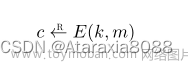前言
原文:
statsthinking21.github.io/statsthinking21-core-site/index.html译者:飞龙
协议:CC BY-NC-SA 4.0
这本书的目标是讲述统计学的故事,以及它如何被全球的研究人员所使用。这是一个与大多数统计学入门书籍中讲述的故事不同的故事,后者侧重于教授如何使用一套工具来实现非常具体的目标。这本书侧重于理解统计思维的基本理念——这是一种系统化的思考方式,用于描述我们如何描述世界并使用数据做出决策和预测,所有这些都是在现实世界中存在的固有不确定性的背景下。它还运用了目前仅在过去几十年中由于计算能力的惊人增长而变得可行的方法。在 20 世纪 50 年代可能需要数年才能完成的分析现在可以在标准笔记本电脑上几秒钟内完成,这种能力释放了使用计算机模拟以新的、强大的方式提出问题的能力。
这本书也是在自 2010 年以来席卷许多科学领域的可重复性危机之后编写的。这场危机的重要根源之一在于统计假设检验被研究人员(正如我在本书的最后一章中详细介绍的那样)所使用(和滥用),这直接关系到统计教育。因此,这本书的目标是强调当前统计方法可能存在问题的方式,并提出替代方案。
0.1 为什么这本书存在?
2018 年,我开始在斯坦福大学教授本科统计课程(Psych 10/Stats 60)。我以前从未教过统计学,这是一个改变现状的机会。我对心理学本科统计教育越来越不满意,我希望为课堂带来许多新的想法和方法。特别是,我希望运用在 21 世纪真实统计实践中越来越多的方法。正如 Brad Efron 和 Trevor Hastie 在他们的书《计算时代的统计推断:算法、证据和数据科学》中所描述的那样,这些方法利用了今天增加的计算能力,以超越通常在心理学学生本科统计课程中教授的更标准的方法来解决统计问题。
我第一年教这门课时,我使用了 Andy Field 的惊人的图像小说统计书《统计学冒险》,作为教科书。这本书有很多我真的很喜欢的东西——特别是,我喜欢它围绕模型构建统计实践的方式,并对零假设检验持有足够的谨慎态度。不幸的是,许多学生不喜欢这本书(除了英语专业的学生,他们喜欢它!),主要是因为它涉及大量故事来获取统计知识。我也觉得它有所欠缺,因为有一些主题(特别是来自人工智能新兴领域的机器学习)我想要包括,但在他的书中没有讨论。我最终认为学生最好通过一本非常贴近我的讲座的书来服务,所以我开始把我的讲座写成一套计算笔记,最终成为这本书。这本书的大纲大致遵循 Field 的书的大纲,因为讲座最初在很大程度上是基于那本书的流程,但内容大不相同(几乎肯定没有那么有趣和聪明)。我还为斯坦福使用的 10 周季度制度量身定制了这本书,这比大多数统计教科书所建立的 16 周学期制度提供了更少的时间。
0.2 数据的黄金时代
在本书中,我尽可能使用真实数据的例子。这现在非常容易,因为我们有大量开放数据集,政府、科学家和公司越来越多地提供数据。我认为使用真实数据很重要,因为它能让学生准备好处理真实数据,而不是玩具数据集,我认为这应该是统计培训的主要目标之一。它还帮助我们意识到(正如我们将在本书的各个部分看到的),数据并不总是准备好分析,通常需要整理来帮助它们变得完善。使用真实数据还表明,统计方法中经常假设的理想化统计分布并不总是适用于现实世界——例如,正如我们将在第 3 章中看到的,一些真实世界数量的分布(如 Facebook 上的朋友数量)可能有非常长的尾巴,这可能会打破许多标准假设。
我提前道歉,数据集主要集中在美国。这主要是因为许多演示所使用的最佳数据集是国家健康和营养调查(NHANES)数据集,该数据集可作为 R 包使用,而且 R 中包含的许多其他复杂数据集(如fivethirtyeight包中的数据集)也是基于美国的。如果您有其他地区的数据集建议,请向我提出!
0.3 做统计的重要性
真正学习统计学的唯一方法就是做统计。尽管历史上许多统计课程都是使用点对点的统计软件进行教学,但现在越来越普遍的是统计教育使用开源语言,学生可以编写自己的分析。我认为能够编写自己的分析是必不可少的,以便深刻理解统计分析,这也是为什么我在斯坦福大学的课程中期望学生学会使用 R 统计编程语言来分析数据,同时也学习本书中的理论知识。
本教科书有两个在线伴侣,可以帮助读者开始学习编程;一个专注于 R 编程语言,另一个专注于 Python 语言。两者目前都是正在进行中的工作——请随时贡献!
0.4 一本开源书
这本书是一本活的文档,因此其源代码可以在github.com/statsthinking21/statsthinking21-core上找到。如果您在书中发现任何错误或想提出改进意见,请在 Github 网站上提出问题。更好的是,提交一个拉取请求,提出您的建议更改。
本书根据知识共享署名-非商业性 4.0 国际许可协议(CC BY-NC 4.0)许可。请查看该许可协议的条款以获取更多详细信息。
0.5 致谢
我首先要感谢 Susan Holmes,她首先激发了我考虑写自己的统计书。Anna Khazenzon 提供了早期的评论和灵感。Lucy King 对整本书提供了详细的评论和编辑,并帮助清理了代码,使其与 Tidyverse 一致。Michael Henry Tessler 对贝叶斯分析章节提供了非常有帮助的评论。特别感谢 Yihui Xie,Bookdown 软件包的创建者,他改进了书中对 Bookdown 功能的使用(包括用户可以通过编辑按钮直接生成编辑)。最后,Jeanette Mumford 对整本书提供了非常有帮助的建议。
我还要感谢其他提供有用评论和建议的人:Athanassios Protopapas,Wesley Tansey,Jack Van Horn,Thor Aspelund。
感谢以下 Twitter 用户提供有用建议:@enoriverbend
感谢以下个人通过 Github 或电子邮件提供编辑或问题:Isis Anderson,Larissa Bersh,Isil Bilgin,Forrest Dollins,Chuanji Gao,Nate Guimond,Alan He,吴建晓,James Kent,Dan Kessler,Philipp Kuhnke,Leila Madeleine,Lee Matos,Ryan McCormick,Jarod Meng,Kirsten Mettler,Shanaathanan Modchalingam,Martijn Stegeman,Mehdi Rahim,Jassary Rico-Herrera,Mingquian Tan,Wenjin Tao,Laura Tobar,Albane Valenzuela,Alexander Wang,Michael Waskom,barbyh,basicv8vc,brettelizabeth,codetrainee,dzonimn,epetsen,carlosivanr,hktang,jiamingkong,khtan,kiyofumi-kan,NevenaK,ttaweel。
特别感谢 Isil Bilgin 在解决许多问题方面的帮助。
第一章:引言
原文:
statsthinking21.github.io/statsthinking21-core-site/introduction.html译者:飞龙
协议:CC BY-NC-SA 4.0
“统计思维将有一天像阅读和写作能力一样,对有效的公民身份来说是必不可少的。”- H.G.威尔斯
1.1 什么是统计思维?
统计思维是一种通过相对简单的方式描述复杂世界的方式,这种方式能够捕捉其结构或功能的基本方面,并且也能够让我们对这些知识的不确定性有一些了解。统计思维的基础主要来自数学和统计学,但也来自计算机科学、心理学和其他研究领域。
我们可以区分统计思维与其他不太可能准确描述世界的思维形式。特别是,人类直觉经常试图回答我们可以用统计思维回答的相同问题,但通常得到错误的答案。例如,近年来,大多数美国人报告说他们认为暴力犯罪比前一年更糟(皮尤研究中心)。然而,对实际犯罪数据的统计分析显示,事实上自 1990 年代以来,暴力犯罪一直在稳步下降。直觉会让我们失望,因为我们依赖于最佳猜测(心理学家称之为启发式),这往往会出错。例如,人类经常使用可得性启发式来判断某些事件(如暴力犯罪)的普遍性——也就是说,我们能多容易地想到一个暴力犯罪的例子。因此,我们对犯罪率增加的判断可能更多地反映了新闻报道的增加,而不是实际犯罪率的下降。统计思维为我们提供了更准确地理解世界的工具,并克服了人类判断的偏见。
1.2 处理统计焦虑
许多人第一次上统计课时会感到很紧张和焦虑,尤其是一旦他们听说他们还必须学习编程才能分析数据。在我的课堂上,我在第一节课之前给学生们做一项调查,以衡量他们对统计学的态度,要求他们对一些陈述进行评分,分数从 1(非常不同意)到 7(非常同意)。调查中的一项是“想到要上统计课让我感到紧张”。在最近的一堂课上,几乎有三分之二的学生回答为五分或更高,大约四分之一的学生表示他们非常同意这个说法。所以如果你对开始学习统计感到紧张,你并不孤单。
焦虑感觉不舒服,但心理学告诉我们,这种情绪激动实际上可以帮助我们在许多任务上表现更好,因为它能够集中我们的注意力。所以如果你开始对这本书中的材料感到焦虑,提醒自己许多其他读者也有类似的感受,这种情绪激动实际上可能会帮助你更好地学习材料(即使看起来并不是这样!)。
1.3 统计学对我们有什么作用?
我们可以用统计学做三件重要的事情:
-
描述:世界是复杂的,我们经常需要以我们能理解的简化方式来描述它。
-
决定:我们经常需要根据数据做出决策,通常是在面对不确定性的情况下。
-
预测:我们经常希望根据我们对先前情况的了解,对新情况进行预测。
让我们看一个这些行动的例子,重点是一个我们许多人都感兴趣的问题:我们如何决定什么是健康的饮食?有许多不同的指导来源;政府膳食指南、饮食书籍和博客,仅举几例。让我们专注于一个具体的问题:我们饮食中的饱和脂肪是一件坏事吗?
我们可能回答这个问题的一种方式是常识。如果我们吃脂肪,那么它会直接在我们的身体里变成脂肪,对吧?我们都看过充满脂肪的动脉的照片,所以吃脂肪会堵塞我们的动脉,对吧?
我们可能回答这个问题的另一种方式是听从权威人士的意见。美国食品和药物管理局的膳食指南中有一个关键建议是“健康饮食模式限制饱和脂肪”。你可能希望这些指南是基于良好的科学,有时候确实是,但正如 Nina Teicholz 在她的书《大脂肪惊喜》(Teicholz 2014)中所概述的,这个特定的建议似乎更多地基于营养研究人员长期以来的教条,而不是实际证据。
最后,我们可能会看一下实际的科学研究。让我们首先看一下一个名为 PURE 研究的大型研究,该研究调查了来自 18 个不同国家的 135,000 多人的饮食和健康结果(包括死亡)。在这个数据集的分析中(2017 年发表在《柳叶刀》上;Dehghan 等人(2017)),PURE 研究人员报告了摄入各种类的大量营养素(包括饱和脂肪和碳水化合物)与人们在随访期间死亡的可能性之间的关系。人们被随访了中位数7.4 年,这意味着研究中有一半的人随访时间少于 7.4 年,另一半人随访时间超过 7.4 年。图 1.1 绘制了从研究中提取的一些数据(从论文中提取),显示了摄入饱和脂肪和碳水化合物与任何原因死亡风险之间的关系。
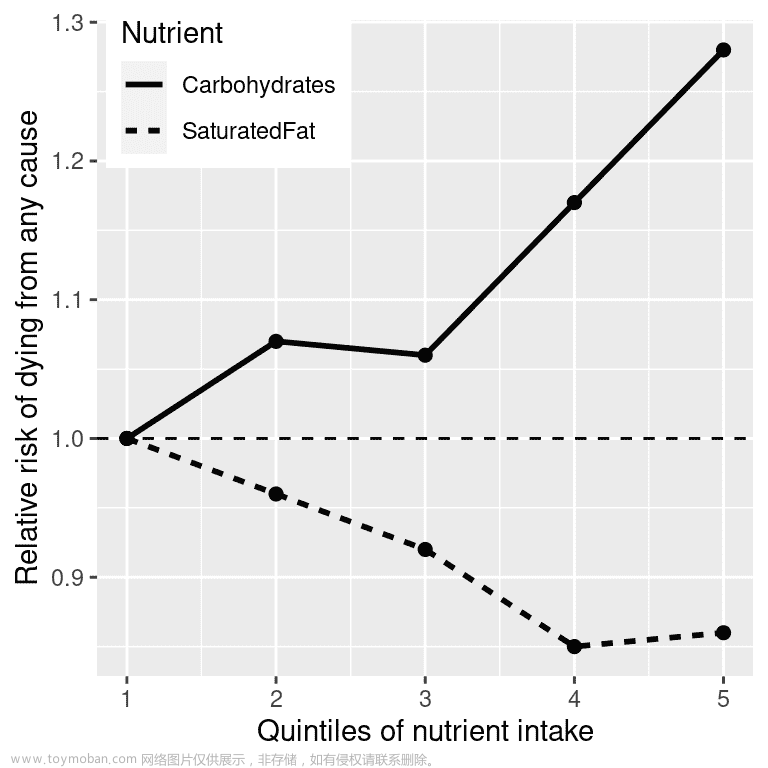
图 1.1:PURE 研究的数据图,显示饱和脂肪和碳水化合物的相对摄入量与任何原因死亡之间的关系。
这个图是基于十个数字。为了获得这些数字,研究人员将 135,335 名研究参与者(我们称之为“样本”)按其摄入任一营养素的顺序分成 5 组(“五分位数”);第一分位数包含摄入最低的 20%的人,第五分位数包含摄入最高的 20%的人。然后研究人员计算了在随访期间每个组的人死亡的频率。图表达了这一点,以相对风险的形式,与最低分位数相比死亡的频率:如果这个数字大于一,意味着该组的人比最低分位数的人更有可能死亡,而如果小于一,意味着该组的人比最低分位数的人更不可能死亡。图表明得很清楚:摄入更多饱和脂肪的人在研究期间死亡的可能性更低,最低死亡率出现在摄入脂肪低于最低 60%但低于最高 20%的人中。而碳水化合物则相反;一个人摄入的碳水化合物越多,在研究期间死亡的可能性就越大。这个例子展示了我们如何使用统计学来用一组更简单的数字描述一个复杂的数据集;如果我们必须同时查看每个研究参与者的数据,我们将被数据淹没,很难看到当它们更简单地描述时所呈现的模式。
图 1.1 中的数字似乎显示饱和脂肪摄入量减少,碳水化合物摄入量增加,但我们也知道数据中存在很多不确定性;有些人尽管摄入低碳水化合物饮食,却早逝,同样地,有些人摄入大量碳水化合物,却活到了老年。鉴于这种变异性,我们希望决定我们在数据中看到的关系是否足够大,以至于我们不会期望它们在没有饮食和寿命之间真正关系的情况下随机发生。统计学为我们提供了做出这类决定的工具,而且外界通常认为这是统计学的主要目的。但正如我们将在整本书中看到的那样,基于模糊证据做出黑白决定的需求经常导致研究人员误入歧途。
基于数据,我们还希望对未来的结果进行预测。例如,一家人寿保险公司可能希望利用有关某个人脂肪和碳水化合物摄入的数据来预测他们可能活多久。预测的一个重要方面是,它要求我们从我们已有的数据中推广到其他情况,通常是未来的情况;如果我们的结论仅限于研究中特定时间的特定人群,那么这项研究就不会太有用。一般来说,研究人员必须假设他们的特定样本代表了更大的总体,这要求他们以一种能够提供总体无偏照片的方式获得样本。例如,如果 PURE 研究从实行素食主义的宗教教派中招募了所有参与者,那么我们可能不希望将结果推广到遵循不同饮食标准的人群。
1.4 统计学的重要思想
统计学的一些非常基本的想法贯穿了几乎所有统计思维的方面。斯蒂格勒(2016)在他出色的著作《统计智慧的七大支柱》中概述了其中的一些,我在这里进行了补充。
1.4.1 从数据中学习
