何函数,这让我们有了很大的设计空间。在笔记本中,我们从一个简单的例子(控制颜色,如上图所示)开始,到使用一个叫CLIP的预训练模型,让生成的结果基于文字描述。
3.3 条件生成
引导能让我们从一个无条件扩散模型中多少得到些额外的收益,但如果我们在训练过程中就有一些额外的信息(比如图像类别或文字描述)可以输入到模型里,我们可以把这些信息输入模型,让模型使用这些信息去做预测。由此我们就创建了一个条件模型,我们可以在推理阶段通过输入什么信息作为条件来控制模型生成什么。相关的笔记本中就展示了一个例子:一个类别条件的模型,可以根据类别标签生成对应的图像。
有很多种方法可以把条件信息输入到模型种,比如:
- 把条件信息作为额外的通道输入给 UNet。这种情况下一般条件信息都和图片有着相同的形状,比如条件信息是图像分割的掩模(mask)、深度图或模糊版的图像(针对图像修复、超分辨率任务的模型)
- 把条件信息做成一个嵌入(embedding),然后把它映射到和模型其中一个或多个中间层输出的通道数一样,再把这个嵌入加到中间层输出上。这一般是以时间步(timestep)为条件时的做法。比如,你可以把时间步的嵌入映射到特定通道数,然后加到模型的每一个残差网络模块的输出上。这种方法在你有一个向量形式的条件时很有用,比如 CLIP 的图像嵌入。比如能修改输入图片的Stable Diffusion模型。
- 添加有交叉注意力机制的网络层(cross-attention)。这在当条件是某种形式的文字时最有效 —— 比如文字被一个 transformer 模型映射成了一串 embedding,那么UNet中有交叉注意力机制的网络层就会被用来把这些信息合并到去噪路径中。
CLIP 引导
引导生成的图片向某种颜色倾斜确实让我们多少对生成有所控制,但如果我们能仅仅打几行字描述一下就得到我们想要的图片呢?
基本的方法是:
- 给文字提示语做嵌入(embedding),为 CLIP 获取一个 512 维的 embedding
- 对于扩散模型的生成过程的每一步:
- 做出多个不同版本的预测出来的去噪图片(不同的变种可以提供一个更干净的损失信号)
- 对每一个预测出的去噪图片,用 CLIP 给图片做嵌入(embedding),并将这个嵌入和文字的嵌入做对比(用一种叫 Great Circle Distance Squared 的度量方法)
- 计算这个损失对于当前带噪的 x 的梯度,并在用调度器(scheduler)更新它之前用这个梯度去修改 x
# @markdown load a CLIP model and define the loss function
import open_clip
clip_model, _, preprocess = open_clip.create_model_and_transforms(
"ViT-B-32", pretrained="openai"
)
clip_model.to(device)
# Transforms to resize and augment an image + normalize to match CLIP's training data
tfms = torchvision.transforms.Compose(
[
torchvision.transforms.RandomResizedCrop(224), # Random CROP each time
torchvision.transforms.RandomAffine(
5
), # One possible random augmentation: skews the image
torchvision.transforms.RandomHorizontalFlip(), # You can add additional augmentations if you like
torchvision.transforms.Normalize(
mean=(0.48145466, 0.4578275, 0.40821073),
std=(0.26862954, 0.26130258, 0.27577711),
),
]
)
# And define a loss function that takes an image, embeds it and compares with
# the text features of the prompt
def clip_loss(image, text_features):
image_features = clip_model.encode_image(
tfms(image)
) # Note: applies the above transforms
input_normed = torch.nn.functional.normalize(image_features.unsqueeze(1), dim=2)
embed_normed = torch.nn.functional.normalize(text_features.unsqueeze(0), dim=2)
dists = (
input_normed.sub(embed_normed).norm(dim=2).div(2).arcsin().pow(2).mul(2)
) # Squared Great Circle Distance
return dists.mean()
# @markdown applying guidance using CLIP
prompt = "Red Rose (still life), red flower painting" # @param
# Explore changing this
guidance_scale = 8 # @param
n_cuts = 4 # @param
# More steps -> more time for the guidance to have an effect
scheduler.set_timesteps(50)
# We embed a prompt with CLIP as our target
text = open_clip.tokenize([prompt]).to(device)
with torch.no_grad(), torch.cuda.amp.autocast():
text_features = clip_model.encode_text(text)
x = torch.randn(4, 3, 256, 256).to(
device
) # RAM usage is high, you may want only 1 image at a time
for i, t in tqdm(enumerate(scheduler.timesteps)):
model_input = scheduler.scale_model_input(x, t)
# predict the noise residual
with torch.no_grad():
noise_pred = image_pipe.unet(model_input, t)["sample"]
cond_grad = 0
for cut in range(n_cuts):
# Set requires grad on x
x = x.detach().requires_grad_()
# Get the predicted x0:
x0 = scheduler.step(noise_pred, t, x).pred_original_sample
# Calculate loss
loss = clip_loss(x0, text_features) * guidance_scale
# Get gradient (scale by n_cuts since we want the average)
cond_grad -= torch.autograd.grad(loss, x)[0] / n_cuts
if i % 25 == 0:
print("Step:", i, ", Guidance loss:", loss.item())
# Modify x based on this gradient
alpha_bar = scheduler.alphas_cumprod[i]
x = (
x.detach() + cond_grad * alpha_bar.sqrt()
) # Note the additional scaling factor here!
