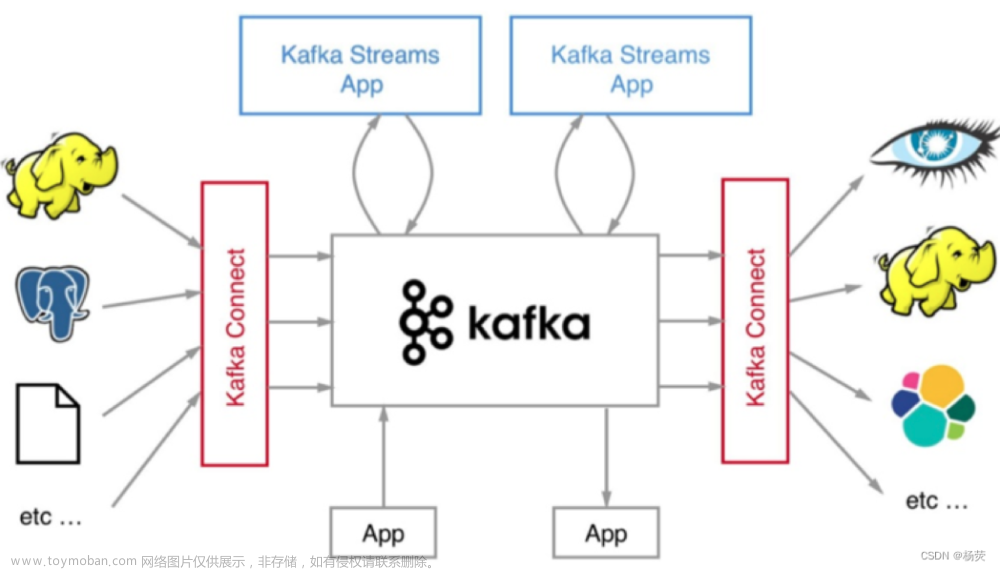
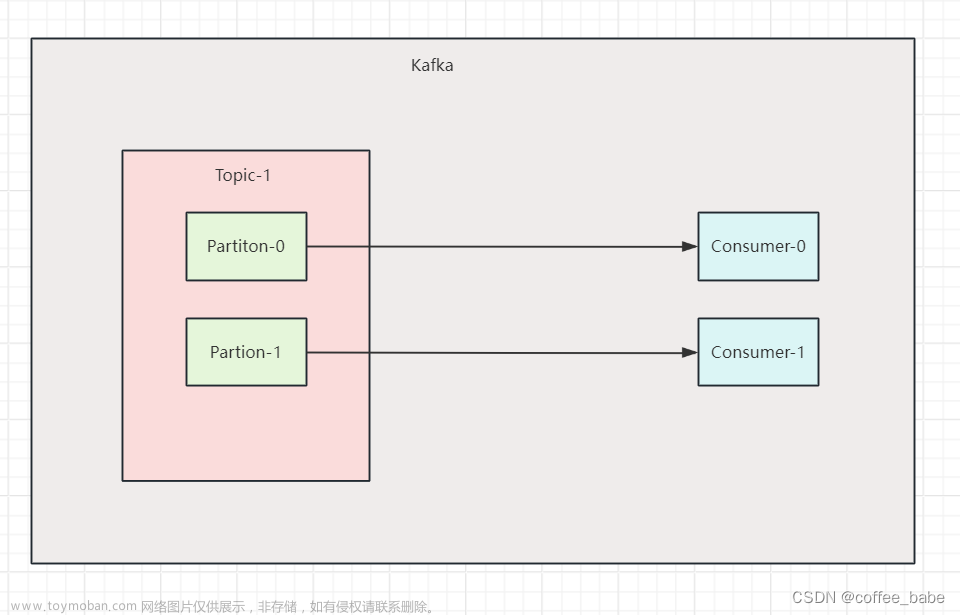
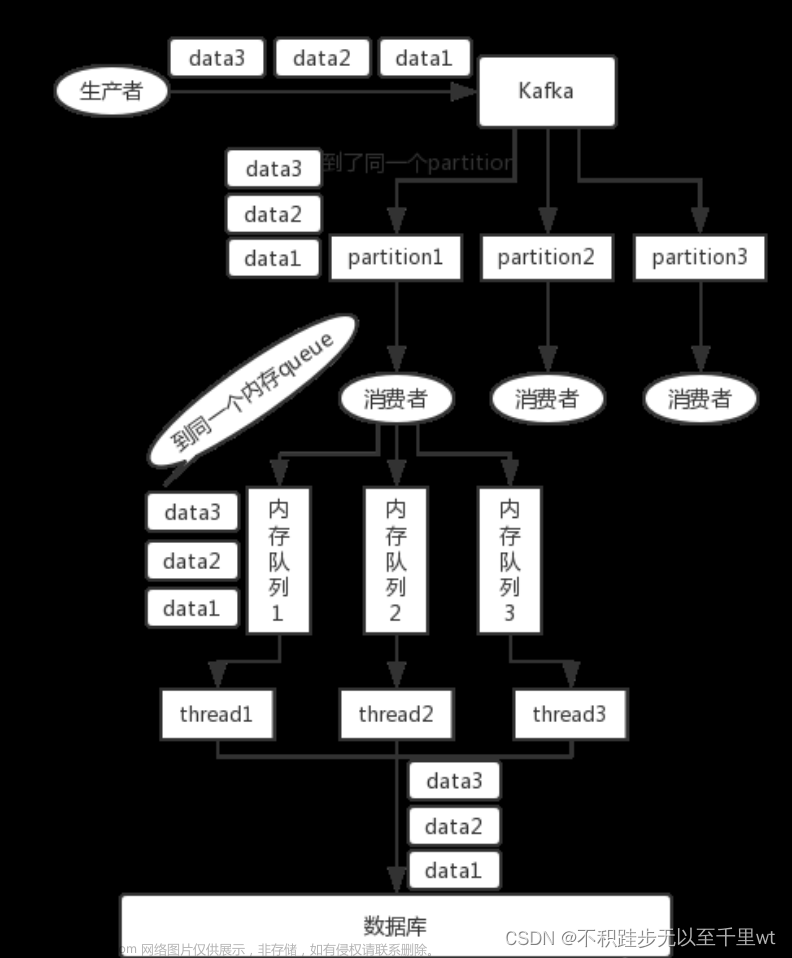
订单宽表数据不同步
事情的起因是用户在 app 上查不到订单了,而订单数据是从 mysql 的 order_search 表查询的,order_search 表的数据是从 oracle 的 order 表同步过来的,查不到说明同步有问题
首先重启,同步数据,问题解决,然后查找原因。首先看日志,有如下两种情况
- 有的容器消费消息的日志正常打印
- 有的容器很长时间没有消费消息的日志(看着像是消息丢失,找运维确认后明确发送没问题,只能是消费的问题)