把统计学看作一套工具,使我们能够从数据中学习。在任何情况下,我们都从一组关于可能情况的想法或假设开始。在 PURE 研究中,研究人员可能最初期望摄入更多脂肪会导致更高的死亡率,考虑到关于饱和脂肪的普遍负面教条。在课程的后期,我们将介绍先验知识的概念,这意味着我们所带入情况的知识。这种先验知识的强度可能会有所不同,通常取决于我们的经验量;如果我第一次去一家餐馆,我可能对它的好坏没有太强的期望,但如果我去了一家我之前吃过十次的餐馆,我的期望会强得多。同样,如果我看到一个餐馆评论网站,发现一个餐馆的平均评分是四星,但只基于三条评论,那么我的期望会比基于 300 条评论的情况要弱。
统计学为我们提供了一种描述新数据如何最好地用于更新我们的信念的方法,从而统计学与心理学之间存在着深刻的联系。事实上,心理学中关于人类和动物学习的许多理论与新兴领域机器学习的思想密切相关。机器学习是统计学和计算机科学交叉的领域,专注于如何构建可以从经验中学习的计算机算法。虽然统计学和机器学习经常试图解决相同的问题,但这些领域的研究人员通常采取非常不同的方法;著名的统计学家 Leo Breiman 曾经将它们称为“两种文化”,以反映他们的方法有多么不同(Breiman 2001)。在本书中,我将尝试将这两种文化融合在一起,因为这两种方法都为思考数据提供了有用的工具。
1.4.2 聚合
将统计学视为“丢弃数据的科学”是另一种思考统计学的方式。在上面的 PURE 研究示例中,我们将超过 10 万个数字压缩成了十个。这种聚合是统计学中最重要的概念之一。当它首次提出时,这是一场革命:如果我们丢弃了每个参与者的所有细节,那么我们怎么能确定我们没有错过重要的东西?
正如我们将看到的,统计学为我们提供了表征数据聚合结构的方法,具有理论基础,解释了为什么这通常效果很好。然而,重要的是要记住,聚合可能会走得太远,稍后我们将遇到一些情况,其中摘要可能会对被总结的数据提供一个非常误导性的图片。
1.4.3 不确定性
世界是一个不确定的地方。我们现在知道吸烟会导致肺癌,但这种因果关系是概率性的:一个吸烟了 50 年,每天吸两包烟并继续吸烟的 68 岁男子患肺癌的风险为 15%(7 个人中有 1 个),远高于不吸烟者患肺癌的几率。然而,这也意味着会有很多人一辈子都吸烟却从未患肺癌。统计学为我们提供了描述不确定性的工具,以便在不确定性下做出决策,并对我们可以量化的预测进行预测。
人们经常看到记者写道,科学研究人员已经“证明”了某个假设。但统计分析永远不能“证明”一个假设,不能像在逻辑或数学证明中那样证明它必须是真的。统计学可以为我们提供证据,但它总是暂时的,并受到现实世界中始终存在的不确定性的影响。
1.4.4 从人口中抽样
聚合的概念意味着我们可以通过对数据进行汇总来得出有用的见解-但我们需要多少数据?抽样的概念表明,只要以正确的方式获得了样本,我们就可以根据人口的少量样本总结整个人口。例如,PURE 研究招募了大约 13.5 万人的样本,但其目标是为构成这些人口的数十亿人提供见解。正如我们在上面已经讨论过的那样,研究样本的获取方式至关重要,因为它决定了我们能够推广结果的广度。关于抽样的另一个基本见解是,虽然较大的样本总是更好的(就其准确代表整个人口的能力而言),但随着样本的增大,收益会递减。事实上,随着样本量的增加,更大样本的收益减少的速度遵循一个简单的数学规律,增长为样本量的平方根,这样,为了使我们的估计精度加倍,我们需要使样本的大小增加四倍。
1.5 因果关系和统计学
PURE 研究似乎提供了关于饱和脂肪摄入与长寿之间积极关系的相当强有力的证据,但这并不能告诉我们我们真正想知道的:如果我们摄入更多饱和脂肪,那会让我们活得更久吗?这是因为我们不知道摄入饱和脂肪和长寿之间是否存在直接因果关系。数据与这种关系一致,但它们同样也与其他因素导致了更高的饱和脂肪和更长的寿命。例如,人们可能会想象富人吃更多饱和脂肪,富人更长寿,但他们更长的寿命不一定是由于脂肪摄入 - 它可能是由于更好的医疗保健,减少的心理压力,更好的食品质量或许多其他因素。PURE 研究的调查人员试图考虑这些因素,但我们不能确定他们的努力是否完全消除了其他变量的影响。其他因素可能解释了饱和脂肪摄入与死亡之间的关系,这就是为什么入门统计课程经常教导“相关不意味着因果关系”,尽管著名的数据可视化专家爱德华·图夫特补充说:“但这确实是一个暗示。”
尽管观察研究(如 PURE 研究)不能最终证明因果关系,我们通常认为可以使用实验控制和操纵特定因素的研究来证明因果关系。在医学上,这样的研究被称为随机对照试验(RCT)。假设我们想进行一项 RCT 来研究增加饱和脂肪摄入是否会延长寿命。为此,我们将对一组人进行抽样,然后将他们分配到治疗组(被告知增加饱和脂肪摄入)或对照组(被告知保持与以前相同的饮食)。我们必须将这些个体随机分配到这些组中。否则,选择治疗的人可能在某种程度上与选择对照组的人不同 - 例如,他们可能更有可能参与其他健康行为。然后,我们将随着时间跟踪参与者,并观察每组有多少人死亡。因为我们将参与者随机分配到治疗或对照组,我们可以相当有信心地认为两组之间没有其他差异会混淆治疗效果;然而,我们仍然不能确定,因为有时随机化会产生在某些重要方面确实有所不同的治疗与对照组。研究人员通常尝试使用统计分析来解决这些混淆,但从数据中消除混淆的影响可能非常困难。
许多 RCT 已经研究了改变饱和脂肪摄入是否会导致更健康和更长寿的问题。这些试验主要关注减少饱和脂肪,因为营养研究人员中存在着饱和脂肪是致命的强烈教条;大多数这些研究人员可能会认为导致人们摄入更多饱和脂肪是不道德的!然而,这些 RCT 已经显示了非常一致的模式:总体上减少饱和脂肪摄入对死亡率没有明显影响。
1.6 学习目标
阅读完本章后,您应该能够:
-
描述统计学的中心目标和基本概念
-
描述实验和观察研究在因果推断方面的区别
-
解释随机化如何提供了对因果推断的能力。
1.7 建议阅读
-
*《统计智慧的七大支柱》作者:斯蒂格勒
-
*《品茶的女士:统计学如何在二十世纪改变了科学》作者:大卫·萨尔斯伯格
-
*《裸统计:剥去数据的恐惧》作者:查尔斯·威兰
参考资料
Breiman, Leo. 2001. “Statistical Modeling: The Two Cultures (with Comments and a Rejoinder by the Author).” Statist. Sci. 16 (3): 199–231. https://doi.org/10.1214/ss/1009213726.
Dehghan, Mahshid, Andrew Mente, Xiaohe Zhang, Sumathi Swaminathan, Wei Li, Viswanathan Mohan, Romaina Iqbal, et al. 2017. “Associations of Fats and Carbohydrate Intake with Cardiovascular Disease and Mortality in 18 Countries from Five Continents (PURE): A Prospective Cohort Study.” Lancet 390 (10107): 2050–62. https://doi.org/10.1016/S0140-6736(17)32252-3.
Stigler, Stephen M. 2016. The Seven Pillars of Statistical Wisdom. Harvard University Press.
Teicholz, Nina. 2014. The Big Fat Surprise. Simon & Schuster.
第二章:数据处理
原文:
statsthinking21.github.io/statsthinking21-core-site/working-with-data.html译者:飞龙
协议:CC BY-NC-SA 4.0
2.1 什么是数据?
关于数据的第一个重要观点是数据是复数形式的(尽管有些人不同意我的观点)。你可能还想知道如何发音“数据”-我说“day-tah”,但我知道很多人说“dah-tah”,尽管如此,我还是能和他们保持朋友关系。现在,如果我听到他们说“数据是”,那就是一个更大的问题…
2.1.1 定性数据
数据由变量组成,其中变量反映了独特的测量或数量。一些变量是定性的,意思是它们描述的是质量而不是数值数量。例如,在我的统计课上,我通常进行入门调查,既是为了获取课堂上使用的数据,也是为了更多地了解学生。我问的一个问题是“你最喜欢的食物是什么?”,其中一些答案是:蓝莓、巧克力、玉米卷、意大利面、比萨和芒果。这些数据本质上不是数字;我们可以给每个数据分配一个数字(1=蓝莓,2=巧克力等),但我们只是把数字当作标签而不是真正的数字。这也限制了我们对这些数字应该做什么;例如,计算这些数字的平均值是没有意义的。然而,我们经常使用数字对定性数据进行编码,以便更容易处理,你以后会看到。
2.1.2 定量数据
在统计学中,我们更常见地使用定量数据,意思是数据是数字的。例如,这里的表 2.1 显示了我在入门课上问的另一个问题的结果,即“你为什么选修这门课?”
表 2.1:对“你为什么选修这门课?”这个问题的不同回答的普遍性的计数
| 你为什么选修这门课? | 学生人数 |
|---|---|
| 它满足学位计划的要求 | 105 |
| 它满足通识教育广度要求 | 32 |
| 不是必须的,但我对这个主题感兴趣 | 11 |
| 其他 | 4 |
注意学生的答案是定性的,但我们通过计算每个学生给出的回答数量,生成了一个定量的总结。
2.1.2.1 数字的类型
在统计学中,我们使用几种不同类型的数字。了解这些差异很重要,部分原因是因为统计分析语言(如 R)通常区分它们。
二进制数。最简单的是二进制数-即零或一。我们经常使用二进制数来表示某事物是真或假,或者存在或不存在。例如,我可能问 10 个人他们是否曾经经历过偏头痛,记录他们的答案为“是”或“否”。通常,我们会使用逻辑值,它们的值要么是TRUE,要么是FALSE。当我们开始使用像 R 这样的编程语言来分析我们的数据时,这将特别有用,因为这些语言已经理解了 TRUE 和 FALSE 的概念。事实上,大多数编程语言都等价地处理真值和二进制数。数字 1 等于逻辑值TRUE,数字零等于逻辑值FALSE。
整数。整数是没有分数或小数部分的整数。我们最常遇到整数的情况是计数,但它们也经常出现在心理测量中。例如,在我的入门调查中,我提出了一系列关于对统计学态度的问题(比如“统计学对我来说非常神秘。”),学生们用 1 到 7 之间的数字来回答。
实数。在统计学中,我们通常使用实数,它们具有分数/小数部分。例如,我们可能测量某人的体重,可以用任意精度来测量,从千克到微克。
离散与连续测量
离散测量是指取有限一组特定数值中的一个的测量。这些可以是定性数值(例如,不同品种的狗)或数值数值(例如,一个人在 Facebook 上有多少朋友)。重要的是,测量之间没有中间地带;说一个人有 33.7 个朋友是没有意义的。
连续测量是指以实数定义的测量。它可以落在特定数值范围内的任何位置,尽管通常我们的测量工具会限制我们测量的精度;例如,地板秤可能会将重量测量到最接近的公斤,即使理论上重量可以用更高的精度来测量。
在统计学课程中,通常会更详细地讨论不同的测量“尺度”,这在本章附录中有更详细的讨论。从中最重要的收获是,某些类型的数据上某些类型的统计学是没有意义的。例如,想象一下,我们要从许多人那里收集邮政编码数据。这些数字表示为整数,但它们实际上并不是指数标度;每个邮政编码基本上是不同地区的标签。因此,谈论平均邮政编码是没有意义的。
什么构成一个好的测量?
在许多领域,如心理学,我们测量的东西不是一个物理特征,而是一个不可观察的理论概念,我们通常称之为“构念”。例如,假设我想测试你对上述不同类型数字的区别理解得有多好。我可以给你一张小测验,问你几个关于这些概念的问题,并计算你答对了多少。这个测试可能或可能不是对你实际知识构念的一个好的测量 - 例如,如果我把测试写得很混乱或使用你不理解的语言,那么测试可能会表明你不理解这些概念,而实际上你是理解的。另一方面,如果我给出一个非常明显的错误答案的选择题测试,那么即使你实际上不理解材料,你可能也能在测试中表现良好。
通常不可能在没有一定程度的误差的情况下测量一个构念。在上面的例子中,你可能知道答案,但你可能误读问题并回答错误。在其他情况下,被测量的事物本身就存在误差,比如我们测量一个人在简单反应时间测试中的反应时间,这会因为很多原因在每次试验中有所不同。我们通常希望我们的测量误差尽可能低,这可以通过改善测量的质量(例如,使用更好的时间来测量反应时间),或者通过对更多个体测量进行平均来实现。
有时有一个标准,其他测量可以根据这个标准进行测试,我们可能称之为“黄金标准” - 例如,可以使用许多不同的设备来测量睡眠(如测量床上的运动的设备),但它们通常被认为是次要的,与多导睡眠图(使用脑电波测量来量化一个人在每个睡眠阶段中花费的时间)相比。通常黄金标准更难或更昂贵,但更便宜的方法被使用,即使它可能有更大的误差。
当我们考虑什么构成一个好的测量时,我们通常区分一个好的测量的两个不同方面:它应该是可靠的,它应该是有效的。
2.3.1 可靠性
可靠性指的是我们测量的一致性。一种常见的可靠性形式,称为“测试-重测可靠性”,衡量了如果同样的测量被执行两次,这些测量有多么一致。例如,我今天可能会给你一份关于你对统计学态度的问卷调查,明天重复这个问卷调查,然后比较你两天的答案;我们希望它们彼此非常相似,除非在两次测试之间发生了应该改变你对统计学看法的事情(比如读了这本书!)。
另一种评估可靠性的方法是在数据包含主观判断的情况下。例如,假设一个研究人员想要确定一种治疗是否改变了自闭症儿童与其他儿童互动的能力,这是通过让专家观察孩子并评价他们与其他孩子的互动来衡量的。在这种情况下,我们希望确保答案不依赖于个体评分者 — 也就是说,我们希望有很高的评分者间可靠性。这可以通过让多个评分者进行评分,然后比较他们的评分来确保他们之间的一致性。
如果我们想要将一个测量与另一个测量进行比较,可靠性就很重要,因为两个不同变量之间的关系不能比任何一个变量与自身的关系更强(即,它的可靠性)。这意味着一个不可靠的测量永远不可能与任何其他测量有很强的统计关系。因此,研究人员开发新的测量(比如新的调查)通常会不遗余力地建立和改进其可靠性。