# Now step with scheduler
x = scheduler.step(noise_pred, t, x).prev_sample
grid = torchvision.utils.make_grid(x.detach(), nrow=4)
im = grid.permute(1, 2, 0).cpu().clip(-1, 1) * 0.5 + 0.5
Image.fromarray(np.array(im * 255).astype(np.uint8))
gradio 示例:
```python
import gradio as gr
from PIL import Image, ImageColor
# The function that does the hard work
def generate(color, guidance_loss_scale):
target_color = ImageColor.getcolor(color, "RGB") # Target color as RGB
target_color = [a / 255 for a in target_color] # Rescale from (0, 255) to (0, 1)
x = torch.randn(1, 3, 256, 256).to(device)
for i, t in tqdm(enumerate(scheduler.timesteps)):
model_input = scheduler.scale_model_input(x, t)
with torch.no_grad():
noise_pred = image_pipe.unet(model_input, t)["sample"]
x = x.detach().requires_grad_()
x0 = scheduler.step(noise_pred, t, x).pred_original_sample
loss = color_loss(x0, target_color) * guidance_loss_scale
cond_grad = -torch.autograd.grad(loss, x)[0]
x = x.detach() + cond_grad
x = scheduler.step(noise_pred, t, x).prev_sample
grid = torchvision.utils.make_grid(x, nrow=4)
im = grid.permute(1, 2, 0).cpu().clip(-1, 1) * 0.5 + 0.5
im = Image.fromarray(np.array(im * 255).astype(np.uint8))
im.save("test.jpeg")
return im
# See the gradio docs for the types of inputs and outputs available
inputs = [
gr.ColorPicker(label="color", value="55FFAA"), # Add any inputs you need here
gr.Slider(label="guidance_scale", minimum=0, maximum=30, value=3),
]
outputs = gr.Image(label="result")
# And the minimal interface
demo = gr.Interface(
fn=generate,
inputs=inputs,
outputs=outputs,
examples=[
["#BB2266", 3],
["#44CCAA", 5], # You can provide some example inputs to get people started
],
)
demo.launch(debug=True) # debug=True allows you to see errors and output in Colab
四、Stable Diffusion
4.1 以文本为条件生成
为了达成这一目的,我们首先需要为文本创建一个数值的表示形式,用来获取文字描述的相关信息。为此,SD 利用了一个名为 CLIP 的预训练 transformer 模型。CLIP 的文本编码器可以将文字描述转化为特征向量形式,这个特征向量可以用来和图片的特征向量对比相似度。所以这个模型非常适合用来从文字描述来为图像创建有用的表征信息。一个输入文字提示会首先被分词(tokenize,基于一个很大的词汇库把句中的词语或短语转化为一个个的token),然后被输入进 CLIP 的文字编码器,为每个token产出一个 768 维(针对 SD 1.X版本)或1024维(针对SD 2.X版本)的向量。为了使得输入格式一致,文本提示总是被补全或截断到含有 77 个 token 的长度,所以每个文字提示最终作为生成条件的表示形式是一个形状为 77×1024 的张量。
那我们如何实际地将这些条件信息输入到 UNet 里让它预测使用呢?答案是使用交叉注意力机制(cross-attention)。交叉注意力层从头到尾贯穿了 UNet 结构。UNet 中的每个空间位置都可以“注意”文字条件中不同的token,以此从文字提示中获取到了不同位置的相互关联信息。上面的图表就展示了文字条件信息(以及基于时间周期 time-step 的条件)是如何在不同的位置点输入的。可以看到,UNet 的每一层都有机会去利用这些条件信息!
4.2 无分类器的引导
然而很多时候,即使我们付出了很多努力尽可能让文本成为生成的条件,但模型仍然会在预测时大量地基于带噪输入图片,而不是文字。在某种程度上,这其实是可以解释得通的:很多说明文字和与之关联的图片相关性很弱,所以模型就学着不去过度依赖文字描述!可是这并不是我们期望的效果。如果模型不遵从文本提示,那么我们很可能得到与我们描述根本不相关的图片。
为了解决这一问题,我们使用了一个小技巧,叫做无分类器的引导(Classifie-free Guidance,CGF)。在训练时,我们时不时把文字条件置空,强迫模型去学着在无文字信息的情况下对图片去噪(无条件生成)。在推理阶段,我们分别做两个预测:一个有文字条件,一个没有。我们可以用这两者的差异来建立一个最终结合版的预测,让最终结果在文本条件预测所指明的方向上依据一个缩放系数(即引导尺度)去“走得更远”,希望最终生成一个更好地匹配文字提示的结果。上图就展示了在同一个文本提示下使用不同引导尺度得到的不同结果。可以看到,更高的引导尺度能让生成的图片更接近文字描述。
4.3 其它类型的条件生成:超分辨率、图像修补、深度图到图像的转换
我们也可以创建各种接收不同生成条件的 Stable Diffusion 模型。比如深度图到图像转换模型使用深度信息作为生成条件。在推理阶段,可以输入一个目标图片的深度图,以此来让模型生成一个有相似全局结构的图片。
用相似的方式,我们也可以输入一个低分辨率图片作为条件,让模型生成对应的高分辨率图片(正如Stable Diffusion Upscaler一样)。此外,我们还可以输入一个掩膜(mask),让模型知道图像相应的区域需要让模型用in-painting 的方式重新生成一下:掩膜外的区域要和原图片保持一致,掩膜内的区域要生成出新的内容。
4.4 使用 DreamBooth 微调
DreamBooth 可以用来微调文字到图像的生成模型,教它一些新的概念,比如某一特定物体或某种特定风格。这一技术一开始是为 Google 的 Imagen Model 开发的,但被很快应用于 stable diffusion 中。效果十分惊艳,但该技术也对各种设置十分敏感。
五、使用 Diffusers 库来窥探 Stable Diffusion 内部
参考文件:https://github.com/fastai/diffusion-nbs/blob/master/Stable%20Diffusion%20Deep%20Dive.ipynb
参考视频:https://www.youtube.com/watch?app=desktop&v=0_BBRNYInx8
Diffusers 的关键模块(以 stable diffusion 为例):
- 潜在空间编码器: VAE,即变分自编码器,把图像编码到特征,进行生成过程后再把特征解码到图像
- 扩散模型:UNet
- 文本 token 化:Tokenizer,把输入的文本按照字典编码为对应的 token
- 文本编码器:Text-Encoder,把 tokens 编码为一串向量,用来控制扩散模型的生成
- 采样方式定义:Scheduler
- NSFW 是指 “Not Safe For Work” 或者"Not Suitable For Work",主要作用是用于控制算法不希望在画面中出现不安全或令人不适的元素。Safety_checker 和 Feature_extractor 都是 NSFW 的一部分。
- 模型组织方式:model_index.json
环境准备:
!pip install -Uq diffusers ftfy accelerate
# Installing transformers from source for now since we need the latest version for Depth2Img:
!pip install -Uq git+https://github.com/huggingface/transformers
import torch
import requests
from PIL import Image
from io import BytesIO
from matplotlib import pyplot as plt
# We'll be exploring a number of pipelines today!
from diffusers import (
StableDiffusionPipeline,
StableDiffusionImg2ImgPipeline,
StableDiffusionInpaintPipeline,
StableDiffusionDepth2ImgPipeline
)
# We'll use a couple of demo images later in the notebook
def download_image(url):
response = requests.get(url)
return Image.open(BytesIO(response.content)).convert("RGB")
# Download images for inpainting example
img_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png"
mask_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png"
init_image = download_image(img_url).resize((512, 512))
mask_image = download_image(mask_url).resize((512, 512))
# Set device
device = (
"mps"
if torch.backends.mps.is_available()
else "cuda"
if torch.cuda.is_available()
else "cpu"
)
HuggingFace 模型路径

5.1 Stable Diffusion Pipeline
print(list(pipeline.components.keys())) # List components
['vae', 'text_encoder', 'tokenizer', 'unet', 'scheduler', 'safety_checker', 'feature_extractor']
1、VAE
可变分自编码器(VAE)是一种模型,它可以将输入图像进行编码,得到一个“压缩过”的信息,再把这个“隐式的”压缩信息给解码出来,得到某种接近输入的输出。当我们使用 Stable Diffusion 生成图片时,我们先在VAE的“隐空间”应用扩散过程生成隐编码,然后在结尾对它们解码来得到最终结果图片。这样UNet的输入就不是完整的图片、而是缩小版的特征,可以极大地减少计算资源的使用。
下面代码就使用了 VAE,把输入图片编码成隐式表示形式,再对它解码:
# Create some fake data (a random image, range (-1, 1))
images = torch.rand(1, 3, 512, 512).to(device) * 2 - 1
print("Input images shape:", images.shape)
# Encode to latent space
with torch.no_grad():
latents = 0.18215 * pipe.vae.encode(images).latent_dist.mean
print("Encoded latents shape:", latents.shape)
# Decode again
with torch.no_grad():
decoded_images = pipe.vae.decode(latents / 0.18215).sample
print("Decoded images shape:", decoded_images.shape)
Input images shape: torch.Size([1, 3, 512, 512])
Encoded latents shape: torch.Size([1, 4, 64, 64])
Decoded images shape: torch.Size([1, 3, 512, 512])
在这个例子中,原本 512x512 尺寸的图片被压缩到 64x64的隐式表示形式(有四个通道)中。每一空间维度上都被压缩到了原有的八分之一,这也是上文中为什么我们设定 width 和 height 时需要它们是 8 的倍数。
使用这些信息量充裕的 4x64x64 隐编码可比使用 512px 大小的图片要高效多了,可以让我们的扩散模型更快,并使用更少的资源来训练和使用。VAE的解码过程并不是完美的,但即使损失了一点点质量,总的来说也足够好了。
注意:上面的代码例子包含了一个值为 0.18215 的缩放因子,以此来适配stable diffusion训练时的处理流程。
2、分词器 (Tokenizer) 和文本编码器 (Text Encoder)
文本编码器的作用是将输入的字符串(文本提示)转化成数值表示形式,这样才能输入进 UNet 作为条件。文本首先要被管线中的分词器(tokenizer)转换成一系列的分词(token)。文本编码器有大约五万分词的词汇量 —— 它可以将一个长句子分解为一个个的文本最小单元,这些最小单元被称为 token,在英文中,一般一个单词就可以作为一个分词,而在汉语中,一般一个或多个汉字组成的词语才是一个分词。这些分词的词嵌入(embedding)会被送入文本编码器模型中 —— 文本编码器是一个transformer模型,被训练作为 CLIP 这个模型的文本编码器。在这里,这个预训练过的 transformer 模型已经有了足够好的文本表示能力,能够很好地把文本描述映射到特征空间。
我们这里通过对一个文本描述进行编码,验证一下这个过程。首先,我们手动进行分词,并将它输入到文本编码器中,再使用管线的 _encode_prompt 方法,调用一下这个编码过程,该过程包括补全或截断分词串的长度,使得分词串的长度等于最大长度 77 :
# Tokenizing and encoding an example prompt manualy:
# Tokenize
input_ids = pipe.tokenizer(["A painting of a flooble"])['input_ids']
print("Input ID -> decoded token")
for input_id in input_ids[0]:
print(f"{input_id} -> {pipe.tokenizer.decode(input_id)}")
# Feed through CLIP text encoder
input_ids = torch.tensor(input_ids).to(device)
with torch.no_grad():
text_embeddings = pipe.text_encoder(input_ids)['last_hidden_state']
print("Text embeddings shape:", text_embeddings.shape)
Input ID -> decoded token
49406 -> <|startoftext|>
320 -> a
3086 -> painting
539 -> of
320 -> a
4062 -> floo
1059 -> ble
49407 -> <|endoftext|>
Text embeddings shape: torch.Size([1, 8, 1024])
# Get the final text embeddings using the pipeline's _encode_prompt function:
text_embeddings = pipe._encode_prompt("A painting of a flooble", device, 1, False, '')
text_embeddings.shape
torch.Size([1, 77, 1024])
这些文本嵌入(text embedding),也即文本编码器中最后一个transformer模块的“隐状态(hidden state)”,将会被送入 UNet 中作为 forward 函数的一个额外输入
3、UNet
在扩散模型中,UNet 模型接收一个带噪的输入,并预测噪声,以此实现去噪。但与以往例子不同的是,这里的输入并不是图片了,而是图片的隐式表示形式(latent representation)。此外,除了把用于暗示带噪程度的 timestep 输入进 UNet 作为条件外,这里模型也把文字提示(prompt)的文本嵌入(text embeddings)也作为输入。这里我们用假数据试着让它预测一下,请注意这一过程中各个输入输出的形状大小:
# Dummy inputs:
timestep = pipe.scheduler.timesteps[0]
latents = torch.randn(1, 4, 64, 64).to(device)
text_embeddings = torch.randn(1, 77, 1024).to(device)
# Model prediction:
with torch.no_grad():
unet_output = pipe.unet(latents, timestep, text_embeddings).sample
print('UNet output shape:', unet_output.shape) # Same shape as the input latents
UNet output shape: torch.Size([1, 4, 64, 64])
4、调度器(Scheduler)
调度器保存了如何加噪这一信息,管理着如何基于模型的预测更新带噪样本。默认的调度器是 PNDMScheduler 调度器,但你也可以用其它的(比如 LMSDiscreteScheduler 调度器),只要它们用相同的配置初始化。
我们可以画出图像来观察如何随着 timestep 添加噪声,看看噪声水平(基于 α ˉ \bar{\alpha} αˉ这个参数)是怎样变动的:
plt.plot(pipe.scheduler.alphas_cumprod, label=r'$\bar{\alpha}$')
plt.xlabel('Timestep (high noise to low noise ->)');
plt.title('Noise schedule');plt.legend();
如果你想尝试不同的调度器,可以参考下面代码修改:
from diffusers import LMSDiscreteScheduler
# Replace the scheduler
pipe.scheduler = LMSDiscreteScheduler.from_config(pipe.scheduler.config)