接着看容器的状况
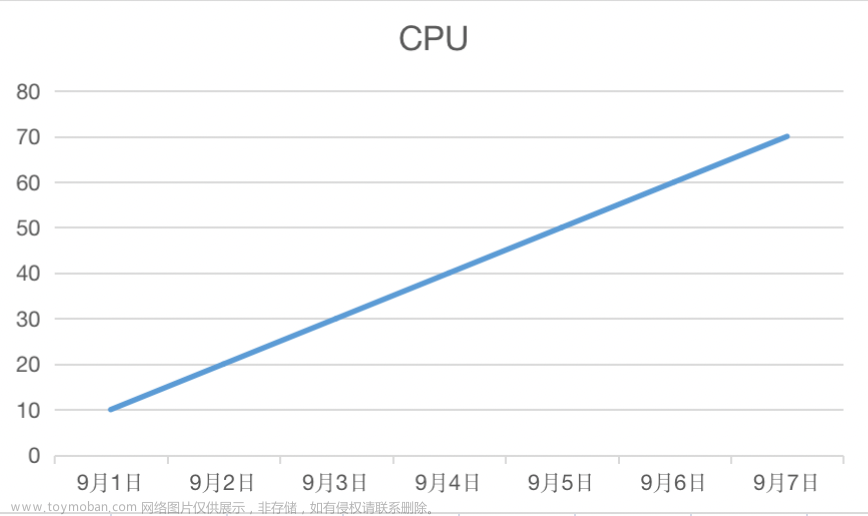
查看了应用重启前各个容器的 CPU 和内存情况,发现并不均匀,有如下三种情况
- CPU一直很高(内存稳定)
- CPU和内存一直稳定上升
- CPU一直很低(内存稳定)
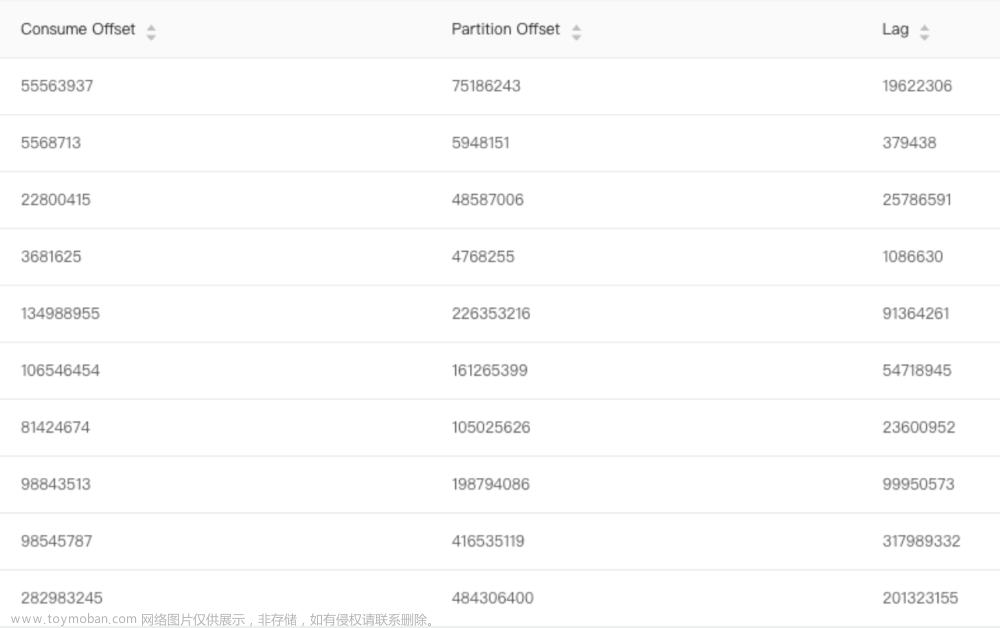
看监控发现消息在分区中分布的也不均衡
问题排查
接着就按照如下现象来进行排查问题
- 为什么消息发送不均衡
- 为什么有的容器CPU一直很高,有的一直很低,有的持续升高(CPU飙高的机器,内存也不断上涨)
为什么会出现这些现象?