图 2.1:一幅图表演示了可靠性和有效性之间的区别,使用了对靶心的射击。可靠性指的是射击位置的一致性,有效性指的是射击与靶心的准确性。
2.3.2 有效性
可靠性很重要,但单靠可靠性还不够:毕竟,我可以通过重新编码每个答案为相同的数字来在人格测试中创建一个完全可靠的测量,而不管这个人实际上是如何回答的。我们希望我们的测量也是有效的 — 也就是说,我们希望确保我们实际上正在测量我们认为正在测量的构建物(图 2.1)。通常讨论的有效性类型有很多种;我们将重点关注其中的三种。
面向有效性。测量在表面上是否合理?如果我告诉你我要通过观察舌头的颜色来测量一个人的血压,你可能会认为这在表面上不是一个有效的测量。另一方面,使用血压袖带就具有面向有效性。这通常是在我们深入讨论有效性的更复杂方面之前的第一个现实检查。
构造效度。测量是否以适当的方式与其他测量相关?这通常分为两个方面。收敛效度意味着测量应与被认为反映相同构造的其他测量密切相关。假设我对使用问卷调查或面试来衡量一个人的外向性感兴趣。如果这两种不同的测量都与彼此密切相关,那么就证明了收敛效度。另一方面,被认为反映不同构造的测量应该是无关的,称为发散效度。如果我的个性理论认为外向性和责任心是两个不同的构造,那么我还应该看到我的外向性测量与责任心测量是无关的。
预测效度。如果我们的测量确实有效,那么它们也应该能预测其他结果。例如,假设我们认为心理特质的感觉寻求(对新经验的渴望)与现实世界中的冒险行为有关。为了测试感觉寻求测量的预测效度,我们将测试测试分数如何预测测量现实世界冒险行为的不同调查的分数。
2.4 学习目标
阅读完本章后,您应该能够:
-
区分不同类型的变量(定量/定性,二进制/整数/实数,离散/连续)并举例说明这些变量的每种类型
-
区分可靠性和有效性的概念,并将每个概念应用于特定数据集
2.5 建议阅读
- 具有 R 应用的心理测量理论简介 - 关于心理测量的免费在线教材
2.6 附录
2.6.1 测量尺度
所有变量必须至少具有两个不同的可能值(否则它们将是一个常数而不是一个变量),但变量的不同值可以以不同的方式相互关联,我们称之为测量尺度。变量的不同值可以有四种不同的方式。
-
身份:变量的每个值都有独特的含义。
-
大小:变量的值反映不同的大小,并且彼此之间有一个有序的关系 - 也就是说,一些值较大,一些值较小。
-
等距:测量尺度上的单位彼此相等。这意味着,例如,1 和 2 之间的差异在大小上等同于 19 和 20 之间的差异。
-
绝对零点:尺度具有真正有意义的零点。例如,对于许多身高或体重等物理量的测量,这是被测量物的完全缺席。
测量的四种不同尺度与变量值的不同方式相对应。
名义尺度。名义变量满足身份的标准,即变量的每个值代表不同的东西,但数字只是作为上面讨论的定性标签。例如,我们可能会问人们他们的政党隶属,然后将其编码为数字:1 =“共和党”,2 =“民主党”,3 =“自由党”,等等。然而,不同的数字之间没有任何有序关系。
序数刻度。序数变量满足身份和大小的标准,使得值可以按其大小排序。例如,我们可能要求慢性疼痛患者每天填写一张表,评估他们的疼痛有多严重,使用 1-7 的数字刻度。请注意,虽然在报告 6 和报告 3 的日子,这个人可能在前者比后者感到更痛苦,但说他们的痛苦在前者和后者的日子上是两倍严重是没有意义的;排序为我们提供了有关相对大小的信息,但值之间的差异在大小上不一定相等。
间隔刻度。间隔刻度具有序数刻度的所有特征,但是除此之外,测量刻度上单位之间的间隔可以被视为相等。一个标准的例子是用摄氏或华氏度测量的物理温度;10 度和 20 度之间的物理差异与 90 度和 100 度之间的物理差异相同,但每个刻度也可以取负值。
比率刻度。比率刻度变量具有上述所有四个特征:身份、大小、相等间隔和绝对零点。比率刻度变量与间隔刻度变量的区别在于比率刻度变量具有真正的零点。比率刻度变量的例子包括身高和体重,以及以开尔文度测量的温度。
我们必须注意变量的测量刻度有两个重要原因。首先,刻度决定了我们可以对数据应用什么样的数学运算(见表 2.2)。名义变量只能比较是否相等;也就是说,该变量上的两个观察是否具有相同的数值?对名义变量应用其他数学运算是没有意义的,因为它们在名义变量中并不真正作为数字,而是作为标签。对于序数变量,我们也可以测试一个值是否大于或小于另一个值,但我们不能进行任何算术运算。间隔和比率变量允许我们执行算术运算;对于间隔变量,我们只能添加或减去值,而对于比率变量,我们还可以相乘和相除值。
表 2.2:不同的测量刻度允许不同类型的数值运算
| 相等/不相等 | 大于/小于 | 相加/相减 | 相乘/相除 | |
|---|---|---|---|---|
| 名义 | 可以 | |||
| 序数 | 可以 | 可以 | ||
| 间隔 | 可以 | 可以 | 可以 | |
| 比率 | 可以 | 可以 | 可以 | 可以 |
这些限制也意味着我们可以计算每种变量类型的某些统计数据。简单涉及不同值的计数统计(例如最常见的值,称为模式)可以计算在任何变量类型上。其他统计数据基于值的排序或排名(例如中位数,当所有值按其大小排序时,它是中间值),这要求至少值在序数刻度上。最后,涉及值相加的统计数据(例如平均值,或均值)要求变量至少在间隔刻度上。话虽如此,我们应该注意,研究人员经常计算仅在序数上的变量的均值(例如个性测试的回答),但这有时可能会有问题。
第三章:总结数据
原文:
statsthinking21.github.io/statsthinking21-core-site/summarizing-data.html译者:飞龙
协议:CC BY-NC-SA 4.0
我在介绍中提到统计学的一个重大发现是,我们可以通过丢弃信息来更好地理解世界,这正是我们总结数据时所做的。在本章中,我们将讨论为什么以及如何总结数据。
3.1 为什么总结数据?
当我们总结数据时,我们必然会丢失信息,人们可能会对此提出异议。举个例子,让我们回到我们在第一章中讨论的 PURE 研究。我们难道不应该相信每个个体的所有细节都很重要,而不仅仅是数据集中总结的那些细节吗?那么数据收集的具体细节,比如一天中的时间或参与者的心情呢?当我们总结数据时,所有这些细节都会丢失。
我们总结数据的一个原因是它为我们提供了一种概括的方式 - 也就是说,可以做出超出具体观察的一般性陈述。概括的重要性在作家豪尔赫·路易斯·博尔赫斯的短篇小说《费内斯的记忆》中得到了强调,该小说描述了一个失去遗忘能力的个体。博尔赫斯着重讨论了概括(即丢弃数据)与思维之间的关系:“思考就是忘记差异,概括,抽象。在费内斯过于充实的世界中,只有细节。”
心理学家长期以来一直研究思维中的概括方式。一个例子是分类:我们能够轻松地识别“鸟类”这一类别的不同例子,即使这些个体例子在表面特征上可能非常不同(比如鸵鸟、知更鸟和鸡)。重要的是,概括让我们能够对这些个体做出预测 - 在鸟类的情况下,我们可以预测它们能够飞行和吃种子,而它们可能不能开车或说英语。这些预测并不总是正确的,但它们通常足够在现实世界中有用。
3.2 使用表格总结数据
总结数据的一个简单方法是生成一个代表各种类型观察计数的表格。这种类型的表格已经被使用了数千年(见图 3.1)。

