决策树:理解机器学习中的关键算法
决策树是一种流行而强大的机器学习算法,它从数据中学习并模拟决策过程,以便对新的未知数据做出预测。由于其直观性和易理解性,决策树成为了分类和回归任务中的首选算法之一。在本文中,我们将深入探讨决策树的工作原理、如何构建决策树、它们的优缺点,以及在现实世界中的应用。
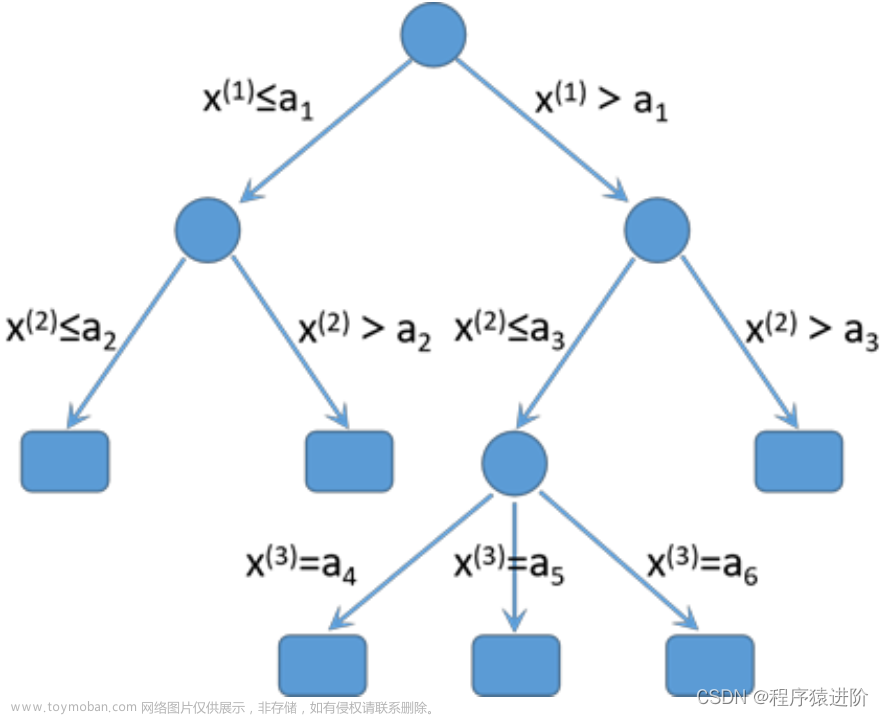
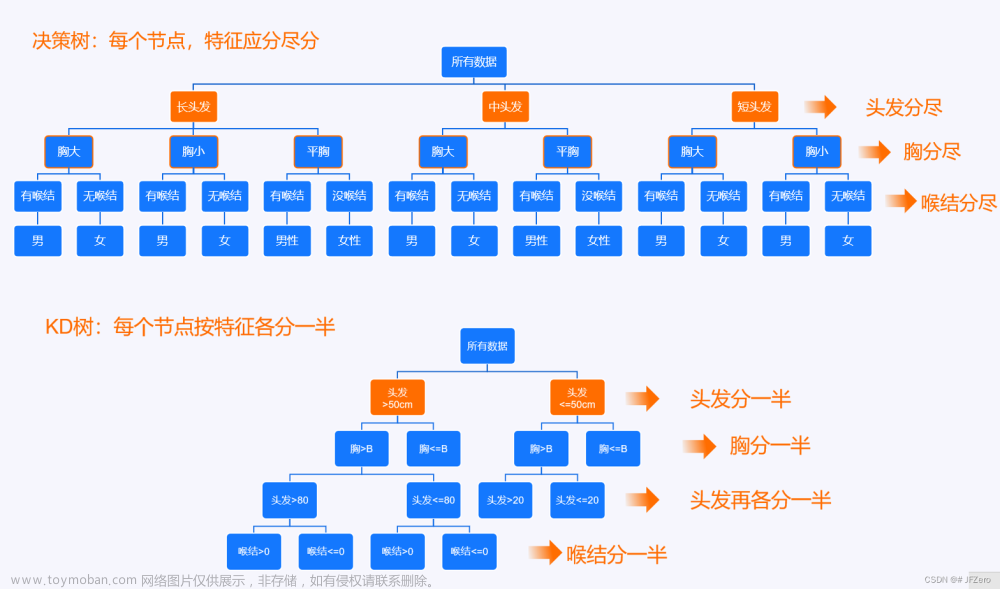
树模型
决策树:从根节点开始一步步走到叶子节点(决策)
所有的数据最终都会落到叶子节点,既可以做分类也可以做回归
树的组成
根节点:第一个选择点
非叶子节点与分支:中间过程
叶子节点:最终的决策过程
例子:一个家庭里面找出玩游戏的人(通过年龄和性别两个特征)
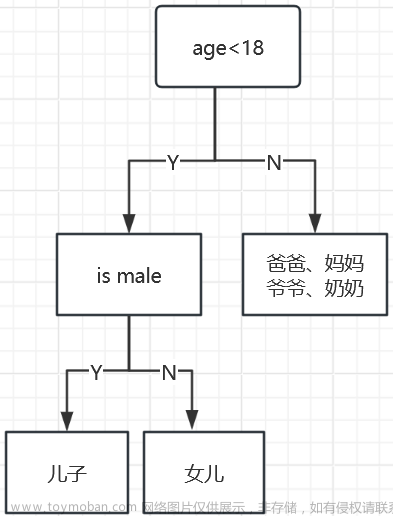
如何切分特征(选择节点)
问题:根节点的特征该用哪个特征?如何切分?
