0 简介
🔥 优质竞赛项目系列,今天要分享的是
基于机器学习的二维码识别检测 - opencv 二维码 识别检测 机器视觉
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🧿 更多资料, 项目分享:文章来源:https://www.toymoban.com/news/detail-800659.html
https://gitee.com/dancheng-senior/postgraduate文章来源地址https://www.toymoban.com/news/detail-800659.html
1 二维码检测
物体检测就是对数字图像中一类特定的物体的位置进行自动检测。基本的检测框架有两种:
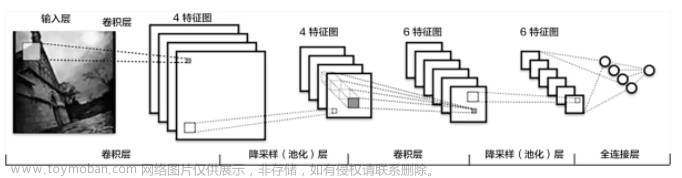
一种是以滑动窗口为单位对图像进行扫描,对扫描所得的每个子图像提取特征,并用学习到的分类器来分类该特征并且判断该子图像是否为所检测的特定物体。对象检测的一个问题是,对象在图片中的位置和尺度是未知的。算法被要求能够检测各种不同位置、不同大小的对象,这样的特性被称为位置无关性和尺度无关性。为了达到这样的特性,常见的方法是使用多尺度框架,即:通过缩放原始图像,产生一组大小不同的图像序列,然后在序列的每幅图像中都使用固定尺寸
W×H
的滑动窗口,检测算法将判断每次滑动窗口所截取的图像子窗口是否存在目标对象。滑动窗口解决了位置无关性;而图像序列中存在至少一幅图像,其包含的目标对象的尺度符合滑动窗口的尺度,这样一个图像金字塔序列解决了尺度无关性。
另一种则是在整幅图像上首先提取兴趣点,然后仅对提取出来的兴趣点分类。
因此学长把物体检测方法分为基于滑动窗口的物体检测和基于兴趣点的物体检测两类。
无论是哪种做法,整个过程都可以分为特征提取和特征分类这两个主要阶段。也就是说,物体检测的主要问题是使用什么样的特征和使用什么样的分类器。
物体检测的难点在于如何用有限的训练集来学习到鲁棒的、可以适用到各种情况下的分类器。这里所说的各种情况包括有:图像中物体的大小不同;光照条件的差异所引起的图像明暗的不同;物体在图像中可能存在的旋转和透视情况;同类物体间自身存在的差异。
这里学长以定位二维码 / 条形码为例,简述基于机器学习实现物体检测的大致算法流程。
2 算法实现流程
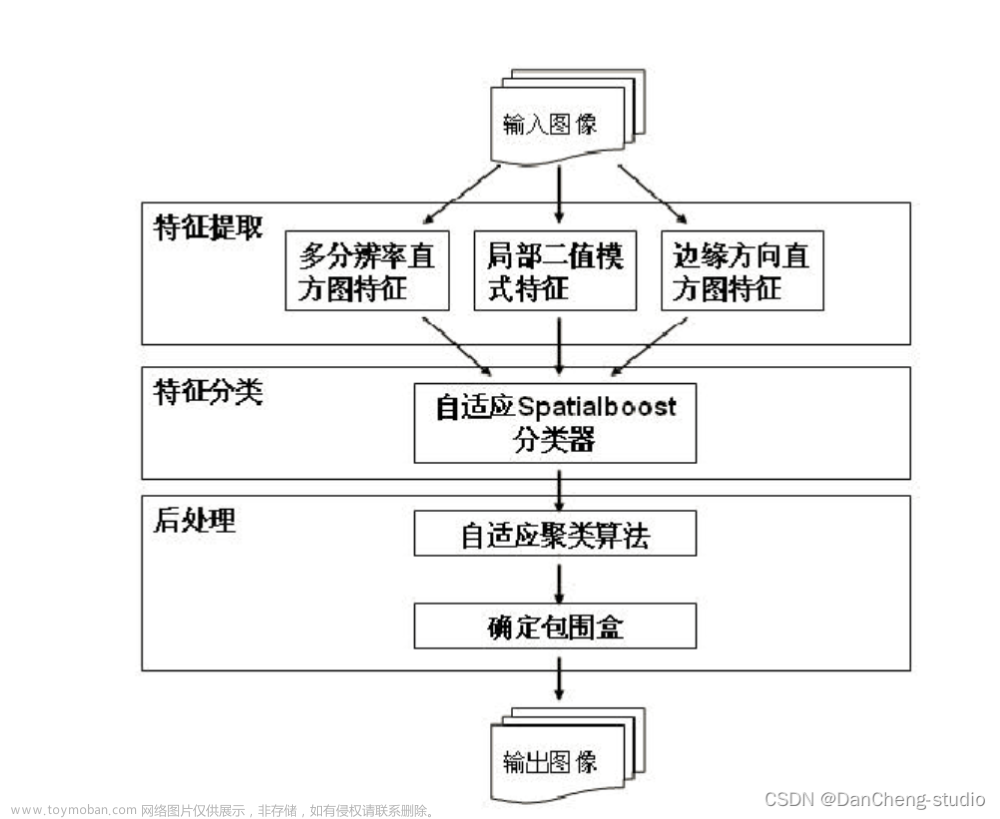
算法流程图如下图所示:

我们先把输入图像分成 25×25
的图像子块。把图像子块作为特征提取和特征分类这两个模块的基本处理对象,即对图像子块进行纹理特征提取,特征分类时判定当前处理的图像子块是否属于二维条形码的一部分

在特征提取模块中,我们使用纹理特征提取算法从原始输入图像中提取出多分辨率直方
在特征分类时,我们希望保留所有属于二维条形码的图像子块,同时去除所有属于背景的图像子块。在该模块中,我们使用了自适应 Spatialboost 算法。
下图为经过这步处理后的理想输出结果,图中被标记的小方块表示他们属于二维条形码的一部分。

3 特征提取
图像的纹理特征可以描述物体特有的属性,用以区别其他物体。纹理特征总体可分为空域和频域两大类。在本文算法中,我们采用的纹理特征均属于空域的纹理特征,也是局部特征,它们分别是多分辨率直方图特征、局部二值模式特征和边缘方向直方图特征。
多分辨率直方图特征具备旋转无关的特点。这种纹理特征保留了灰度直方图特征计算简单和保存方便的特点。同时它又可以描述纹理的局部信息,弥补了传统的灰度直方图特征的缺点。
局部二值模式特征是一种计算复杂度较低的局部特征,它具有明暗无关和旋转无关的特点。
边缘方向直方图特征与全局的光照变化是无关的,它可以提取出二维条形码纹理的几何特点。
4 特征分类
学长开发的算法所使用的分类器为自适应 Spatialboost 算法,这是对 Spatialboost
算法的一个改进。使用这个分类器是由二维条形码的特点以及我们算法框架的特点所决定的。由于我们把原始输入图像分为若干大小固定的图像子块,属于二维条形码的图像子块在空间上有很强的关联性,或者说这些属于二维条形码的图像子块都是紧密相邻的。同时由于图像子块的尺寸不大,它所包含的信息量相对较少,有的时候就很难把属于二维条形码的图像子块和属于背景的图像子块区分开(它们在特征空间上可能重叠)。如果我们可以利用子块在空间上的联系,把空间信息加入到分类器中,将有利于提高分类器的准确率。
适应 Spatialboost
算法可以同时利用纹理特征以及子块在空间上的联系,在训练过程中,将纹理特征和空间信息自适应的结合起来训练分类器。这样,当前处理的子块的分类结果不仅依赖于它自己的纹理特征,还和它周围子块的分类结果密切相关。当属于背景的图像子块的纹理特征很接近于属于二维条形码的图像子块时,我们还是可以依靠和它相邻的背景子块来对它做出正确的分类。
5 后处理
经过特征提取和特征分类两个模块后,我们得到了对图像子块的分类结果,但最后我们期望得到的是对二维条形码的包围盒。在我们的设置下,自适应Spatialboost
分类器对背景子块的分类相当严格,此时对属于二维条形码的图像子块会有部分漏检发生,