图 3.1:来自卢浮宫的苏美尔文版,显示了一份房屋和田地的销售合同。公共领域,通过维基共享资源。
让我们看一些使用表格的例子,使用一个更现实的数据集。在本书中,我们将使用国家健康和营养调查(NHANES)数据集。这是一项持续研究,评估来自美国的个体样本在许多不同变量上的健康和营养状况。我们将使用 R 统计软件包可用的数据集版本。在这个例子中,我们将查看一个简单的变量,在数据集中称为PhysActive。这个变量包含三种不同的值:“是”或“否”(表示个人是否报告进行“中等或剧烈强度的体育、健身或娱乐活动”),或者如果该个体的数据缺失,则为“NA”。数据可能缺失的原因有不同;例如,这个问题没有问及 12 岁以下的儿童,而在其他情况下,成年人可能在采访中拒绝回答问题,或者采访者在表格上记录答案的方式可能不可读。
3.2.1 频率分布
分布描述了数据如何分布在不同的可能值之间。例如,让我们看看有多少人属于每个身体活动类别。
表 3.1:PhysActive 变量的频率分布
| 身体活动 | 绝对频率 |
|---|---|
| 否 | 2473 |
| 是 | 2972 |
| NA | 1334 |
表 3.1 显示了每个不同值的频率;有 2473 个人回答“否”,2972 个人回答“是”,1334 个人没有回答。我们称这为频率分布,因为它告诉我们在我们的样本中每个可能值有多频繁。
这向我们展示了两种回答的绝对频率,对于实际给出回答的所有人。我们可以从中看出说“是”的人比说“否”的人更多,但从绝对数字中很难判断相对差异有多大。因此,我们通常更愿意使用相对频率来呈现数据,这是通过将每个频率除以所有频率的总和得到的:
相对频 率 i = 绝对频 率 i ∑ j = 1 N 绝对频 率 j 相对频率 _i = \frac{绝对频率 _i}{\sum_{j=1}^N 绝对频率 _j} 相对频率i=∑j=1N绝对频率j绝对频率i
相对频率提供了一个更容易看出不平衡有多大的方式。我们还可以将相对频率解释为百分比,方法是将它们乘以 100。在这个例子中,我们也会删除 NA 值,因为我们希望能够解释活跃和不活跃人群的相对频率。但是,为了使这有意义,我们必须假设 NA 值是“随机缺失”的,这意味着它们的存在或缺失与该人的变量的真实值无关。例如,如果不活跃的参与者更有可能拒绝回答问题,那么这将偏倚我们对身体活动频率的估计,这意味着我们的估计将与真实值不同。
表 3.2:PhysActive 变量的绝对频率和相对频率以及百分比
| 身体活动 | 绝对频率 | 相对频率 | 百分比 |
|---|---|---|---|
| 否 | 2473 | 0.45 | 45 |
| 是 | 2972 | 0.55 | 55 |
表 3.2 让我们看到 NHANES 样本中 45.4%的个体说“否”,54.6%说“是”。
3.2.2 累积分布
我们上面检查的PhysActive变量只有两个可能的值,但通常我们希望总结可能有更多可能值的数据。当这些值是定量的时,一种有用的总结方式是通过我们所谓的累积频率表示:我们不是问有多少观察值取特定值,而是问有多少取特定值或更少的值。
让我们看看 NHANES 数据集中的另一个变量,称为SleepHrsNight,记录参与者在工作日通常睡眠的小时数。表 3.3 显示了一个频率表,我们删除了任何对这个问题缺失数据的人。我们可以通过查看表格来开始总结数据集;例如,我们可以看到大多数人报告每晚睡 6 到 8 小时。为了更清楚地看到这一点,我们可以绘制一个直方图,显示每个不同值的案例数量;参见图 3.2 的左面板。我们还可以绘制相对频率,我们经常称为密度 - 参见图 3.2 的右面板。
表 3.3:NHANES 数据集中每晚睡眠小时数的频率分布
| 每晚睡眠小时数 | 绝对频率 | 相对频率 | 百分比 |
|---|---|---|---|
| 2 | 9 | 0.00 | 0.18 |
| 3 | 49 | 0.01 | 0.97 |
| 4 | 200 | 0.04 | 3.97 |
| 5 | 406 | 0.08 | 8.06 |
| 6 | 1172 | 0.23 | 23.28 |
| 7 | 1394 | 0.28 | 27.69 |
| 8 | 1405 | 0.28 | 27.90 |
| 9 | 271 | 0.05 | 5.38 |
| 10 | 97 | 0.02 | 1.93 |
| 11 | 15 | 0.00 | 0.30 |
| 12 | 17 | 0.00 | 0.34 |