假设:我们目标应该是根节点就像一个老大一样能够更好的切分数据(分类的效果更好),根节点下面的节点自然就是二当家。
目标:通过一种衡量指标,来计算通过不同特征进行分支选择后的分类情况,找出最好的那个当成根节点,以此类推。
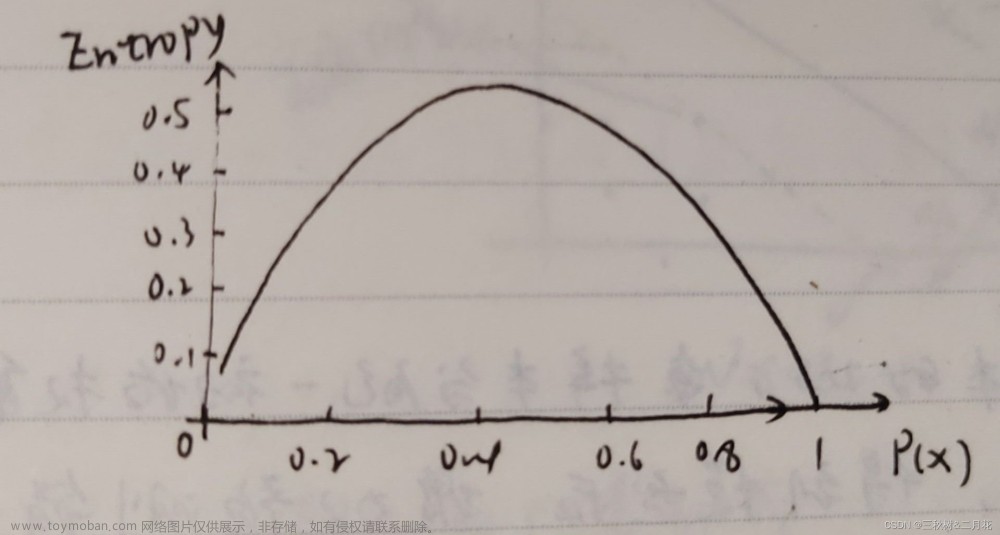
衡量指标——熵
熵:表示随机变量不确定性的度量(说白了就是物体内部的混乱程度,(概率越大)熵的值越小,物体的混乱程度越低,(概率越小)熵值越大,物体的混乱程度越高)
公式:
其中:
- 是数据集 的熵。
- 是类别的数量。
- 是选择第个类别的概率。
为了计算一个数据集的熵,你需要遵循以下步骤:
- 对于数据集 ,确定所有不同的类别。
- 计算属于每个类别的元素的比例,即每个类别的概率。
- 对每个类别,计算。
- 将第3步中计算的所有值相加,并取其相反数,得到熵。
例如,假设一个数据集有两个类别(正类和负类),每个类别的实例数分别是 9 和 5。首先,我们计算每个类别的概率:正类的概率,负类的概率。然后,应用熵公式计算:
这个值反映了数据集的不确定性程度。在构建决策树时,我们希望通过选择合适的特征来减少熵,也就是说,我们希望通过分割数据集来得到更低熵的子集,这样可以使得决策树在每个节点上做出更清晰的决策。
信息增益是决策树算法中用于选择数据集的最佳分割特征的一种度量。它是基于熵的一个概念,用来确定一个特征带来的熵减少(即信息增加)的数量。信息增益越高,意味着使用该特征进行分割所得到的子集的纯度提高得越多。
信息增益 (IG) 的公式是基于父节点和其子节点的熵的差值计算的:
[ IG(S, A) = H(S) - \sum_{t \in T} \frac{|S_t|}{|S|} H(S_t) ]
其中:
- ( IG(S, A) ) 是数据集 ( S ) 关于特征 ( A ) 的信息增益。
- ( H(S) ) 是数据集 ( S ) 的原始熵。
- ( T ) 是根据特征 ( A ) 的所有可能值将数据集 ( S ) 分割成的子集的集合。
- ( S_t ) 是由于特征 ( A ) 的值为 ( t ) 而形成的子集。
- ( |S_t| ) 是子集 ( S_t ) 的大小。
- ( |S| ) 是整个数据集 ( S ) 的大小。
- ( H(S_t) ) 是子集 ( S_t ) 的熵。