# Print the config
print('Scheduler config:', pipe.scheduler)
# Generate an image with this new scheduler
pipe(prompt="Palette knife painting of an winter cityscape", height=480, width=480,
generator=torch.Generator(device=device).manual_seed(42)).images[0]
Scheduler config: LMSDiscreteScheduler {
"_class_name": "LMSDiscreteScheduler",
"_diffusers_version": "0.11.1",
"beta_end": 0.012,
"beta_schedule": "scaled_linear",
"beta_start": 0.00085,
"clip_sample": false,
"num_train_timesteps": 1000,
"prediction_type": "epsilon",
"set_alpha_to_one": false,
"skip_prk_steps": true,
"steps_offset": 1,
"trained_betas": null
}
5、自己做一个采样循环
现在已经逐个了解这些组成部分了,我们可以把它们拼装到一起,来复现一下整个管线的功能:
guidance_scale = 8 #@param
num_inference_steps=30 #@param
prompt = "Beautiful picture of a wave breaking" #@param
negative_prompt = "zoomed in, blurry, oversaturated, warped" #@param
# Encode the prompt
text_embeddings = pipe._encode_prompt(prompt, device, 1, True, negative_prompt)
# Create our random starting point
latents = torch.randn((1, 4, 64, 64), device=device, generator=generator)
latents *= pipe.scheduler.init_noise_sigma
# Prepare the scheduler
pipe.scheduler.set_timesteps(num_inference_steps, device=device)
# Loop through the sampling timesteps
for i, t in enumerate(pipe.scheduler.timesteps):
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2)
# Apply any scaling required by the scheduler
latent_model_input = pipe.scheduler.scale_model_input(latent_model_input, t)
# predict the noise residual with the unet
with torch.no_grad():
noise_pred = pipe.unet(latent_model_input, t, encoder_hidden_states=text_embeddings).sample
# perform guidance
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents = pipe.scheduler.step(noise_pred, t, latents).prev_sample
# Decode the resulting latents into an image
with torch.no_grad():
image = pipe.decode_latents(latents.detach())
# View
pipe.numpy_to_pil(image)[0]
5.2 文本到图像
下面这是一个使用 Diffusers 库来实现 stable diffusion 推理的代码,可以针对输入的 text 来生成一个名为 output.jpg 的图片:
from diffusers import DiffusionPipeline
import torch
# from_pretrained 函数根据 model_index.json 文件 new 了一个 StableDiffusionPipeline。这个函数会挨个扫描预训练的模型文件夹中的七个文件夹,缺少任意一个都会报错。
# variant="fp16" 表示使用 fp16 精度
pipeline = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", variant="fp16", torch_dtype=torch.float16)
pipeline.to("cuda")
pipeline("An image of a pretty girl in cartoon").images[0].save('output.jpg')
这里的 DiffusionPipeline.from_pretrained 就是会从 https://huggingface.co/runwayml/stable-diffusion-v1-5 中下载模型,我这里下载的都是 fp16 的,可以手动下载,放到自己路径下,然后修改 DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5") 这个路径为自己的路径即可
这是我生成的一个卡通形式的女孩:

这里管线还能设置许多参数,具体如下:
# Load the pipeline
model_id = "stabilityai/stable-diffusion-2-1-base"
pipe = StableDiffusionPipeline.from_pretrained(model_id).to(device)
# Set up a generator for reproducibility
generator = torch.Generator(device=device).manual_seed(42)
# Run the pipeline, showing some of the available arguments
pipe_output = pipeline(
prompt="Palette knife painting of an autumn cityscape", # What to generate
negative_prompt="Oversaturated, blurry, low quality", # What NOT to generate
height=480, width=640, # Specify the image size
guidance_scale=8, # How strongly to follow the prompt
num_inference_steps=35, # How many steps to take
generator=generator # Fixed random seed
)
# View the resulting image:
pipe_output.images[0]
主要的要调节参数介绍:
-
width和height指定了生成图片的尺寸。它们必须是可被 8 整除的数字,只有这样我们的可变分自编码器(VAE)才能正常工作(原因后面会将)。 - 步数
num_inference_steps也会影响生成的质量。默认设成 50 就行,但你也可以试试设成 20,看看设置小了后效果会如何。 - 使用
negative_prompt来强调不希望生成的内容,一般会在无分类器引导(classifier-free guidance)的情况下用到,这种添加额外控制的方式特别管用。列出一些不想要的特性对生成更好结果很有帮助。 -
guidance_scale这个参数决定了无分类器引导(CFG)的影响强度有多大。增大这个值会使得生成的内容更接近文字提示;但这个值如果过大,可能会使得结果变得过饱和、不好看。
还可以看看使用不同的无分类引导强度的效果:
#@markdown comparing guidance scales:
cfg_scales = [1.1, 8, 12] #@param
prompt = "A collie with a pink hat" #@param
fig, axs = plt.subplots(1, len(cfg_scales), figsize=(16, 5))
for i, ax in enumerate(axs):
im = pipe(prompt, height=480, width=480,
guidance_scale=cfg_scales[i], num_inference_steps=35,
generator=torch.Generator(device=device).manual_seed(42)).images[0]
ax.imshow(im); ax.set_title(f'CFG Scale {cfg_scales[i]}');
# model_index.json
{
"_class_name": "StableDiffusionPipeline",
"_diffusers_version": "0.6.0",
"feature_extractor": [
"transformers",
"CLIPImageProcessor"
],
"safety_checker": [
"stable_diffusion",
"StableDiffusionSafetyChecker"
],
"scheduler": [
"diffusers",
"PNDMScheduler"
],
"text_encoder": [
"transformers",
"CLIPTextModel"
],
"tokenizer": [
"transformers",
"CLIPTokenizer"
],
"unet": [
"diffusers",
"UNet2DConditionModel"
],
"vae": [
"diffusers",
"AutoencoderKL"
]
}
diffusers 库是使用 pipeline 来组织每个模型的,pipeline 位于 diffusers/src/diffusers/pipelines/pipeline_utils.py
使用 .from_pretrained() 就可以直接从 huggingface 获取预训练好的模型
@classmethod
@validate_hf_hub_args
def from_pretrained(cls, pretrained_model_name_or_path: Optional[Union[str, os.PathLike]], **kwargs):
r"""
Instantiate a PyTorch diffusion pipeline from pretrained pipeline weights.