图 3.2:左:直方图显示 NHANES 数据集中报告每个可能值的 SleepHrsNight 变量的人数(左)和比例(右)。
如果我们想知道有多少人报告睡眠 5 小时或更少,该怎么办?为了找到这个值,我们可以计算累积分布。要计算某个值 j 的累积频率,我们将所有值直到 j 的频率相加:
KaTeX parse error: Undefined control sequence: \频 at position 29: …um_{i=1}^{j}{绝对\̲频̲率 _i}
表 3.4:SleepHrsNight 变量的绝对和累积频率分布
| 每晚睡眠小时数 | 绝对频率 | 累积频率 |
|---|---|---|
| 2 | 9 | 9 |
| 3 | 49 | 58 |
| 4 | 200 | 258 |
| 5 | 406 | 664 |
| 6 | 1172 | 1836 |
| 7 | 1394 | 3230 |
| 8 | 1405 | 4635 |
| 9 | 271 | 4906 |
| 10 | 97 | 5003 |
| 11 | 15 | 5018 |
| 12 | 17 | 5035 |
让我们对我们的睡眠变量进行这样的计算,计算绝对和累积频率。在图 3.3 的左面板中,我们绘制数据以查看这些表示是什么样子的;绝对频率值以实线绘制,累积频率以虚线绘制。我们看到累积频率是单调递增的 - 也就是说,它只能上升或保持不变,但它永远不会下降。同样,我们通常发现相对频率比绝对频率更有用;这些在图 3.3 的右面板中绘制。重要的是,相对频率图的形状与绝对频率图完全相同 - 只是值的大小发生了变化。