信息增益
在构建决策树时,我们通常对每个特征计算信息增益,选择信息增益最大的特征作为节点的分割特征。通过这个过程,我们希望每次分割都能最大化信息的纯度提升,这样构建出来的树能更好地分类数据。
让我们通过一个简单的例子来说明信息增益的计算:
假设我们有一个数据集,它有两个类别,类别 A 和类别 B。数据集的总熵已经计算为 0.940。现在我们考虑一个特征,它可以将数据集分割成两个子集 和。我们计算这两个子集的熵 和,然后根据它们在父数据集中的比例加权求和,得出分割后的总熵。如果 是 0.0(因为中所有实例都属于同一个类别),是 0.918,而且是 5, 是 9,那么分割后的总熵是:
因此,特征 的信息增益是:
根据这个计算结果,我们知道使用特征进行分割能够减少熵,增加信息的纯度,具体增加的信息量为 0.351。通过比较不同特征的信息增益,我们可以选择最好的分割点来构建决策树的下一个节点。

决策树构造实例:




决策树算法:
ID3:信息增益(问题如果新增ID列,用ID列做信息增益,会很大,但是没意义)
C4.5:信息增益率(解决ID3问题,考虑自身熵)
- 是特征A的信息增益。
- 是分割信息,度量的是使用特征 来分割数据集时的熵。
CART:使用GINI系数来当作衡量标准
- 是数据集 的基尼系数。
- 是数据集中不同类别的个数。
- 是数据集中第个类别的相对频率(概率)。
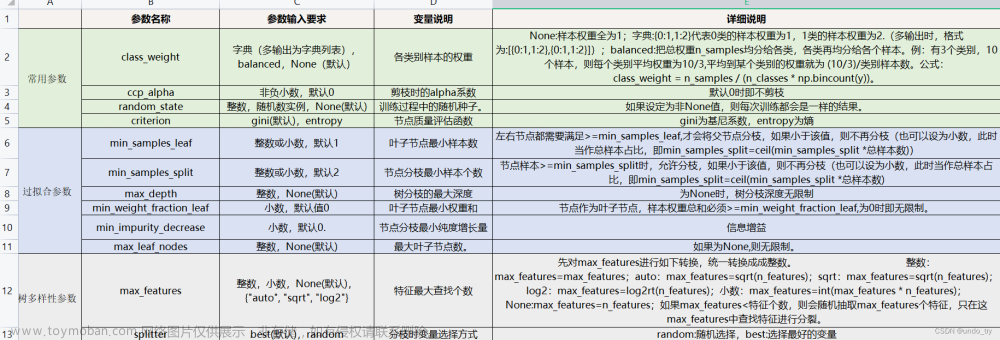
决策树剪枝策略:
为什么要剪枝:决策树过拟合风险很大,理论上可以完全分的开数据(想象一下,如果树足够庞大,每个节点不就一个数据了吗)
剪枝策略:预剪枝、后剪枝
预剪枝:边建立决策树进行剪枝的操作(更实用)
后剪枝:当建立完决策树后来进行剪枝的操作
预剪枝方法:
限制深度、叶子节点个数叶子节点样本数,信息增益量等
后剪枝方法:文章来源:https://www.toymoban.com/news/detail-800213.html
通过一定的hen文章来源地址https://www.toymoban.com/news/detail-800213.html
到了这里,关于决策树:理解机器学习中的关键算法的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!