个人简介
🏘️🏘️个人主页:以山河作礼。
🎖️🎖️:Python领域新星创作者,CSDN实力新星认证,CSDN内容合伙人,阿里云社区专家博主,新星计划导师,在职数据分析师。
🎉🎉免费学习专栏:1. 《Python基础入门》——0基础入门
2.《Python网络爬虫》——从入门到精通
3.《Web全栈开发》——涵盖了前端、后端和数据库等多个领域💕💕悲索之人烈焰加身,堕落者不可饶恕。永恒燃烧的羽翼,带我脱离凡间的沉沦。
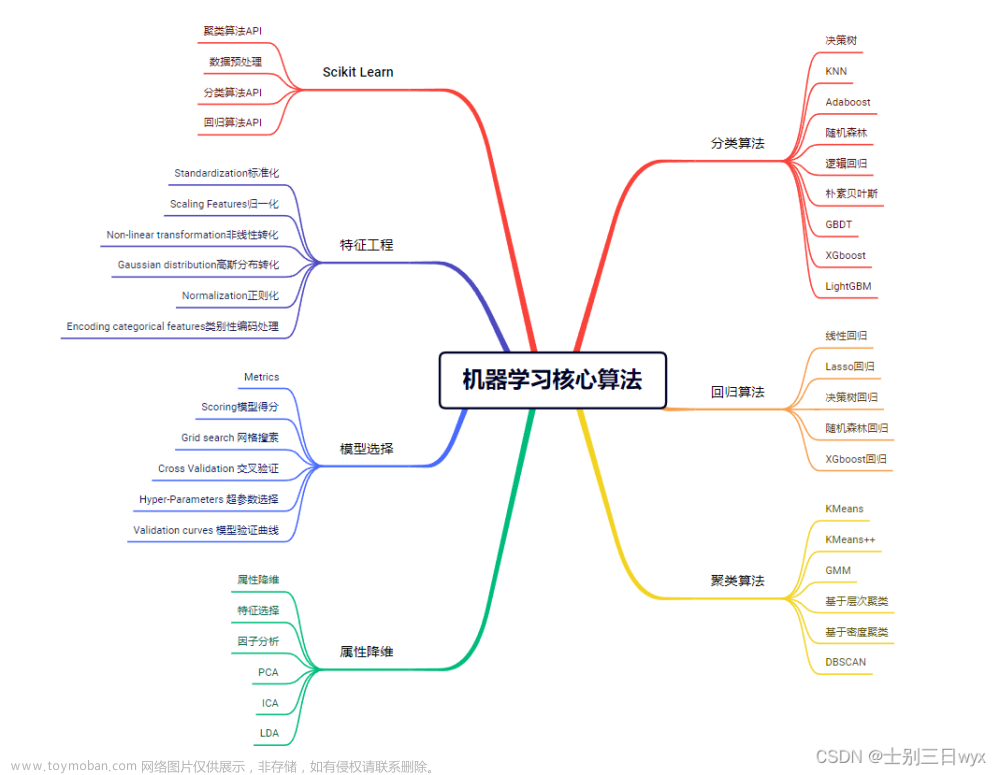
机器学习算法分类:监督学习、无监督学习、强化学习