图 3.3:频率(左)和比例(右)的相对(实线)和累积相对(虚线)值的图,表示 SleepHrsNight 的可能值。
3.2.3 绘制直方图

图 3.4:NHANES 中年龄(左)和身高(右)变量的直方图。
我们上面检查的变量相当简单,只有几个可能的值。现在让我们看一个更复杂的变量:年龄。首先让我们绘制 NHANES 数据集中所有个体的年龄变量(见图 3.4 的左面板)。你在那里看到了什么?首先,你应该注意到每个年龄组中的个体数量随时间而减少。这是有道理的,因为人口是随机抽样的,因此随着时间的推移,死亡导致年龄较大的人口减少。其次,你可能会注意到图表中 80 岁年龄有一个很大的峰值。你觉得那是怎么回事?
如果我们查找 NHANES 数据集的信息,我们会看到年龄变量的以下定义:“研究参与者筛查时的年龄。注意:80 岁或以上的受试者记录为 80 岁。”这是因为相对较少的具有非常高年龄的个体可能会更容易识别数据集中的特定人物,如果你知道他们的确切年龄;研究人员通常承诺保护参与者的身份保密,这是他们可以帮助保护研究对象的事情之一。这也突显了了解数据的来源和处理方式总是很重要的;否则我们可能会错误地解释它们,认为 80 岁以上的人在样本中被过度代表了。
让我们看一下 NHANES 数据集中的另一个更复杂的变量:身高。身高值的直方图在图 3.4 的右面板中绘制。你应该注意到这个分布的第一件事是,它的大部分密度集中在大约 170 厘米左右,但分布在左侧有一个“尾巴”;有一小部分个体的身高要小得多。你觉得这里发生了什么?
你可能已经直觉到,小身高来自数据集中的儿童。一种检查这一点的方法是为儿童和成年人分别使用不同颜色绘制直方图(图 3.5 的左面板)。这显示了所有非常短的身高确实来自样本中的儿童。让我们创建一个只包括成年人的 NHANES 的新版本,然后仅为他们绘制直方图(图 3.5 的右面板)。在那个图中,分布看起来更对称。正如我们将在后面看到的,这是一个很好的正态(或高斯)分布的例子。

图 3.5:NHANES 身高直方图。A:分别绘制儿童(灰色)和成年人(黑色)的值。B:仅成年人的值。C:与 B 相同,但 bin 宽度=0.1
3.2.4 直方图箱
在我们早期关于睡眠变量的例子中,数据以整数报告,我们只是计算了报告每个可能值的人数。然而,如果你看一下 NHANES 中身高变量的一些值(如表 3.5 所示),你会发现它是以厘米为单位测量的,精确到小数点后一位。
表 3.5:NHANES 数据框中身高的一些值。
| 身高 |
|---|
| 169.6 |
| 169.8 |
| 167.5 |
| 155.2 |
| 173.8 |
| 174.5 |
图 3.5 的 C 面板显示了一个直方图,它计算了小数点后一位的每个可能值的密度。该直方图看起来非常不规则,这是因为特定小数位值的变异性。例如,值 173.2 出现了 32 次,而值 173.3 只出现了 15 次。我们可能不认为这两个身高的普遍性真的有这么大的差异;更有可能的是这只是由于我们样本中的随机变异性。
通常,当我们创建连续数据的直方图或者存在许多可能值的数据时,我们会对值进行分箱,这样我们不是计算和绘制每个特定值的频率,而是计算和绘制落入特定范围内的值的频率。这就是为什么在 3.5 的面板 B 中,图看起来不那么锯齿状;在这个面板中,我们将箱宽设置为 1,这意味着直方图是通过组合宽度为 1 的箱内的值来计算的;因此,值 1.3、1.5 和 1.6 都将计入相同箱的频率,该箱的范围从等于 1 的值到小于 2 的值。
请注意,一旦选择了箱宽,箱数就由数据确定:
箱数 = 分数范围 箱宽 箱数= \frac{分数范围}{箱宽} 箱数=箱宽分数范围
并没有硬性的规则来选择最佳的箱宽。有时会很明显(例如当只有少数可能的值时),但在许多情况下,这将需要反复试验。有一些方法可以自动找到最佳的箱尺寸,例如我们将在一些后续示例中使用的 Freedman-Diaconis 方法。
3.3 分布的理想化表示
数据集就像雪花一样,每一个都是不同的,但是仍然有一些模式在不同类型的数据中经常看到。这使我们能够使用数据的理想化表示来进一步总结它们。让我们以 3.5 中绘制的成年人身高数据为例,并将它们与一个非常不同的变量一起绘制:脉搏率(每分钟心跳次数),也是在 NHANES 中测量的(参见图 3.6)。