The pipeline is set in evaluation mode (`model.eval()`) by default.
If you get the error message below, you need to finetune the weights for your downstream task:
```
Some weights of UNet2DConditionModel were not initialized from the model checkpoint at runwayml/stable-diffusion-v1-5 and are newly initialized because the shapes did not match:
- conv_in.weight: found shape torch.Size([320, 4, 3, 3]) in the checkpoint and torch.Size([320, 9, 3, 3]) in the model instantiated
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
```
Parameters:
pretrained_model_name_or_path (`str` or `os.PathLike`, *optional*):
torch_dtype (`str` or `torch.dtype`, *optional*):
force_download (`bool`, *optional*, defaults to `False`):
Whether or not to force the (re-)download of the model weights and configuration files, overriding the
cached versions if they exist.
cache_dir (`Union[str, os.PathLike]`, *optional*):
Path to a directory where a downloaded pretrained model configuration is cached if the standard cache
is not used.
resume_download (`bool`, *optional*, defaults to `False`):
Whether or not to resume downloading the model weights and configuration files. If set to `False`, any
incompletely downloaded files are deleted.
proxies (`Dict[str, str]`, *optional*):
A dictionary of proxy servers to use by protocol or endpoint, for example, `{'http': 'foo.bar:3128',
'http://hostname': 'foo.bar:4012'}`. The proxies are used on each request.
output_loading_info(`bool`, *optional*, defaults to `False`):
Whether or not to also return a dictionary containing missing keys, unexpected keys and error messages.
local_files_only (`bool`, *optional*, defaults to `False`):
Whether to only load local model weights and configuration files or not. If set to `True`, the model
won't be downloaded from the Hub.
token (`str` or *bool*, *optional*):
The token to use as HTTP bearer authorization for remote files. If `True`, the token generated from
`diffusers-cli login` (stored in `~/.huggingface`) is used.
revision (`str`, *optional*, defaults to `"main"`):
The specific model version to use. It can be a branch name, a tag name, a commit id, or any identifier
allowed by Git.
custom_revision (`str`, *optional*, defaults to `"main"`):
The specific model version to use. It can be a branch name, a tag name, or a commit id similar to
`revision` when loading a custom pipeline from the Hub. It can be a 🤗 Diffusers version when loading a
custom pipeline from GitHub, otherwise it defaults to `"main"` when loading from the Hub.
mirror (`str`, *optional*):
Mirror source to resolve accessibility issues if you’re downloading a model in China. We do not
guarantee the timeliness or safety of the source, and you should refer to the mirror site for more
information.
device_map (`str` or `Dict[str, Union[int, str, torch.device]]`, *optional*):
A map that specifies where each submodule should go. It doesn’t need to be defined for each
parameter/buffer name; once a given module name is inside, every submodule of it will be sent to the
same device.
Set `device_map="auto"` to have 🤗 Accelerate automatically compute the most optimized `device_map`. For
more information about each option see [designing a device
map](https://hf.co/docs/accelerate/main/en/usage_guides/big_modeling#designing-a-device-map).
max_memory (`Dict`, *optional*):
A dictionary device identifier for the maximum memory. Will default to the maximum memory available for
each GPU and the available CPU RAM if unset.
offload_folder (`str` or `os.PathLike`, *optional*):
The path to offload weights if device_map contains the value `"disk"`.
offload_state_dict (`bool`, *optional*):
If `True`, temporarily offloads the CPU state dict to the hard drive to avoid running out of CPU RAM if
the weight of the CPU state dict + the biggest shard of the checkpoint does not fit. Defaults to `True`
when there is some disk offload.
low_cpu_mem_usage (`bool`, *optional*, defaults to `True` if torch version >= 1.9.0 else `False`):
Speed up model loading only loading the pretrained weights and not initializing the weights. This also
tries to not use more than 1x model size in CPU memory (including peak memory) while loading the model.
Only supported for PyTorch >= 1.9.0. If you are using an older version of PyTorch, setting this
argument to `True` will raise an error.
use_safetensors (`bool`, *optional*, defaults to `None`):
If set to `None`, the safetensors weights are downloaded if they're available **and** if the
safetensors library is installed. If set to `True`, the model is forcibly loaded from safetensors
weights. If set to `False`, safetensors weights are not loaded.
use_onnx (`bool`, *optional*, defaults to `None`):
If set to `True`, ONNX weights will always be downloaded if present. If set to `False`, ONNX weights
will never be downloaded. By default `use_onnx` defaults to the `_is_onnx` class attribute which is
`False` for non-ONNX pipelines and `True` for ONNX pipelines. ONNX weights include both files ending
with `.onnx` and `.pb`.
kwargs (remaining dictionary of keyword arguments, *optional*):
Can be used to overwrite load and saveable variables (the pipeline components of the specific pipeline
class). The overwritten components are passed directly to the pipelines `__init__` method. See example
below for more information.
variant (`str`, *optional*):
Load weights from a specified variant filename such as `"fp16"` or `"ema"`. This is ignored when
loading `from_flax`.