producer发送消息和consumer消费消息都有对应的负载均衡策略,既然消息发送不均衡,只需要看producer的负载均衡策略即可
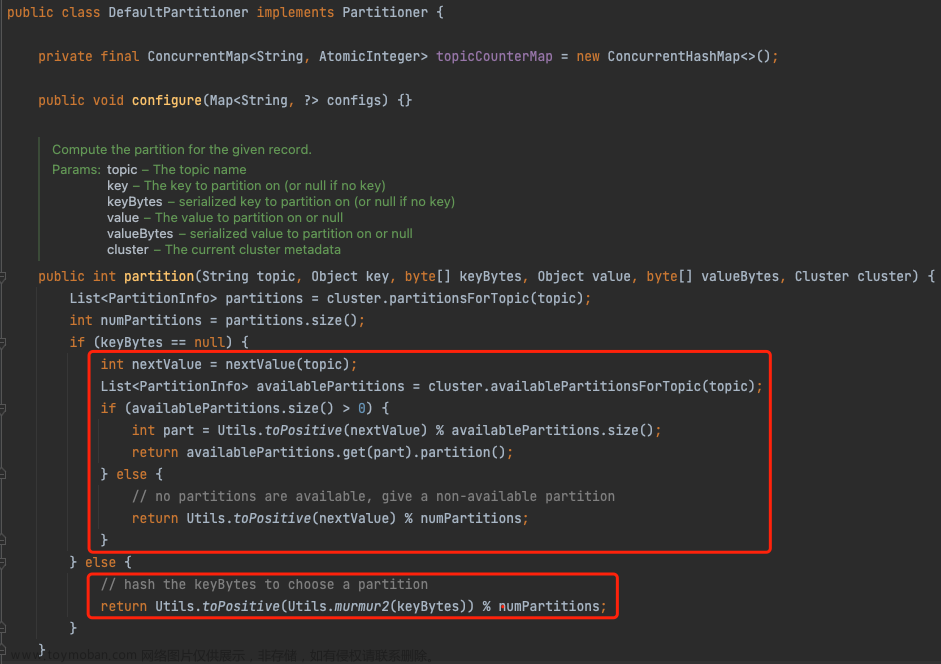
producer的负载均衡实现类为 DefaultPartitioner,具体实现为
- 如果 key 为 null:消息将以轮询的方式,在所有可用分区中分别写入消息
- 如果 key 不为 null:对 Key 值进行 Hash 计算,从所有分区中根据 Key 的 Hash 值计算出一个分区号;拥有相同 Key 值的消息被写入同一个分区;
所以推测 hddp-datasync 消费的消息指定了key,看消费日志确定了猜想,key的名字为表名
这样就明确了,同一张表的数据只会被发送到同一个分区,同一个分区的数据只能被一个 Consumer 消费
