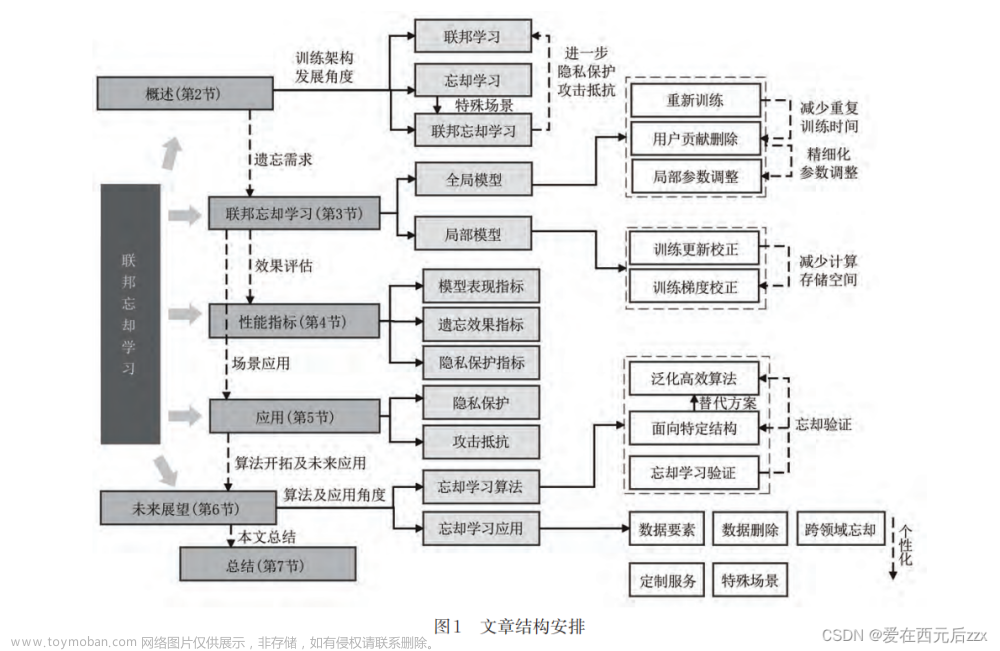
Accurate Decentralized Application Identification via Encrypted Traffic Analysis Using Graph Neural Networks
中文题目:通过使用图神经网络的加密流量分析来准确地识别分散应用程序
发表期刊:IEEE Transactions on Information Forensics and Security
发表年份:2021-1-4
作者:Meng Shen , Jinpeng Zhang, Liehuang Zhu , Ke Xu ,Xiaojiang Du
latex引用:
@article{shen2021accurate,
title={Accurate decentralized application identification via encrypted traffic analysis using graph neural networks},
author={Shen, Meng and Zhang, Jinpeng and Zhu, Liehuang and Xu, Ke and Du, Xiaojiang},
journal={IEEE Transactions on Information Forensics and Security},
volume={16},
pages={2367--2380},
year={2021},
publisher={IEEE}
}
摘要
去中心化应用程序(DApps)越来越多地开发和部署在以太坊等区块链平台上。DApp指纹识别可以通过分析产生的网络流量来识别用户对特定DApp的访问,揭示用户的许多敏感信息,如他们的真实身份、财务状况和宗教或政治偏好。部署在同一平台上的dapp通常采用相同的通信接口和类似的流量加密设置,从而使产生的流量区别并不是那么大。现有的加密流量分类方法要么需要手工制作和微调功能,要么精度较低。
如何准确高效地进行DApp指纹识别仍然是一项具有挑战性的任务。在本文中,我们提出了GraphDApp,一种使用图神经网络(GNNs)的新型DApp指纹识别方法。我们提出了一种名为流量交互图(Traffic Interaction graph, TIG)的图结构,作为加密DApp流的信息丰富表示,它在双向客户端-服务器交互中隐式地保留了多维特征。利用TIG技术,将DApp指纹识别问题转化为图形分类问题,设计了一个功能强大的基于gnn的分类器。
我们从1300个dapp收集了超过16.9万流量的真实流量数据集。实验结果表明,在封闭和开放两种真实世界场景下,GraphDApp的分类准确率都优于其他最先进的方法。此外,GraphDApp应用于传统的移动应用分类时,仍然保持了较高的准确率。
存在的问题
-
虽然区块链技术可以潜在地保护DApp用户的身份隐私。但个人用户访问DApps时产生的网络流量仍然会泄露大量用户的敏感信息。
- 被动攻击者(例如,校园网管理员、住宅网络服务提供商或恶意窃听者)可以通过分析产生的网络流量来进行DApp指纹识别,以识别用户访问的特定DApp。
- 敌手可以从用户对赌博dapp的使用情况推断出他们的财务状况,或者从他们对社交dapp的访问中了解他们的宗教偏好和政治观点。