一·监督学习
监督学习是机器学习中最常用的一种重要方法,它利用一组已知类别的样本调整分类器的参数,使其达到所要求性能的过程。简单来说,监督学习就是从已有的标记数据中学习模型,然后利用这个模型对新的未知数据进行预测。
在监督学习中,每个样本都包含输入特征和对应的输出标签。
输入特征也称为特征向量,是一个可以描述样本特性的值;
输出标签通常是离散的类别标签或者连续的数值标签,用来表示样本所属的类别或者具有的属性。
通过训练,模型将学会从输入特征中预测出相应的输出标签。
监督学习的应用场景非常广泛,包括但不限于分类、回归、聚类、降维等任务。分类是监督学习中最为常见的一种任务,它将输入特征映射到某个离散的类别标签上;回归则将输入特征映射到某个连续的数值标签上。
1. 监督学习分类任务举例:
假设我们有一组包含房屋信息的数据集,其中每个样本包含房屋所在街区、房屋价格、住房面积、住房格局等特征,以及一个表示该房屋是否售出的标签。我们可以使用监督学习算法来训练一个分类器,通过分析这些特征和标签的关系,预测新的房屋是否能够售出。
特征向量包括房屋所在街区、价格、面积和格局等属性;
1.1 特征
房屋所在街区:我们可以将其划分为不同的区域,比如市中心、郊区等。
房屋价格:具体的房屋售价,以货币单位表示。
住房面积:房屋的建筑面积,以平方米为单位。
住房格局:房屋的内部布局,比如一室一厅、两室一厅等。
输出标签为离散的类别标签,表示房屋是否售出。
1.2 标签
房屋是否售出:这是一个二元分类问题,可以用0和1来表示。0表示房屋未售出,1表示房屋已售出。
在这个例子中,我们的目标是构建一个分类器,通过分析输入特征(房屋所在街区、价格、面积和格局),预测输出标签(房屋是否售出)。这个任务可以被视为一个分类问题,其中每个样本的输入特征被映射到一个离散的类别标签上(0或1)。
为了解决这个问题,我们可以使用监督学习算法来训练一个分类器。常见的监督学习算法包括逻辑回归、支持向量机、决策树和随机森林等。这些算法可以根据训练数据集中的特征和标签之间的关系,构建出一个模型,用于预测新的未知数据的标签。
在训练过程中,我们需要将训练数据集分成训练集和验证集两部分。训练集用于训练模型,验证集用于评估模型的性能和调整模型参数。常见的评估指标包括准确率、精确率、召回率和F1分数等。通过不断调整模型参数和优化模型结构,我们可以提高模型的预测准确性和泛化能力。通过训练这个分类器,我们可以发现一些规律,比如在某个街区的房屋更容易售出,或者价格较高的房屋更难售出等。
二·无监督学习
无监督学习是一种机器学习训练方法,其本质是一个统计手段。在这种方法中,我们利用无标签的数据来探索和发现潜在的结构或模式。无监督学习在许多领域中都有广泛的应用,包括数据挖掘、机器视觉、自然语言处理等。
1.关键特点
- 无明确目标:与监督学习不同,无监督学习没有明确的预测目标。它的目的是在数据中寻找隐藏的模式或结构。
- 不需要标签:在无监督学习中,数据集中的样本不需要预先标记或分类。学习过程是通过数据内在的相似性或关联性来进行的。
- 效果难以量化:由于无监督学习没有明确的预测目标,因此很难用一个统一的指标来衡量其效果。通常,我们关注的是发现数据的内在结构或关系。
2.应用示例
- 异常值检测(风控):在金融领域,异常值检测常用于识别潜在的欺诈行为或非正常交易模式。通过无监督学习,可以将交易数据根据其特征进行聚类,然后识别出与大多数聚类明显不同的样本,这些样本可能代表异常行为。
- 用户细分:在市场营销中,用户细分是一个重要的步骤。通过无监督学习,可以根据用户的特征和行为将他们分成不同的群体,以便更好地理解每个群体的需求和偏好,从而制定更有针对性的营销策略。
- 推荐系统:这是无监督学习的一个广泛应用领域。通过分析用户的浏览历史、购买记录等行为数据,推荐系统可以识别出用户可能感兴趣的商品或内容,并进行相应的推荐。这种推荐往往基于用户之间的相似性或物品之间的关联性。
3.常见的无监督学习算法
- 聚类算法:这类算法的目标是将相似的数据样本聚集成不同的群组或簇。常见的聚类算法包括K-means、层次聚类、DBSCAN等。聚类算法在数据挖掘和图像处理等领域有广泛应用。
- 降维算法:这类算法用于降低数据的维度,以减少计算复杂度和更好地理解数据的内在结构。常见的降维算法包括主成分分析(PCA)、t-分布邻域嵌入算法(t-SNE)等。降维算法在可视化、特征提取和机器视觉等领域有重要应用。
三·强化学习
1.定义
强化学习(Reinforcement Learning,RL)是机器学习的一个重要分支,它主要研究智能体(agent)在与环境(environment)的交互过程中如何通过学习策略以达成回报最大化或实现特定目标的问题。强化学习的核心思想是,智能体通过与环境进行交互,不断获取新的信息并更新自身的策略,以最大化长期的累积奖励。与监督学习和无监督学习不同,强化学习没有明确的正确答案或标签,而是依赖于环境的反馈来指导学习过程。
强化学习的常见模型是标准的马尔可夫决策过程(Markov Decision Process,MDP),它由状态、动作和奖励三个基本要素组成。在强化学习中,智能体根据当前状态选择一个动作,并从环境中获得新的状态和奖励。智能体的目标是找到一个最优策略,使得在给定状态下采取最优动作能够最大化长期的累积奖励。
强化学习的算法可以分为策略搜索算法和值函数(value function)算法两类。
策略搜索算法通过直接搜索策略空间来找到最优策略,而值函数算法通过迭代更新值函数来逼近最优策略。此外,深度学习模型可以在强化学习中得到使用,形成深度强化学习。

强化学习中两个核心的概念就是:「智能体」agent和「环境」environment。环境表示智能体生存以及交互的世界。每一次交互时,智能体会观察到世界当前所处「状态」state的「观测值」observation,然后决定采取什么「动作」action。环境会随着智能体的动作而发生变化,当然环境自身也可能一直处于变化中。
智能体会从环境中接收到一个「奖励」reward信号,这个信号可能是一个数值,表示当前环境所处状态的好坏。智能体的目标是:最大化「累积奖励」cumulative reward,也称为「收益」return。强化学习方法就表示智能体通过学习行为来达到这个目标的途径。
强化学习算法的思路非常简单,以游戏为例,如果在游戏中采取某种策略可以取得较高的得分,那么就进一步「强化」这种策略,以期继续取得较好的结果。这种策略与日常生活中的各种「绩效奖励」非常类似。我们平时也常常用这样的策略来提高自己的游戏水平。
在 Flappy bird 这个游戏中,我们需要简单的点击操作来控制小鸟,躲过各种水管,飞的越远越好,因为飞的越远就能获得更高的积分奖励。
2.示例场景
这就是一个典型的强化学习场景:
- 机器有一个明确的小鸟角色——代理
- 需要控制小鸟飞的更远——目标
- 整个游戏过程中需要躲避各种水管——环境
- 躲避水管的方法是让小鸟用力飞一下——行动
- 飞的越远,就会获得越多的积分——奖励

你会发现,强化学习和监督学习、无监督学习 最大的不同就是不需要大量的“数据喂养”。而是通过自己不停的尝试来学会某些技能。
四·机器学习开发流程
 文章来源:https://www.toymoban.com/news/detail-800498.html
文章来源:https://www.toymoban.com/news/detail-800498.html
流程图: 文章来源地址https://www.toymoban.com/news/detail-800498.html
文章来源地址https://www.toymoban.com/news/detail-800498.html
到了这里,关于1.机器学习-机器学习算法分类概述的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![[机器学习]分类算法系列①:初识概念](https://imgs.yssmx.com/Uploads/2024/02/691505-1.png)