因此在后处理模块中,我们先使用一种自适应聚类算法,对分类后的结果进一步改进,来精确的覆盖整个二维条形码。特征分类后定位到的子块的大小为
25×25,我们把这些子块再划分为 10×10 的小方块。接着以得到的 10×10 的子块为种子,用子块灰度值的方差为衡量标准往外聚类,聚类时的阈值设定为:

其中 M 是聚类开始时作为种子的子块的个数,k 为调整系数,在本文算法中 k设置为 0.5,Var 和 Mean
分别表示子块灰度值的均值和方差。由公式(3-1)可知,每幅图像的聚类阈值是自适应的计算得来的。聚类开始时首先从种子子块出发,计算它们周围的子块的灰度值方差,如果大于聚类阈值就把它标识为属于二维条形码,重复这个过程直到周围再没有子块符合聚类条件。图
3-5
是聚类算法的部分结果,第一行的图像是特征分类后的结果,准确的定位到了一部分二维条形码,但是没有完全的覆盖整个二维条形码,不利于我们输出最后的定位包围盒。第二行为聚类后的结果,可以看到小块几乎完全覆盖了整个二维条形码,此时再把这些小块合并为一个平行四边形就很方便了。

聚类后定位出来的小块基本上覆盖了整个二维条形码,最后我们只需要把定位出的小包围盒合并为大包围盒,并输出最后的定位结果。整个后处理流程见图

6 代码实现
这里演示条形码的检测效果:
关键部分代码实现:
# import the necessary packages
import numpy as np
import argparse
import cv2
# construct the argument parse and parse the arguments
# ap = argparse.ArgumentParser()
# ap.add_argument("-i", "--image", required = True, help = "path to the image file")
# args = vars(ap.parse_args())
# load the image and convert it to grayscale
image = cv2.imread('./images/2.png')
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# compute the Scharr gradient magnitude representation of the images
# in both the x and y direction
gradX = cv2.Sobel(gray, ddepth = cv2.CV_32F, dx = 1, dy = 0, ksize = -1)
gradY = cv2.Sobel(gray, ddepth = cv2.CV_32F, dx = 0, dy = 1, ksize = -1)
# subtract the y-gradient from the x-gradient
gradient = cv2.subtract(gradX, gradY)
gradient = cv2.convertScaleAbs(gradient)
# blur and threshold the image
blurred = cv2.blur(gradient, (9, 9))
(_, thresh) = cv2.threshold(blurred, 225, 255, cv2.THRESH_BINARY)
# construct a closing kernel and apply it to the thresholded image
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (21, 7))
closed = cv2.morphologyEx(thresh, cv2.MORPH_CLOSE, kernel)
# perform a series of erosions and dilations
closed = cv2.erode(closed, None, iterations = 4)
closed = cv2.dilate(closed, None, iterations = 4)
# find the contours in the thresholded image, then sort the contours
# by their area, keeping only the largest one
(cnts, _) = cv2.findContours(closed.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
c = sorted(cnts, key = cv2.contourArea, reverse = True)[0]
# compute the rotated bounding box of the largest contour
rect = cv2.minAreaRect(c)
box = np.int0(cv2.boxPoints(rect))
5 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
到了这里,关于互联网加竞赛 基于机器视觉的二维码识别检测 - opencv 二维码 识别检测 机器视觉的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!