这是一篇 ICCV 2023 的文章,主要介绍的是用自监督的方式进行多帧超分的学习
Abstract
这篇文章介绍了一种基于自监督的学习方式来进行多帧超分的任务,这种方法只需要原始的带噪的低分辨率的图。它不需要利用模拟退化的方法来构造数据,而且模拟退化的方法又可能存在域差异的问题,可能无法匹配真实场景下的图像分布。另外,它也不同于那种同时拍摄手机和高清单反的弱配对的方法,弱配对的方法,需要进行实际的数据的采集,无法实现大规模的数据构造,而且也不用担心会出现手机与单反的颜色差异问题。为了避免模拟退化以及采集数据对的这些问题,文章提出利用自监督学习的方法,从低清带噪图像中直接学习超分模式。文章作者也说,这个方法对动态场景也很鲁棒,而且实验结果也表明,这个自监督学习的方法,相比有监督,或者弱监督的方法,效果也是不相上下的。
Method
这篇文章的出发点,建立于以下的观测,一组低清带噪图像,可以看做是一张高清图像的采样,考虑到手持拍摄时的相机抖动,这组低清图可以看成是对高清图微小邻域的采样,存在一定的信息互补。如下图所示:

接下来详细介绍文章的方法,给定一组 N N N 张低清带噪图像, B = { b i } i = 1 N B=\{b_i\}_{i=1}^{N} B={bi}i=1N,将其分成两部分,一部分是 B m o d e l = { b i } i = 1 K B_{model}=\{b_i\}_{i=1}^{K} Bmodel={bi}i=1K,这部分用于模型预测高清图像,另外一部分是 B u n s e e n = { b i } i = K + 1 N B_{unseen}=\{b_i\}_{i=K+1}^{N} Bunseen={bi}i=K+1N,用来构建自监督训练的损失函数。首先,第一部分,通过一个 SR 模型,可以获得一张高清图像, y ^ = f ( B m o d e l ) \hat{y} = f(B_{model}) y^=f(Bmodel),然后,基于这张预测得到的高清图像 y ^ \hat{y} y^,再经过一个模拟退化过程,得到一个低清图像:
b i ^ = ∏ m i , k ( f ( B m o d e l ) ) (1) \hat{b_i} = \prod_{m_i, k}(f(B_{model})) \tag{1} bi^=mi,k∏(f(Bmodel))(1)
$ \prod_{m_i, k}$ 表示了一个退化流程,将高清图像经过配准,模糊,以及采样,得到一张低清图像:
∏ m i , k ( y ) = H D k Φ m i ( y ) (2) \prod_{m_i, k}(y) = HD_{k}\Phi_{m_i}(y) \tag{2} mi,k∏(y)=HDkΦmi(y)(2)
Φ m i \Phi_{m_i} Φmi 表示为了补偿相机抖动所做的配准操作, D k D_k Dk 表示模拟镜头的模糊, H H H 表示采样操作。模拟退化的结果与真实的低清图进行比较,计算损失函数:
L = 1 N − K ∑ i = K + 1 N ∥ b i − ∏ m i , k ( f ( B m o d e l ) ) ∥ 1 (3) \mathcal{L} = \frac{1}{N-K} \sum_{i=K+1}^{N} \left \| b_i - \prod_{m_i, k}(f(B_{model})) \right \|_{1} \tag{3} L=N−K1i=K+1∑N bi−mi,k∏(f(Bmodel)) 1(3)