- DApp指纹识别还可以由调控器进行,用以去匿名化DApp用户,甚至阻止对某些DApp的访问,而不影响对同一平台(例如以太坊)上其他DApp的访问。
-
与常规的移动应用程序或网站不同,部署在以太坊上的dapp实现了相同的前端接口,采用类似的SSL/TLS协议设置,并共享相同的去中心化区块链网络来运行后端代码和管理数据。因此,不同dapp的流量具有许多共同特征,导致现有使用SSL/TLS报文标志,或报文长度统计的指纹识别方法精度较低(章节IV-A)。
-
效率也是构建DApp指纹方法的重要因素。现有的使用机器学习分类器的研究通常采用手工制作的特征,甚至需要计算密集型的特征处理。
-
使用深度神经网络的方法一般采用数据包方向序列或数据包长度序列作为输入,表达性不够,无法达到较高的准确率。
总结:
- 用户访问DApps时产生的网络流量会泄露大量用户的敏感信息
- 不同dapp的流量具有许多共同特征,导致现有使用SSL/TLS报文标志,或报文长度统计的指纹识别方法精度较低
- 由于需要手工提取特征,同时需要计算密集型的特征处理,现有的机器学习方法的效率低。
- 深度神经网络的方法一般采用数据包方向序列或数据包长度序列作为输入,表达性不够,无法达到较高的准确率。
论文贡献
- 提出流量交互图(TIG)来表示每个单独的加密流,其中TIG中的顶点表示包,边表示一对客户端和服务器之间的包级交互。我们还提供了量化的措施,以证明使用TIG表示流比传统的包长度序列的优势。
- 设计了GraphDApp模型,这是一个使用多层感知(MLPs)和全连接层的强大的基于GNN的分类器。它将不同DApp流的TIG映射到嵌入空间中的不同表示,不需要手工制作的特征,从而可以有效准确地进行分类。
- 收集了以太坊上1300个dapp的真实流量数据集,流量超过16.9万。我们展示了GraphDApp在封闭和开放环境下的准确性和效率。与最先进的方法相比,GraphDApp的分类准确率最高,训练时间最短。此外,它也适用于传统的移动应用分类。
论文解决上述问题的方法:
- 特征表达:提出流量交互图(TIG)作为加密DApp流的信息丰富表示
- 准确率:设计了GraphDApp模型来提高准确率
- 效率:GraphDApp模型将不同DApp流的TIG映射到嵌入空间中的不同表示,不需要手工制作的特征
论文的任务:
- 封闭情景:实现DApps的多分类
- 开放情景:实现DApps的二分类(正常、恶意)
1. 背景 / 威胁模型
- DApp的相关知识
-
以太坊上的大多数dapp都提供浏览器插件,以便通过浏览器(例如Chrome)访问它们。DApp的前端实现了以太坊统一定义的用户界面来呈现页面。后端是连接到以太坊区块链网络的智能合约。这与连接到集中式数据库的web应用程序完全不同。
-
智能合约是决定客户端在DApp中执行的每个操作的结果的功能。
-
客户端与区块链平台之间的传输数据采用SSL/TLS协议加密。主要有两个层:握手层和记录层。前者用于协商SSL/TLS会话的安全参数,后者负责在安全参数下传输加密数据。
-
与传统的移动和web应用程序不同,以太坊上的dapp实现了相同的前端接口,在SSL/TLS实现中采用类似的设置,运行其后端代码并将其数据存储在相同的去中心化区块链网络中。这些共同的特征使得不同DApp的结果流量不那么具有区分度。
-
威胁模型

