一、前言
在Java项目开发过程中经常会遇到导出Word文档的业务场景。XWPFDocument是apache基金会提供的用户导出Word文档的工具类。
二、基本的概念
- XWPFDocument:代表一个docx文档
- XWPFParagraph:代表文档、表格、标题等各种的段落,由多个XWPFRun组成
- XWPFRun:代表具有同样风格的一段文本
- XWPFTable:代表一个表格
- XWPFTableRow:代表表格的一行
- XWPFTableCell:代表表格的一个单元格
- XWPFChar:表示.docx文件中的图表
- XWPFHyperlink:表示超链接
- XWPFPicture:代表图片
- XWPFComment :代表批注
- XWPFFooter:代表页脚
- XWPFHeader:代表页眉
- XWPFStyles:样式(设置多级标题的时候用)
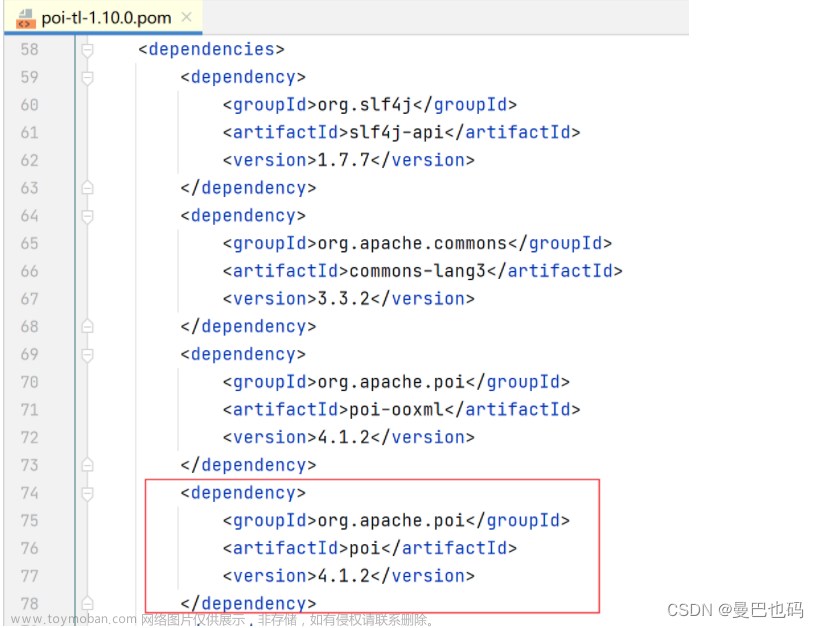
三、Maven依赖(JAR)
<!-- poi pdf文件/xml文件 -->
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>3.10-FINAL</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>4.1.2</version>
</dependency>
四、Word模板
1.正文段落
一个文档包含多个段落,一个段落包含多个Runs,一个Runs包含多个Run,Run是文档的最小单元
获取所有段落:List paragraphs = word.getParagraphs();
获取一个段落中的所有Runs:List xwpfRuns = xwpfParagraph.getRuns();
获取一个Runs中的一个Run:XWPFRun run = xwpfRuns.get(index);
XWPFRun–代表具有相同属性的一段文本
2.正文表格
一个文档包含多个表格,一个表格包含多行,一行包含多列(格),每一格的内容相当于一个完整的文档
获取所有表格:List xwpfTables = doc.getTables();
获取一个表格的行数:int rcount = xwpfTable.getNumberOfRows();
获取一个表格的第几行:XWPFTableRow row = table.getRow(i);
获取一个表格中的所有行:List xwpfTableRows = xwpfTable.getRows();
获取一行中的所有列:List xwpfTableCells = xwpfTableRow.getTableCells();
获取一格里的内容:List paragraphs = xwpfTableCell.getParagraphs();
之后和正文段落一样
注:
- 表格的一格相当于一个完整的docx文档,只是没有页眉和页脚。里面可以有表格,使用xwpfTableCell.getTables()获取,and so on
- 在poi文档中段落和表格是完全分开的,如果在两个段落中有一个表格,在poi中是没办法确定表格在段落中间的。(当然除非你本来知道了,这句是废话)。只有文档的格式固定,才能正确的得到文档的结构
3.页眉
一个文档可以有多个页眉,页眉里面可以包含段落和表格
获取文档的页眉:List headerList = doc.getHeaderList();
获取页眉里的所有段落:List paras = header.getParagraphs();
获取页眉里的所有表格:List tables = header.getTables();
4.页脚
页脚和页眉基本类似,可以获取表示页数的角标
五、XWPFDocument的使用
5.4导出Word文档
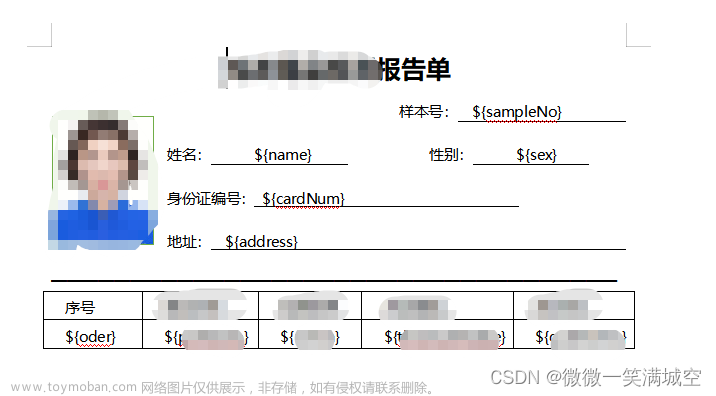
1.word模板
在resources目录下准备好word模板:xiaoshen.docx

2.PdfTest测试类
package com.shenxm.file.pdf.test;
import com.shenxm.file.pdf.service.impl.SystemFileBizImpl;
import org.junit.Test;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.HashMap;
/**
* @Author: shenxm
* @Description: pdf测试
* @Version 1.0
*/
public class PdfTest {
@Test
public void test1(){
Date date = new Date();
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd hh:mm:ss");
String format = simpleDateFormat.format(date);
HashMap<String, Object> boMap = new HashMap<>();
boMap.put("address","北京");
boMap.put("name","法克\n蒙克丽丽\n娜娜");
boMap.put("datetime","\n"+format);
boMap.put("opinion","\n小沈\n"+format+"\n审批通过");
boMap.put("book","春的林野");
String docxTemplate = "xiaoshen.docx";//docx模板
String pdfFileName = "xiaoshen.pdf";//输出的pdf
SystemFileBizImpl systemFileBiz = new SystemFileBizImpl();