<Tip>
To use private or [gated](https://huggingface.co/docs/hub/models-gated#gated-models) models, log-in with
`huggingface-cli login`.
</Tip>
Examples:
```py
>>> from diffusers import DiffusionPipeline
>>> # Download pipeline from huggingface.co and cache.
>>> pipeline = DiffusionPipeline.from_pretrained("CompVis/ldm-text2im-large-256")
>>> # Download pipeline that requires an authorization token
>>> # For more information on access tokens, please refer to this section
>>> # of the documentation](https://huggingface.co/docs/hub/security-tokens)
>>> pipeline = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
>>> # Use a different scheduler
>>> from diffusers import LMSDiscreteScheduler
>>> scheduler = LMSDiscreteScheduler.from_config(pipeline.scheduler.config)
>>> pipeline.scheduler = scheduler
```
"""
经过 from_pretrained() 后得到的 pipeline 如下:
StableDiffusionPipeline {
"_class_name": "StableDiffusionPipeline",
"_diffusers_version": "0.25.0.dev0",
"_name_or_path": "./stable-diffusion-v1-5",
"feature_extractor": [
"transformers",
"CLIPImageProcessor"
],
"image_encoder": [
null,
null
],
"requires_safety_checker": true,
"safety_checker": [
"stable_diffusion",
"StableDiffusionSafetyChecker"
],
"scheduler": [
"diffusers",
"PNDMScheduler"
],
"text_encoder": [
"transformers",
"CLIPTextModel"
],
"tokenizer": [
"transformers",
"CLIPTokenizer"
],
"unet": [
"diffusers",
"UNet2DConditionModel"
],
"vae": [
"diffusers",
"AutoencoderKL"
]
}
stable diffusion 类的位置 diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion.py
# stablediffusion 的 __init__() 函数如下:
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
scheduler: KarrasDiffusionSchedulers,
safety_checker: StableDiffusionSafetyChecker,
feature_extractor: CLIPImageProcessor,
image_encoder: CLIPVisionModelWithProjection = None,
requires_safety_checker: bool = True,
):
5.3 图像到图像
直到现在,我们生成的图片还都是完全从随机的隐变量来开始生成的,而且也都使用了完整的扩散模型采样循环。但如果使用 Img2Img 管线,我们其实不必从头开始。Img2Img 这个管线首先将一张已有的图片进行编码,编码成一系列的隐变量,然后在这些隐变量上随机加噪声,以这些作为起始点。噪声加多大量、去噪需要多少步数(timestep)决定了这个 img2img 过程的“强度”。只加一点点噪声(强度低)只会带来微小改变,而加入大量噪声并跑完完整去噪过程又会让生成出几乎完全不像原始图片,仅在整体结构上还有点相似。
这个管线无需什么特殊模型,只要模型的 ID 和我们的文字到图像模型一样就行,没有新的需要下载的文件。
# Loading an Img2Img pipeline
model_id = "stabilityai/stable-diffusion-2-1-base"
img2img_pipe = StableDiffusionImg2ImgPipeline.from_pretrained(model_id).to(device)
这里是使用该管线的代码:
# Apply Img2Img
result_image = img2img_pipe(
prompt="An oil painting of a man on a bench",
image = init_image, # The starting image
strength = 0.6, # 0 for no change, 1.0 for max strength
).images[0]
# View the result
fig, axs = plt.subplots(1, 2, figsize=(12, 5))
axs[0].imshow(init_image);axs[0].set_title('Input Image')
axs[1].imshow(result_image);axs[1].set_title('Result');
5.4 In-painting
果我们想在一张图中保留一部分不变而在其它部分生成新东西,那该怎么办呢?这种技术叫 inpainting 。虽然我们可以用 StableDiffusionInpaintPipelineLegacy 管线来实现,但其实有更简单的选择。这里的 Stable Diffusion 模型接收一个掩模(mask)作为额外条件性输入。这个掩模图片需要和输入图片尺寸一致,白色区域表示要被替换的部分,黑色区域表示要保留的部分。以下代码就展示了我们如何载入这个管线并如何应用到前面载入的示例图片和掩模上:
# Load the inpainting pipeline (requires a suitable inpainting model)
pipe = StableDiffusionInpaintPipeline.from_pretrained("runwayml/stable-diffusion-inpainting")
pipe = pipe.to(device)
# Inpaint with a prompt for what we want the result to look like
prompt = "A small robot, high resolution, sitting on a park bench"
image = pipe(prompt=prompt, image=init_image, mask_image=mask_image).images[0]
# View the result
fig, axs = plt.subplots(1, 3, figsize=(16, 5))
axs[0].imshow(init_image);axs[0].set_title('Input Image')
axs[1].imshow(mask_image);axs[1].set_title('Mask')
axs[2].imshow(image);axs[2].set_title('Result');
当和其它可以自动生成掩模的模型结合起来的时候,这个模型将会相当强大。比如这个示例space就用了一个名为 CLIPSeg 的模型,它可以根据文字描述自动地用掩模去掉一个物体。
5.5 Depth2Image
Img2Img 已经很厉害了,但有时我们还想借用原始图片的整体结构,但使用不同的颜色或纹理来生成新图片。保留图片整体结构但却不保留原有颜色,是很难通过调节 Img2Img 的“强度”来实现的。
所以这里就需要另一个微调的模型了!这个模型需要输入额外的深度信息作为生成条件。相关管线使用了一个深度预测模型来预测出一个深度图,然后这个深度图会被输入微调过的 UNet 中用以生成图片。我们这里希望生成的图片能够保留原始图片的深度信息和总体结构,同时又在相关部分填入全新的内容。
# Load the Depth2Img pipeline (requires a suitable model)
pipe = StableDiffusionDepth2ImgPipeline.from_pretrained("stabilityai/stable-diffusion-2-depth")
pipe = pipe.to(device)
# Inpaint with a prompt for what we want the result to look like
prompt = "An oil painting of a man on a bench"
image = pipe(prompt=prompt, image=init_image).images[0]
# View the result
fig, axs = plt.subplots(1, 2, figsize=(16, 5))
axs[0].imshow(init_image);axs[0].set_title('Input Image')
axs[1].imshow(image);axs[1].set_title('Result');
让我们和 Img2Img 的例子做个对比 —— 这里生成结果有着更丰富的颜色变化,但图片的整体结构仍然忠于原始图片。这里的例子其实并不够理想,因为为了匹配上狗的形状,这里生成的人有着怪异的身体构造。但在某些场景下,这个技术还是相当有用的,比如这个例子中的“杀手级应用软件”(查看推特),它利用深度模型去给一个 3D 场景加入纹理!