图 3.6:NHANES 数据集中身高(左)和脉搏(右)的直方图,每个数据集上都叠加了正态分布。
虽然这些图看起来肯定不完全相同,但它们都具有相对对称地围绕中间的圆形峰值的一般特征。事实上,当我们收集数据时,这种形状实际上是我们观察到的分布的常见形状之一,我们称之为正态(或高斯)分布。这个分布是用两个值(我们称之为分布的参数)来定义的:中心峰值的位置(我们称之为均值)和分布的宽度(用一个称为标准差的参数来描述)。图 3.6 显示了在每个直方图上方绘制的适当的正态分布。你可以看到,尽管曲线不完全符合数据,但它们在表征分布方面做得相当不错-只用两个数字!
正如我们稍后将在讨论中心极限定理时看到的那样,世界上许多变量呈现正态分布的形式有一个深刻的数学原因。
3.3.1 偏度
图 3.6 中的示例基本上符合正态分布,但在许多情况下,数据会以一种系统的方式偏离正态分布。数据偏离的一种方式是当它们是不对称的,使得分布的一个尾部比另一个更密集。我们称之为“偏度”。当测量被限制为非负时,偏斜通常发生,例如当我们在计数或测量经过的时间时(因此变量不能取负值)。
在旧金山国际机场安检等待时间的平均值中可以看到相对较小的偏斜,如图 3.7 的左面板所示。您可以看到,虽然大多数等待时间都不到 20 分钟,但也有一些情况下等待时间要长得多,超过 60 分钟!这是一个“右偏”分布的例子,右尾比左尾更长;当查看计数或测量时间时,这种情况很常见,因为它们不能小于零。看到“左偏”分布相对较少,但也可能发生,例如在查看不能大于一的分数值时。
右偏和长尾分布的例子。左:旧金山国际机场 A 航站楼安检等待时间的平均值(2017 年 1 月至 10 月),来源于 https://awt.cbp.gov/。右:3633 名个体的 Facebook 好友数量的直方图,来源于斯坦福大型网络数据库。拥有最多朋友的人用菱形表示。
图 3.7:右偏和长尾分布的例子。左:旧金山国际机场 A 航站楼安检等待时间的平均值(2017 年 1 月至 10 月),来源于awt.cbp.gov/。右:3633 名个体的 Facebook 好友数量的直方图,来源于斯坦福大型网络数据库。拥有最多朋友的人用菱形表示。
3.3.2 长尾分布
在历史上,统计学主要关注正态分布的数据,但有许多数据类型看起来与正态分布完全不同。特别是,许多现实世界的分布都是“长尾”的,意味着右尾远远超出了分布的最典型成员;也就是说,它们是极端偏斜的。长尾分布最有趣的数据类型之一来自对社交网络的分析。例如,让我们看一下斯坦福大型网络数据库中的 Facebook 好友数据,并绘制数据库中 3663 人的好友数量的直方图(见图 3.7 的右面板)。正如我们所看到的,这个分布有一个非常长的右尾 - 平均每个人有 24.09 个朋友,而拥有最多朋友的人(用蓝点表示)有 1043 个!
长尾分布在现实世界中越来越被认可。特别是,许多复杂系统的特征都以这些分布为特征,从文本中单词的频率,到不同机场进出的航班数量,再到大脑网络的连接性。长尾分布可能有多种形成方式,但一个常见的情况是所谓的“马太效应”:
因为凡有的,还要给他使他多有,并且还要使他充足;没有的,连他所有的也要夺过来。 — 马太福音 25:29,修订标准版
这经常被改述为“富者愈富”。在这些情况下,优势会累积,这样那些拥有更多朋友的人就能接触到更多新朋友,而那些拥有更多金钱的人则有能力做一些能增加他们财富的事情。
随着课程的进行,我们将看到几个长尾分布的例子,我们应该记住,当面对长尾数据时,统计学中的许多工具可能会失败。正如纳西姆·尼古拉斯·塔勒布在他的书《黑天鹅》中指出的那样,这种长尾分布在 2008 年的金融危机中发挥了关键作用,因为许多交易员使用的金融模型假设金融系统会遵循正态分布,而事实显然并非如此。
3.4 学习目标
阅读完本章后,您应该能够:
-
计算给定数据集的绝对、相对和累积频率分布
-
生成频率分布的图形表示
-
描述正态分布和长尾分布之间的区别,并描述通常导致每种分布的情况
3.5 建议阅读
- 黑天鹅:高度不太可能事件的影响,作者纳西姆·尼古拉斯·塔勒布
第四章:数据可视化
原文:
statsthinking21.github.io/statsthinking21-core-site/data-visualization.html译者:飞龙
协议:CC BY-NC-SA 4.0
1986 年 1 月 28 日,航天飞机挑战者号在起飞后 73 秒爆炸,造成机上 7 名宇航员全部遇难。与任何类似灾难发生时一样,对事故原因进行了官方调查,发现连接固体火箭助推器两个部分的 O 形圈泄漏,导致接头失效和大型液体燃料箱爆炸(见图 4.1)。

图 4.1:火箭助推器泄漏燃料的图像,在爆炸前几秒。火箭侧面可见的小火焰是 O 形圈失效的地方。由 NASA(NASA 描述中的伟大图像)[公有领域],通过 Wikimedia Commons
调查发现 NASA 决策过程的许多方面存在缺陷,特别关注 NASA 工作人员与承包商 Morton Thiokol 的工程师之间的会议,后者建造了固体火箭助推器。这些工程师特别担心,因为预测发射当天早上的温度将非常寒冷,并且他们拥有以往发射的数据,显示 O 形圈在较低温度下的性能受到影响。在发射前一晚的会议上,工程师向 NASA 经理展示了他们的数据,但未能说服他们推迟发射。他们的证据是一组手写幻灯片,显示了以往各次发射的数字。
可视化专家爱德华·图夫特认为,通过正确呈现所有数据,工程师们本可以更有说服力。特别是,他们可以展示类似于图 4.2 中的图表,突出显示了两个重要事实。首先,它显示 O 形圈损坏的程度(由以往飞行后从海洋中检索出的固体火箭助推器上发现的侵蚀和烟灰量定义)与起飞时的温度密切相关。其次,它显示了 1 月 28 日早上的预测温度范围(显示在阴影区)远超过了以往所有发射的范围。虽然我们无法确定,但这似乎至少是有可能更有说服力的。

图 4.2:图夫特损伤指数数据的重新绘制。线显示了数据的趋势,阴影区显示了发射当天早上的预测温度。
4.1 情节解剖
绘制数据的目标是以二维(偶尔是三维)的方式呈现数据集的摘要。我们将这些维度称为轴 - 水平轴称为X 轴,垂直轴称为Y 轴。我们可以沿着轴排列数据,以突出显示数据值。这些值可以是连续的,也可以是分类的。
我们可以使用许多不同类型的图来呈现数据,它们各有优缺点。假设我们对 NHANES 数据集中男性和女性身高差异感兴趣。图 4.3 展示了绘制这些数据的四种不同方式。
-
面板 A 中的条形图显示了均值的差异,但没有显示出围绕这些均值的数据有多大的波动 - 正如我们将在后面看到的那样,了解这一点对于确定我们是否认为两组之间的差异足够重要至关重要。
-
第二个图显示了所有数据点叠加在条形图上 - 这使得男性和女性身高的分布有些重叠更清晰,但由于数据点的数量很大,仍然很难看清楚。
通常我们更喜欢使用一种提供更清晰的数据点分布视图的绘图技术。
-
在面板 C 中,我们看到了一个小提琴图的例子,它绘制了每个条件下数据的分布(稍微平滑了一下)。
-
另一个选择是面板 D 中显示的箱线图,它显示了中位数(中心线)、变异性的度量(箱子的宽度,基于一个称为四分位距的度量),以及任何异常值(由线末端的点表示)。这两种方法都是有效的显示数据的方式,可以很好地了解数据的分布。

图 4.3:在 NHANES 数据集中绘制男性和女性身高差异的四种不同方式。面板 A 绘制了两组的均值,这样无法评估两个分布的相对重叠。面板 B 显示了相同的条形图,但也叠加了数据点,使它们可以看到它们的整体分布。面板 C 显示了小提琴图,显示了每个组的数据集的分布。面板 D 显示了一个箱线图,突出显示了分布的扩展以及任何异常值(显示为单独的点)。
4.2 良好可视化的原则
关于有效可视化数据已经写了很多书。大多数作者都同意一些原则,而其他一些原则则更有争议。在这里,我们总结了一些主要原则;如果你想了解更多,那么一些好的资源在本章末尾的“建议阅读”部分中列出。
4.2.1 展示数据并使其突出显示
假设我进行了一项研究,研究牙齿健康与使用牙线时间之间的关系,我想要可视化我的数据。图 4.4 展示了这些数据的四种可能呈现方式。
- 在面板 A 中,我们实际上没有显示数据,只是一条表达数据关系的线。这显然不是最佳选择,因为我们实际上看不到基础数据是什么样子。
面板 B-D 显示了绘制实际数据的三种可能结果,每个图显示了数据可能呈现的不同方式。
-
如果我们在面板 B 中看到这个图,我们可能会感到怀疑 - 真实数据很少会遵循如此精确的模式。
-
另一方面,面板 C 中的数据看起来像是真实数据 - 它们显示了一个一般的趋势,但是杂乱无章,就像世界上的数据通常一样。
-
面板 D 中的数据告诉我们,两个变量之间的明显关系仅仅是由一个个体引起的,我们称之为离群值,因为它们远远超出了群体的模式。很明显,我们可能不希望从一个由一个数据点驱动的效应中得出太多结论。这个图强调了在对数据进行任何总结之前,查看原始数据是非常重要的。