systemFileBiz.exportPdf(boMap,docxTemplate,pdfFileName);
}
}
3.ISystemFileService接口
package com.shenxm.file.pdf.service;
import com.shenxm.file.pdf.entity.DownloadFileBo;
import java.util.Map;
public interface ISystemFileService {
DownloadFileBo exportPdf(Map<String,Object> map,String template,String fileName);
}
4.SystemFileServiceImpl实现类
package com.shenxm.file.pdf.service.impl;
import com.shenxm.file.pdf.entity.DownloadFileBo;
import com.shenxm.file.pdf.service.ISystemFileService;
import org.apache.poi.xwpf.usermodel.*;
import org.springframework.stereotype.Service;
import org.springframework.util.Assert;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
/**
* @Author: shenxm
* @Description: 文件处理 Service
* @Version 1.0
*/
@Service
public class SystemFileServiceImpl implements ISystemFilService {
@Override
public DownloadFileBo exportPdf(Map<String, Object> map, String docxTemplateName, String pdfFileName) {
//校验参数
Assert.notEmpty(map, "数据源不可为空!");
Assert.notNull(docxTemplateName,"docxTemplateName不能为空");
Assert.notNull(pdfFileName,"pdfFileName不能为空");
String pdfExportPath = "G:" + File.separator + "test1" + File.separator;
//1.生成pdf文件对象
File pdfFile = this.createFile(pdfExportPath, pdfFileName);
String docxExportPath = "G:" + File.separator + "test1" + File.separator;//生成的word的路径
String docxExportName ="xiaoshen1.docx";
//使用当前线程的类加载器读取文件
InputStream in = Thread.currentThread().getContextClassLoader().getResourceAsStream(docxTemplateName);
if (in == null) {
System.out.println("读取文件失败!");
} else {
try {
//读取模板文档
XWPFDocument document = new XWPFDocument(in);
//替换段落中的${}
this.replaceTextInParagragh(document, map);
//替换表格中的${}
this.replaceTextInTables(document, map);
//TODO 替换其他的
//将Docx文档写入文件
File exportWord = new File(docxExportPath + docxExportName);
FileOutputStream fileOutputStream = new FileOutputStream(exportWord);
//输出文件
document.write(fileOutputStream);
fileOutputStream.flush();
//TODO word转为pdf
//关闭流
fileOutputStream.close();
in.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return null;
}
/** 替换表格中的占位符 */
private void replaceTextInTables(XWPFDocument document, Map<String, Object> dataMap) {
//获取所有的表格
List<XWPFTable> tables = document.getTables();
//循环
for (XWPFTable table : tables) {
//获取每个表格的总行数
int rcount = table.getNumberOfRows();
for (int i = 0; i < rcount; i++) {
//获取表格的第i行
XWPFTableRow row = table.getRow(i);
//获取一行的所有单元格
List<XWPFTableCell> cells = row.getTableCells();
for (XWPFTableCell cell : cells) {
//一个cell相当于一个document
//获取单元格内的文本
String cellTextString = cell.getText();