5.6 ControlNet
经过了之前的章节学习之后,相信你已经能够熟练的使用prompt来描述并生成一幅精美的画作了。通常来说,Prompt的准确性越高、描述的越丰富,生成的画作也会越符合你心目中的样子。
然而你也许也注意到了一件事:无论我们再怎么精细的使用prompt来指导Stable diffusion模型,也无法描述清楚人物四肢的角度、背景中物体的位置、每一缕光线照射的角度等等。文字的能力是有极限的!
为了成为一个更加优秀的AI画手,我们需要突破文字提示(Text conditioning),找到一种能够通过图像特征来为扩散模型的生成过程提供更加精细的控制的方式,也就是:图像提示(Image Conditioning)
幸运的是,我们恰好已经有了这样的工具:ControlNet
ControlNet是一种能够嵌入任意已经训练好的扩散模型中,为这些模型提供更多控制条件的神经网络结构。其基本结构如下图所示:

如图所示,ControlNet的基本结构由一个对应的原本扩散模型的block和两个“零卷积”层组成。在之后的训练过程中,我们会“锁死”原本网络的权重,只更新ControlNet结构中的网路“副本”和零卷积层的权重。
这些可训练的神经网络“副本”将学会如何让模型按照新的控制条件来生成结果,而被“锁死”的网络原本则会保留原先网络已经学会的所有知识。
这样,即使用来训练ControlNet的训练集规模较小,被“锁死”的网络原本的权重也能确保扩散模型本身的生成效果不受影响。
在ControlNet中的这些“零卷积层”则是一些weight和bias权重都被初始化为0的 1×1 卷积层。在训练刚开始的时候,无论新添加的控制条件是什么,这些“零卷积”层都只会输出0,因此ControlNet将不会对扩散模型的生成结果造成任何影响。
而随着训练过程的深入,ControlNet部分将学会逐渐调整扩散模型原本的生成过程,使得生成的图像逐渐向新添加的控制条件靠近。
你也许会问,如果一个卷积层的所有参数都为0,输出结果也为0,那么它怎么才能正常的进行权重的迭代过程呢?为了回答这个问题,我们给出一个简单的数学推导过程:
假设我们有一个简单的神经网络层:
y = w x + b y=wx+b y=wx+b
那么我们知道:
∂ y / ∂ w = x , ∂ y / ∂ x = w , ∂ y / ∂ b = 1 \partial y/\partial w=x, \partial y/\partial x=w, \partial y/\partial b=1 ∂y/∂w=x,∂y/∂x=w,∂y/∂b=1
假设其中的权重w为0,输入x不为0,那么我们就有:
∂ y / ∂ w ≠ 0 , ∂ y / ∂ x = 0 , ∂ y / ∂ b ≠ 0 \partial y/\partial w \neq 0, \partial y/\partial x=0, \partial y/\partial b\neq 0 ∂y/∂w=0,∂y/∂x=0,∂y/∂b=0
这意味着只要输入x不为0,梯度下降的迭代过程就能正常的更新权重w,使其不再为0。那么我们将会得到:
∂ y / ∂ x ≠ 0 \partial y/\partial x\neq 0 ∂y/∂x=0
也就是说,经过若干次迭代步骤以后,这些零卷积将会逐渐变成一个有着正常权重的普通卷积层。
将上面所描述的ControlNet Block堆叠十四次以后,我们就能获得了一个完整的、能够用来对稳定扩散模型添加新的控制的条件的ControlNet:

仔细研究过这个结构以后,你就会发现,Controlnet实际上使用了训练完成的稳定扩散模型的encoder模块,来作为自己的主干网络。而这样的一个稳定而又强力的主干网络,则保证了ControlNet能够学到更多不同的控制图像生成的方法。
训练一个附加在某个稳定扩散模型上的ControlNet的过程大致如下:
-
收集你所想要的附加控制条件的数据集和对应prompt。假如你想训练一个通过人体关键点来对扩散模型生成的人体进行姿态控制的ControlNet,你需要先收集一批人物的图片,并标注好这些图片的prompt以及对应的人体的关键点的位置。
-
将prompt输入被“锁死”的稳定扩散模型,将标注好的图像控制条件(例如人体关键点的标注结果)输入ControlNet模型,然后按照稳定扩散模型的训练过程迭代ControlNet模型的权重。
-
训练过程中会随机的将50%的文字提示替换为空白字符串,这样能够“强迫”网络更多的从图像控制条件中学会更多的语义信息。
-
训练结束以后,我们就可以使用该ControlNet对应的图像控制条件(例如输入人体骨骼关键点),来控制扩散模型生成符合条件的图像了。
请注意,因为在该训练过程中原本的扩散模型的权重不会产生任何梯度(我们锁死了这一部分!),所以即使我们添加了十四个ControlNet blocks,整个训练过程也不会需要比训练原先扩散模型更多的显存。
我们在本章节将展示一些已经训练好的ControlNet的示例,这些图片都来自ControlNet的github repo:https://github.com/lllyasviel/ControlNet。
你可以在HuggingFace上找到这些由ControlNet的原作者提供的模型:https://huggingface.co/lllyasviel/ControlNet。
以下图片中左上角的图像为ControlNet的额外控制条件的输入图像,右侧的图像则为给定条件下稳定扩散模型的生成结果。
5.6.1 ControlNet 与 Canny Edge
Prompt:“bird”

5.6.2 ControlNet 与 M-LSD Lines
M-LSD Lines 是另外一种轻量化边缘检测算法,比较擅长提取图像中的直线线条。训练在M-LSD Lines上的ControlNet很适合生成室内环境的图片。
Prompt: “room”

5.6.3 ControlNet 与 HED Boundary
Soft HED Boundary 能够保存输入图片更多的细节,训练在HED Boundary上的ControlNet很适合用来重新上色和风格重构。
Prompt: “oil painting of handsome old man, masterpiece”

5.6.4 ControlNet 与 涂鸦画
ControlNet 的强大能力甚至不使用任何真实图片提取的信息也能生成高质量的结果。训练在涂鸦数据上的ControlNet能让稳定扩散模型学会如何将儿童涂鸦转绘成高质量的图片。
Prompt: “turtle”
5.6.5 ControlNet 与 人体关键点
训练在人体关键点数据上的ControlNet,能让扩散模型学会生成指定姿态的人体。
Prompt: “Chief in the kitchen”

5.6.6 ControlNet 与 语义分割
语义分割模型是一种提取图像中各个区域语义信息的一种模型,常用来对图像中人体、物体、背景的区域进行划分。训练在语义分割数据上的ControlNet适合让稳定扩散模型来生成特定结构的场景图。
Prompt: “House”

5.6.7 实战
!pip install -q diffusers==0.14.0 transformers xformers git+https://github.com/huggingface/accelerate.git
!pip install -q opencv-contrib-python
!pip install -q controlnet_aux
from diffusers import StableDiffusionControlNetPipeline
from diffusers.utils import load_image
image = load_image(
"https://hf.co/datasets/huggingface/documentation-images/resolve/main/diffusers/input_image_vermeer.png"
)
image

# 提取 canny 边缘
import cv2