图 4.4:牙齿健康示例的四种不同可能的数据呈现。散点图中的每个点代表数据集中的一个数据点,每个图中的线代表数据的线性趋势。
4.2.2 最大化数据/墨水比
Edward Tufte 提出了一个叫做数据/墨水比的概念:
数据 / 墨水比例 = 数据上使用的墨水量 总墨水量 数据/墨水比例 = \frac{数据上使用的墨水量}{总墨水量} 数据/墨水比例=总墨水量数据上使用的墨水量
这样做的目的是最大限度地减少视觉杂乱,让数据显示出来。例如,看一下图 4.5 中牙齿健康数据的两种呈现。两个面板显示相同的数据,但面板 A 更容易理解,因为它的数据/墨水比例相对较高。

图 4.5:使用两种不同数据/墨水比例绘制相同数据的示例。
4.2.3 避免图表垃圾
在流行媒体中,经常会看到数据呈现的演示,这些演示装饰有许多与内容主题相关但与实际数据无关的视觉元素。这被称为图表垃圾,应该尽一切可能避免。
避免图表垃圾的一个好方法是避免使用流行的电子表格程序来绘制数据。例如,图 4.6 中的图表(使用 Microsoft Excel 创建)绘制了美国不同宗教的相对流行程度。这个图有至少三个问题:
-
它在每个条形上叠加了与实际数据无关的图形。
-
它有分散注意力的背景纹理
-
它使用了三维条形图,扭曲了数据

图 4.6:图表垃圾的示例。
4.2.4 避免扭曲数据
通常可以利用可视化来扭曲数据集的信息。一个非常常见的方法是使用不同的轴缩放来夸大或隐藏数据的模式。例如,假设我们有兴趣看看美国的暴力犯罪率是否有变化。在图 4.7 中,我们可以看到这些数据以使犯罪率看起来保持不变或暴跌的方式绘制。相同的数据可以讲述两个完全不同的故事!

图 4.7:1990 年至 2014 年的犯罪数据随时间的变化。面板 A 和 B 显示相同的数据,但 Y 轴上的值范围不同。数据来源于www.ucrdatatool.gov/Search/Crime/State/RunCrimeStatebyState.cfm
统计数据可视化中的一个主要争议是如何选择 Y 轴,特别是是否应该始终包括零。在他著名的书《如何用统计数据撒谎》中,达雷尔·赫夫坚决主张 Y 轴上应始终包括零点。另一方面,爱德华·图夫特提出了相反的观点:
“总的来说,在时间序列中,使用一个显示数据而不是零点的基线;不要花费大量的空白垂直空间来达到零点,以掩盖数据线本身的情况。”(来自
qz.com/418083/its-ok-not-to-start-your-y-axis-at-zero/)
当然,有些情况下使用零点根本毫无意义。比如,我们有兴趣绘制个体随时间的体温。在图 4.8 中,我们绘制了相同(模拟的)数据,带有或不带有 Y 轴上的零点。显然,通过在 Y 轴上绘制这些数据(面板 A),我们在图中浪费了很多空间,因为一个活人的体温永远不可能降到零!通过包括零点,我们也使得第 21-30 天的温度变化不那么明显。总的来说,我倾向于在线图和散点图中使用图表中的所有空间,除非零点真的很重要需要突出。

图 4.8:随时间变化的体温,带有或不带有 Y 轴上的零点绘制。
爱德华·图夫特引入了“谎言因素”的概念,用来描述可视化中的物理差异与数据差异的大小程度。如果一个图形的谎言因素接近 1,那么它就适当地代表了数据,而远离 1 的谎言因素反映了对基础数据的扭曲。
谎言因素支持了在许多情况下应该始终在条形图中包括零点的观点。在图 4.9 中,我们绘制了相同的数据,带有或不带有 Y 轴上的零点。在面板 A 中,两个条之间的面积比例差与数值之间的比例差完全相同(即谎言因素=1),而在面板 B 中(不包括零点),两个条之间的面积比例差大约是数值之间的比例差的 2.8 倍,因此在视觉上夸大了差异的大小。

图 4.9:带有相关谎言因素的两个条形图。
4.3 容纳人类的局限性
人类既有感知限制又有认知限制,这些限制可能会使得一些可视化图表非常难以理解。在构建可视化图表时,牢记这些限制总是很重要的。
4.3.1 感知限制
许多人(包括我自己)面临的一个重要感知限制是色盲。这可能会使得很难感知图中的信息(比如图 4.10中的图),其中元素之间只有颜色对比而没有亮度对比。使用在亮度和/或纹理上有显著差异的图形元素总是有帮助的,除了颜色。许多可视化工具也提供了“色盲友好”的调色板。

图 4.10:仅依赖颜色对比的糟糕图例。
即使对于色觉完美的人来说,也存在感知限制,这可能使一些图表无效。这就是统计学家永远不使用饼图的原因:人类很难准确地感知形状的体积差异。图 4.11 中的饼图(呈现了我们上面展示的宗教信仰数据)展示了这一点有多棘手。

图 4.11:饼图的一个例子,突出了理解不同饼片的相对体积的困难。
这个图表有几个糟糕的地方。首先,它需要区分底部的大量颜色小块。其次,视觉透视扭曲了相对数量,使得天主教的饼块看起来比无信仰的饼块大得多,而实际上无信仰的数量略大(22.8%对 20.8%),正如在图 4.6 中所显示的那样。第三,通过将图例与图形分开,它要求观察者在工作记忆中保存信息,以便在图形和图例之间进行映射,并进行许多“表格查找”,以便不断地将图例标签与可视化相匹配。最后,它使用的文本太小,使得在不放大的情况下无法阅读。
使用更合理的方法绘制数据(图 4.12),我们可以更清楚地看到模式。这个图表可能看起来不像使用 Excel 生成的饼图那样引人注目,但它是数据更有效和准确的表现。

图 4.12:宗教信仰数据的更清晰呈现(来源于http://www.pewforum.org/religious-landscape-study/)。
这个图表允许观察者基于一个共同的比例尺(y 轴)来进行比较。人类倾向于更准确地解读基于这些感知元素的差异,而不是基于面积或颜色。
4.4 考虑其他因素的修正
通常我们对绘制的数据感兴趣,其中感兴趣的变量受到除我们感兴趣的变量之外的其他因素的影响。例如,假设我们想了解汽油价格随时间的变化。图 4.13 显示了历史汽油价格数据,无论是否考虑通货膨胀进行调整。尽管未经调整的数据显示了巨大的增长,但经过调整的数据表明这主要是通货膨胀的反映。其他需要调整数据以考虑其他因素的例子包括人口规模和跨不同季节收集的数据。

图 4.13:美国 1930 年至 2013 年的汽油价格(取自http://www.thepeoplehistory.com/70yearsofpricechange.html),是否考虑通货膨胀进行修正(基于消费者价格指数)。
4.5 学习目标
阅读完本章后,您应该能够:
-
描述区分好坏图表的原则,并使用它们来识别好坏图表。
-
了解必须适应的人类局限,以制作有效的图表。
-
承诺永远不要制作饼图。永远。
4.6 建议阅读和视频
-
数据可视化基础,作者克劳斯·威尔克
-
《视觉解释》,作者爱德华·图夫特
-
《数据可视化》,作者威廉·S·克利夫兰
-
《眼睛和心灵的图表设计》,作者斯蒂芬·M·科斯林文章来源:https://www.toymoban.com/news/detail-799976.html
-
人类如何看待数据,作者约翰·劳塞尔文章来源地址https://www.toymoban.com/news/detail-799976.html
到了这里,关于斯坦福 Stats60:21 世纪的统计学:前言到第四章的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!