DApps在以太坊上工作流程:- 初始化访问,DApp客户端向配备相应智能合约设备的服务器发送请求
- 操作和结果的所有数据记录都由矿工在底层区块链平台上以块的形式打包,并存储在分布式账本上
- 客户端还从智能合约服务器获得区块链服务器列表,通过该列表,客户端可以从账本中获取更新的信息,以呈现网页。
-
相关工作

2. DApp流的图结构
-
流量互动图(Traffic Interaction Graph,TIG)
- 对所有流量包按照流(即相同五元组)进行分流。
- 对每个流按照下图进行拆解:
- 橙色箭头:客户端 -> 服务器(上行报文数量):用 “-报文长度” 表示
- 蓝色箭头:服务器 -> 客户端(下行报文数量):用 “报文长度” 表示
- 灰色区域:SSL/TLS协议的握手阶段(建立连接)
- 白色区域:SSL/TLS协议的记录阶段(传送加密报文)

- 构建TIG图
TIG图:TIG = (V, E, L)
- V(顶点集合):一个流中的所有数据包
- E(边集合):一个流中的所有边集合
-
突发内边缘:依次连接每个突发中的连续顶点(即数据包)
例如:(-330,-140),(-140,-118) -
突发间边缘:用于连接一个突发与其前一个突发。每个突发中的第一个顶点和最后一个顶点连接到其前一个突发中相应的第一个顶点和最后一个顶点
例如:(1142,-330),(1514,-118)
- L(顶点权值集合):非零整数集合,记录了数据包的长度和方向。

- TIG的优势
- 包方向信息:方向信息由TIG中顶点的符号显示,其中正值表示下行数据包,负值表示上行数据包
- 数据包长度信息:数据包长度信息是用于加密流分类的关键特性。
- 报文突发信息:TIG中同一层的顶点表示组成单个突发的数据包。不同应用程序的突发级行为可能有很大差异,因此可以作为分类器学习的鉴别特征。
- 包排序信息:TIG可以表示从SSL/TLS会话开始协商到应用程序数据传输结束的报文顺序。此外,TIG还反映了服务器和客户端之间的交互。
定量的方法证明TIG比其他表示法更具信息量:
度量包长度序列的欧氏距离、TIG的图编辑距离以表示各个流之间的相似度差别
- 从40个dapp中每个随机选择100个流,并计算流的成对距离。在计算图编辑距离时,遵循节点替换代价设置为欧氏距离,节点插入和删除代价设置为90,边缘插入和删除代价设置为15。
- 对于每个DApp,蓝色标记表示同一DApp中流量之间的平均距离(即类内距离);每个箱线图表示与其他DApp之间的典型距离(即类间距离,最大值、第75百分位、第50百分位、第25百分位、最小值)。对比图4(a)和图4(b),我们可以得到以下观察结果:
- 对于包长度序列,只有4个dapp的类内距离小于类间距离的最小值;而TIG使21个dapp具有此属性。
- 在包长度序列中,类内距离大于类间距离中位数(即第50百分位)的dapp有15个;而TIG只有1个这样的情况。
通过定量测量,我们证明了基于tig的表示对于相同DApp的流程具有很高的相似性,并且在不同DApp之间更具区分度。
3. GraphDApp


-
GNN Architecture
给定一组 T I G = { G 1 , … , G N } ⊆ G TIG = \{G_1,…,G_N\}⊆G TIG={G1,…,GN}⊆G及其标签 { y 1 , … , y N } ⊆ Y \{y_1,…,y_N\}⊆Y {y1,…,yN}⊆YGNN的目标是学习一个可以预测每个 TIG 的标签的表示向量 h G h_G hG ,即: y N ^ = g ( h G ) \hat {y_N} = g(h_G) yN^=g(hG)
GraphDApp中使用的GNN主体由mlp和全连接层组成,其中mlp用于从tig中提取特征进行训练,而全连接层用于做出分类决策。
- MLP:学习每个 TIG 的表示向量 h G h_G hG。每个节点 v ∈ G v∈G v∈G 的特征向量 h v h_v hv 是通过聚集其邻居的特征来计算的。这样,特征向量 h v h_v hv 就可以存储图中相邻节点的特征信息
- 全连接层:用于分类,使用一个全连接层 + softmax
- 损失函数:使用交叉熵损失
- 优化器:Adam
-
MLPs的设计
- 为了将不同的图映射到不同的表示,GNN应该有一个单射邻居聚合方法。节点特征向量的更新方法表示为: h v ( k ) = ϕ ( h V ( k − 1 ) , f ( { h u ( k − 1 ) : u ∈ N ( v ) } ) ) h_v^{(k)} = \phi(h_V^{(k-1)},f(\{h_u^{(k-1)}: u \in N(v)\})) hv(k)=ϕ(hV(k−1),f({hu(k−1):u∈N(v)}))
- 应用到MLP上,公式可具体化为: h v k = M L P k ( ( 1 + ϵ ( k ) ) ⋅ h v ( k − 1 ) + ∑ u ∈ N ( v ) h u ( k − 1 ) ) h_v^k = MLP^k((1+\epsilon^{(k)}) · h_v^{(k-1)} + \sum_{u \in N(v)}h_u^{(k-1)} ) hvk=MLPk((1+ϵ(k))⋅hv(k−1)+u∈N(v)∑hu(k−1))
- 图的特征表示向量的生成方法如下: h G = C o n ( R e a d o u t ( { h v ( k ) ∣ v ∈ G } ) ∣ k ∈ [ 0 , K ] ) h_G = Con(Readout(\{h_v^{(k)}|v \in G\})|k \in [0,K]) hG=Con(Readout({hv(k)∣v∈G})∣k∈[0,K])
-
模型总结
- 输入层:TIG图
- n * 隐藏层:linear & BatchNorm & dropout
- 合并层:各个隐藏层中所有节点的embedding进入Readout + concat层,输出整个图的embedding