from PIL import Image
import numpy as np
image = np.array(image)
low_threshold = 100
high_threshold = 200
image = cv2.Canny(image, low_threshold, high_threshold)
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
canny_image = Image.fromarray(image)
canny_image

# 构建管道
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel
import torch
controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16)
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
)
# 选择调度器,UniPCMultistepScheduler。这个调度器能够显著加快模型的推理速度,只需要迭代20次就能达到与之前的默认调度器迭代50次相同的效果!
from diffusers import UniPCMultistepScheduler
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
# 实现
def image_grid(imgs, rows, cols):
assert len(imgs) == rows * cols
w, h = imgs[0].size
grid = Image.new("RGB", size=(cols * w, rows * h))
grid_w, grid_h = grid.size
for i, img in enumerate(imgs):
grid.paste(img, box=(i % cols * w, i // cols * h))
return grid
prompt = ", best quality, extremely detailed"
prompt = [t + prompt for t in ["Sandra Oh", "Kim Kardashian", "rihanna", "taylor swift"]]
generator = [torch.Generator(device="cpu").manual_seed(2) for i in range(len(prompt))]
output = pipe(
prompt,
canny_image,
negative_prompt=["monochrome, lowres, bad anatomy, worst quality, low quality"] * len(prompt),
generator=generator,
num_inference_steps=20,
)
image_grid(output.images, 2, 2)

还可以使用姿态作为输入控制图片生成相同姿态的不同人物
urls = "yoga1.jpeg", "yoga2.jpeg", "yoga3.jpeg", "yoga4.jpeg"
imgs = [
load_image("https://hf.co/datasets/YiYiXu/controlnet-testing/resolve/main/" + url)
for url in urls
]
image_grid(imgs, 2, 2)

# 提取瑜伽姿势
from controlnet_aux import OpenposeDetector
model = OpenposeDetector.from_pretrained("lllyasviel/ControlNet")
poses = [model(img) for img in imgs]
image_grid(poses, 2, 2)

controlnet = ControlNetModel.from_pretrained( "fusing/stable-diffusion-v1-5-controlnet-openpose", torch_dtype=torch.float16 )
model_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionControlNetPipeline.from_pretrained(
model_id,
controlnet=controlnet,
torch_dtype=torch.float16,
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
pipe.enable_model_cpu_offload()
pipe.enable_xformers_memory_efficient_attention()
generator = [torch.Generator(device="cpu").manual_seed(2) for i in range(4)]
prompt = "super-hero character, best quality, extremely detailed"
output = pipe(
[prompt] * 4,
poses,
negative_prompt=["monochrome, lowres, bad anatomy, worst quality, low quality"] * 4,
generator=generator,
num_inference_steps=20,
)
image_grid(output.images, 2, 2)
 文章来源:https://www.toymoban.com/news/detail-799909.html
文章来源:https://www.toymoban.com/news/detail-799909.html
参考:文章来源地址https://www.toymoban.com/news/detail-799909.html
- lllyasviel/sd-controlnet-depth:https://huggingface.co/lllyasviel/sd-controlnet-depth
- lllyasviel/sd-controlnet-hed:https://huggingface.co/lllyasviel/sd-controlnet-hed
- lllyasviel/sd-controlnet-normal:https://huggingface.co/lllyasviel/sd-controlnet-normal
- lllyasviel/sd-controlnet-scribble:https://huggingface.co/lllyasviel/sd-controlnet-scribble
- lllyasviel/sd-controlnet-seg:https://huggingface.co/lllyasviel/sd-controlnet-scribble
- lllyasviel/sd-controlnet-openpose:https://huggingface.co/lllyasviel/sd-controlnet-openpose
- lllyasviel/sd-controlnet-mlsd:https://huggingface.co/lllyasviel/sd-controlnet-mlsd
- lllyasviel/sd-controlnet-mlsd:https://huggingface.co/lllyasviel/sd-controlnet-canny
到了这里,关于【扩散模型】12、Stable Diffusion | 使用 Diffusers 库来看看 Stable Diffusion 的结构的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!