//替换文本:${} -> value
cellTextString = this.replaceText(cellTextString, dataMap);
//移除表格中的段落
while (cell.getParagraphs().size() > 0) {
cell.removeParagraph(0);
}
//处理换行,并设置单元格内容
this.setWrap(cellTextString,cell);
}
}
}
}
/** 替换段落中的占位符 */
private void replaceTextInParagragh(XWPFDocument document, Map<String, Object> dataMap) {
//获取整个Word所有段落:包含页眉或页脚文本的段落
List<XWPFParagraph> paragraphs = document.getParagraphs();
//循环
for (XWPFParagraph paragragh : paragraphs) {
//获取一段的所有本文
List<XWPFRun> runs = paragragh.getRuns();
//获取段落内容:paragragh.getText();
//循环
for (int i = 0; i < runs.size(); i++) {
//XWPFRun--代表具有相同属性的一段文本
XWPFRun xwpfRun = runs.get(i);
//获取文本中的内容
String paraString = xwpfRun.getText(xwpfRun.getTextPosition());
if (paraString != null) {
//替换文字
paraString = this.replaceText(paraString, dataMap);
//设置替换后的段落
xwpfRun.setText(paraString, 0);
}
}
}
}
/** 替换文字 */
private String replaceText(String text, Map<String, Object> dataMap) {
String paraString = text;
//遍历map,将段落里面的${}替换成map里的value
Iterator<Map.Entry<String, Object>> iterator = dataMap.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<String, Object> entry = iterator.next();
String key = entry.getKey();
String value = entry.getValue().toString();
//组装map里的key为${key}
StringBuffer sb = new StringBuffer();
String placeHolder = sb.append("${").append(key).append("}").toString();
//替换:将"${as}dasdas" --> value+dasdas
paraString = paraString.replace(placeHolder, value);
}
return paraString;
}
/** 单元格内设置换行 */
private void setWrap(String cellTextString,XWPFTableCell cell){
if (cellTextString != null &&cellTextString.trim().contains("\n")){
//创建文本
XWPFRun run = cell.addParagraph().createRun();
String[] split = cellTextString.split("\n");
run.setText(split[0],0);
for (int i = 1; i < split.length; i++) {
//添加换行符
run.addBreak();
//设置单元格内容
run.setText(split[i]);
}
}else {
//设置单元格内容
cell.setText(cellTextString);
}
}
/** 根据路径和文件名 创建文件对象*/
private File createFile(String filePath,String fileName){
//pdf目录对象
File file = new File(filePath);
if (!file.exists() || !file.isDirectory()) {
file.mkdirs();
}
//pdf文件对象
StringBuffer filePathBuffer = new StringBuffer();
filePathBuffer.append(filePath).append(fileName);
return new File(filePathBuffer.toString());
}
}
5.结果

六、遇到问题
5.1输出为word的时候换行符无效
java换行符"\n"在word文档中不生效,使用"\r",“\r\n”,“(char)11”,“^p”,“br”,“<w:br>”,"w:p"等均无法实现单元格内换行的功能。文章来源:https://www.toymoban.com/news/detail-800220.html
实现单元格内自动换行:文章来源地址https://www.toymoban.com/news/detail-800220.html
到了这里,关于Java文件:XWPFDocument导出Word文档的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!