整体的流程如下所示:
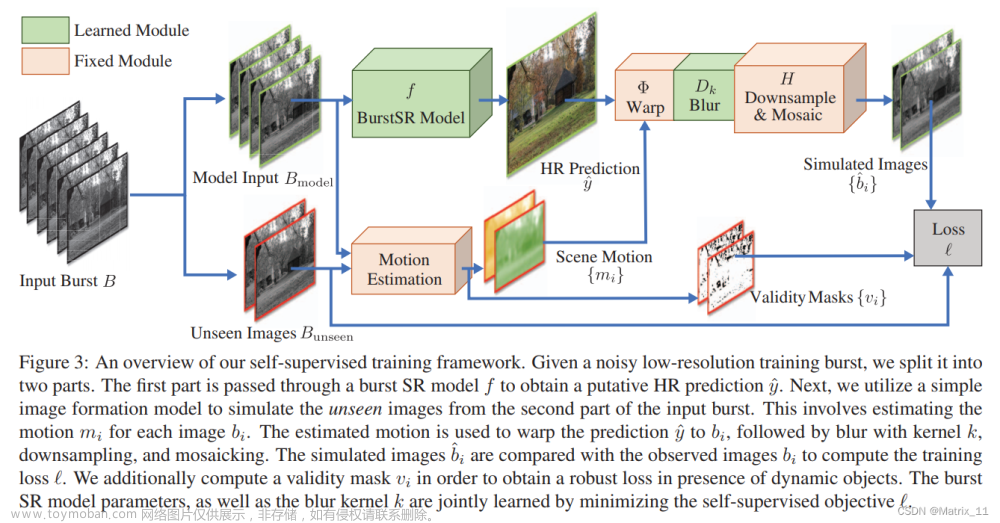
从文章介绍的方法来看,这个思路还是比较直观的,从任务来看,这是一个多帧超分的任务,那么输入必然是多帧带噪的低清图,输出必然有高清图,然后要实现自监督学习,那么既然高清图没有 GT,那就得换个方法,将实际的低清图做监督,为了能得到预测的低清图,所以需要在超分模型后面,再接一个退化模拟的过程,这个退化模拟过程只是为了训练的时候用,实际预测的时候,还是只有那个超分模型。
Motion Estimation
在实际场景中,由于手持相机的抖动,多帧之间存在运动偏差,这些运动偏差是多帧信息存在互补,可以融合的前提,但是也带来了配准的问题,这篇文章将多帧之间的运动信息,用一个像素级的稠密光流场来表示,文章中也提到用一个离线训好的 PWC-Net 来做帧间配准。考虑到,直接计算高清图像 y y y (RGB) 与低清带噪图像 b b b (RAW) 之间的配准,可能存在颜色差异的问题,所以文章中计算的是低清图像 b b b 之间的运动信息,因为 y y y 与 b 1 b_1 b1 对齐,而如果其它帧也与 b 1 b_1 b1 对齐,那么 y y y 与其它帧也是对齐的。
考虑到真实场景的复杂性,比如噪声,场景中物体的运动等,多帧之间的配准也不是全部都有效,有些区域的配准可能是错误的,为了剔除这些错误区域的配准,提升融合的鲁棒性及效果,文章中还设置了一个二值化的 mask,这个 mask 可以帮助模型识别哪些区域的配准正确的,哪些区域是配准错误的,结合这个 mask 的引导,可以让图像的融合更为准备。这个 mask 的计算基本是基于求差结合形态学的滤波实现。最终的损失函数是如下所示:
L = 1 N − K ∑ i = K + 1 N ∥ v i ⊙ ( b i − ∏ m i , k ( f ( B m o d e l ) ) ) ∥ 1 (4) \mathcal{L} = \frac{1}{N-K} \sum_{i=K+1}^{N} \left \| v_{i} \odot (b_i - \prod_{m_i, k}(f(B_{model}))) \right \|_{1} \tag{4} L=N−K1i=K+1∑N vi⊙(bi−mi,k∏(f(Bmodel))) 1(4)
Blur Kernel Estimation
模糊核的估计,文章中是通过学习的方法,将模糊核设置成一个可学习的模块,通过大量的数据学习模糊核的参数,这个模糊核的大小文章中指定了是 9 × 9 9 \times 9 9×9 的。
最后是实验展示部分,从文章展示的效果来看,比一些模拟退化或者弱监督的方法还要好。文章来源:https://www.toymoban.com/news/detail-800005.html

 文章来源地址https://www.toymoban.com/news/detail-800005.html
文章来源地址https://www.toymoban.com/news/detail-800005.html
到了这里,关于论文阅读 Self-Supervised Burst Super-Resolution的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!