- 输出层:linear & softmax
4. 实验评估
-
基线模型
- 马尔可夫模型:它使用马尔可夫链来建模SSL/TLS会话中的消息类型序列,并将状态转换特征输入机器学习分类器。最大似然原理用于识别生成加密流的应用程序[15]。
- AppScanner (APPS):用于从报文序列中捕获统计特征,如入报文、出报文、双向报文的均值、最小值、最大值、标准差等。它使用随机森林分类器来识别来自移动应用程序[27]的加密或未加密流量。
- 特征融合(FEAF):这是我们之前的会议文章[25]中提出的方法。它通过内核函数融合了不同的维度特征(例如,数据包长度、突发、数据包时间戳),并使用随机森林分类器来识别来自dapp的加密流。
- DeepFingerprinting (CNN+D):利用数据包方向信息构建卷积神经网络(Convolutional Neural Networks, CNN),对不同网站[26]的加密流量进行分类。
- CNN+L:使用与CNN+D相同的CNN结构,但将数据包长度序列作为输入来构建分类器。
- LSTM+L:以数据包长度序列为输入,使用双层LSTM[19]学习特征表示,使用全连接层进行分类。
-
实验设置
- 英特尔酷睿双核3.60GHz和16GB内存的服务器
- 封闭和开放情景:
- 封闭情景:攻击者的目标是识别受害者对某个被监控dapp集合的访问,这可以被视为一个多分类问题。
- 开放情景:考虑了一个更现实的场景,受害者不仅访问受监控的dapp,还访问大量不受监控的dapp。目标是从未监控的dapp中识别受监控的dapp,这通常被视为二分类问题。
-
数据集
- 数据收集:网络流量捕获工具部署在中国不同大学校园实验室的路由器上。当用户在pc上使用Chrome浏览器访问某个DApp时,产生的网络流量会被WireShark捕获并保存在数据服务器上。所有的访问都使用Chrome,因为它是一些dapp指定的浏览器。将网络流导出为CSV (Comma Separated Value)文件,每行包含从报文中获取的信息,包括时间、源/目的IP地址、端口、协议、报文长度、TCP/IP标志。每个包的加密有效载荷不用于分类。
-
为了构建封闭世界数据集,我们选择以太坊上拥有最多用户的前40个dapp作为监控dapp。这些类别包括社交应用、金融、网上购物等。表III总结了每个被监测的DApp的流量数量。我们总共收集了155,500个流量。

-
为了构建开放世界评估的后台流量,我们随机选择以太坊上的1260个dapp作为不受监控的dapp,总共收集了14000个流量。按照文献中的策略,每个不受监控的DApp只被访问一次。
- 数据训练与测试:采用10倍交叉验证的方法来评价每种方法的性能。我们将数据集随机分为10个相互排斥的相似大小的子集。然后,我们进行了10次训练和测试,每次使用9个子集作为训练集,其余1个子集作为测试集。10次测试的平均值作为最终结果。
-
GraphDApp参数调优
- 超参数设置:

-
epoch:训练轮数对模型训练时间、准确率、训练集和测试集的差距(判定是否过拟合)的影响

从表中可以看出模型只训练了一轮,就达到了0.8305的准确率,由此可知模型收敛速度很快。当epoch=10时,准确率增加并不明显,而训练时间显著增加,因此采用epoch=10作为最优轮数。
-
数据包数量:每个流使用的数据包数量对特征提取时间(fet),分类器训练时间(ctt)和graphdapp准确性的影响

当只使用每个流的前6个数据包时,GraphDApp的准确率可以达到0.8532。随着截获包数的增加,FET和CTT都相应变大,但增长趋势不同:FET增长放缓,CTT增长加快,这是因为包数越多,tig就越复杂,在分类器训练阶段学习它们的表示需要更多的时间。同时,提供更多的包来构造tig,也提高了精度。我们将数据包数设置为25,以在适度的时间开销下获得更高的精度。
-
数据集规模:数据规模对特征提取时间(fet)、分类器训练时间(ctt)和graphdapp准确性的影响

仅使用20%样本的情况下可以达到0.8764的准确率,这表明它可以从有限的训练数据中学习到足够的图表示。当提供更多的训练样本时,GraphDApp可以进一步提高准确率。一个有趣的观察是,更大的数据集并不会导致CTT的显著增加,这表明图表示学习并没有受到冗余tig的严重影响。在接下来的实验中,除非另有说明,否则我们使用表III中的整个数据集。
- 超参数设置:
-
封闭情景的评估



-
开放情景的评估




5. 移动应用识别评价
虽然GraphDApp的设计目的是识别特定dapp的加密流量,但它仍然适用于移动应用程序的分类,这是最近研究非常感兴趣的。为了评估GraphDApp在移动应用分类上的泛化性,我们使用我们之前工作中的数据集进行了实验。该数据集包含15个流行移动应用程序的加密流量,如Facebook、Twitter和支付宝。注意,只涉及下游流。

总结
论文内容
-
学到的方法
理论上的方法:
- 测试提出的图构建效果比其他的特征好的方法,可以采用量化的方法(由于本文的任务是DApp指纹识别,因此需要每个DApp产生的流尽可能相似,因此采用了图编辑距离来度量构建的图所表示的流的相似度的方式)(原文:III-C,本文:论文贡献-2-3)
-
论文优缺点
优点:
- 研究对象为现有研究较少的DApp的指纹识别
- 构件图的方法很值得借鉴:
- 包方向信息:方向信息由TIG中顶点的符号显示,其中正值表示下行数据包,负值表示上行数据包
- 数据包长度信息:数据包长度信息是用于加密流分类的关键特性。
- 报文突发信息:TIG中同一层的顶点表示组成单个突发的数据包。不同应用程序的突发级行为可能有很大差异,因此可以作为分类器学习的鉴别特征。
- 包排序信息:TIG可以表示从SSL/TLS会话开始协商到应用程序数据传输结束的报文顺序。此外,TIG还反映了服务器和客户端之间的交互。
缺点:文章来源:https://www.toymoban.com/news/detail-799997.html
- h v h_v hv的初始化不太清楚是怎样的,只包含包的大小(带方向)这个特征吗?
- 模型的细节描述的不太到位,比如Readout函数使用的是哪个。
- GraphDApp需要相对较长的时间来标记未知流。可以通过适当减少tig中的包数来缩短特征提取时间,减少MLP层数和隐藏单元来加快预测速度。
- 作为指纹识别方案,当应用程序的指纹发生变化时,精度会相应降低。为了解决这个问题,我们可以定期更新应用程序的tig,并微调分类器中的参数。
-
创新想法文章来源地址https://www.toymoban.com/news/detail-799997.html
- 除了DApp,还可以在其他的一些新型应用上尝试一些比较好的模型,以用于指纹识别
- 构造TIG时,除了数据包长度信息,是否可以使用其他的特征或添加其他的特征(这些特征都是有利于加密流量分类的,可以先通过特征筛选或者其他论文中提到的比较重要的特征)
- 可以通过使用GCN模型来提取用分类的每个流的embedding,后面再跟全连接层进行分类
- 本文由于实验对象为DApp,因此只在Chrome浏览器上进行了流量抓取。可以考虑不同的浏览器上效果是否不同。
- 设计的模型要适应于应用程序的指纹发生变化的情况。即概念漂移。
工具
- wireshark
数据集
- 私有数据集:手动收集
到了这里,关于【研究型论文】Accurate Decentralized Application Identification via Encrypted Traffic Analysis Using GNN的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!