接着我们查到 CPU 一直比较高的容器,消费的是合同表的数据,合同表的数据变更比较频繁,所以CPU比较高
而 CPU 持续飙升的容器,消费的是订单表的数据。
接着就是排查消费订单表的容器为什么CPU和内存持续飙升
首先用生成 dump 文件,用 Eclipse Memory Analyzer 分析一下看是否发生了内存泄露
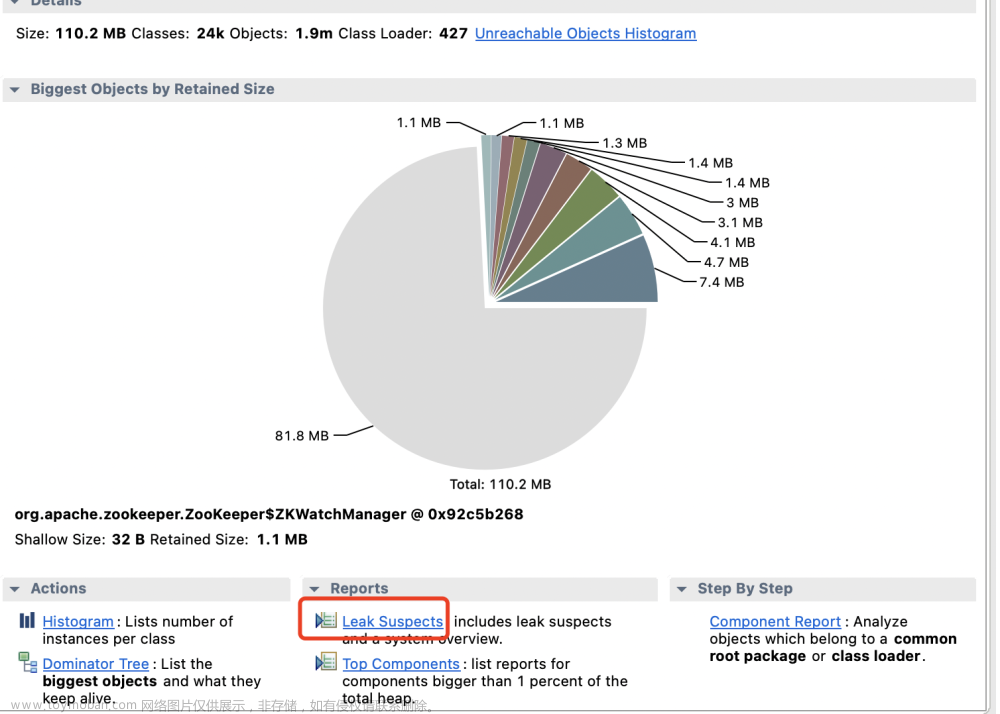
点击 Leak Supects 查看内存泄漏分析
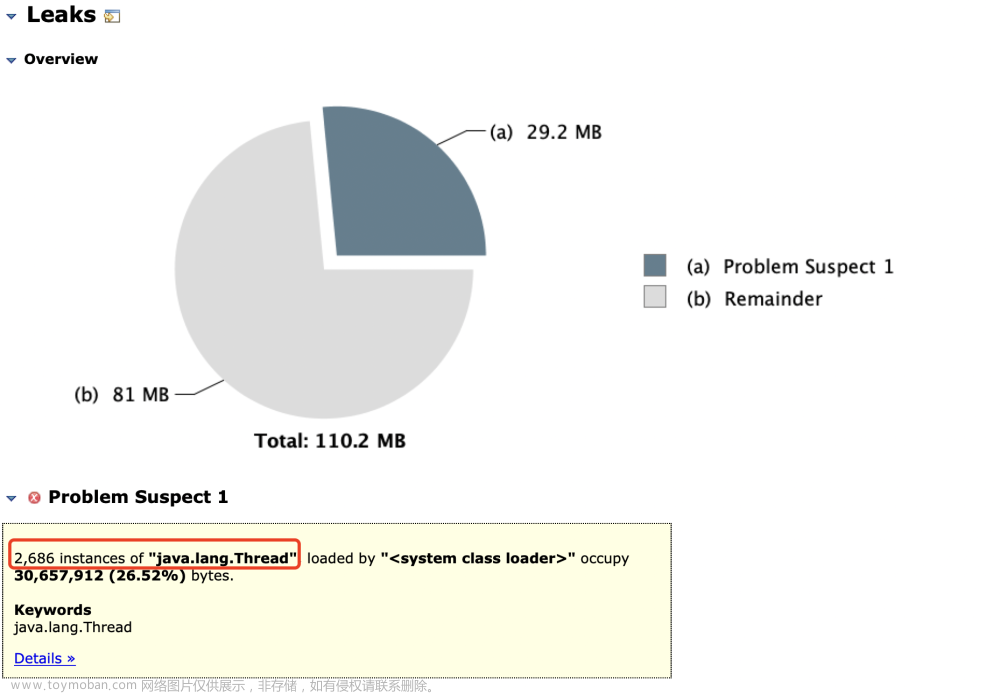
总共使用了110MB内存,Thread线程占用了29M,总共创建了2686个线程,看一下这些线程是哪些?
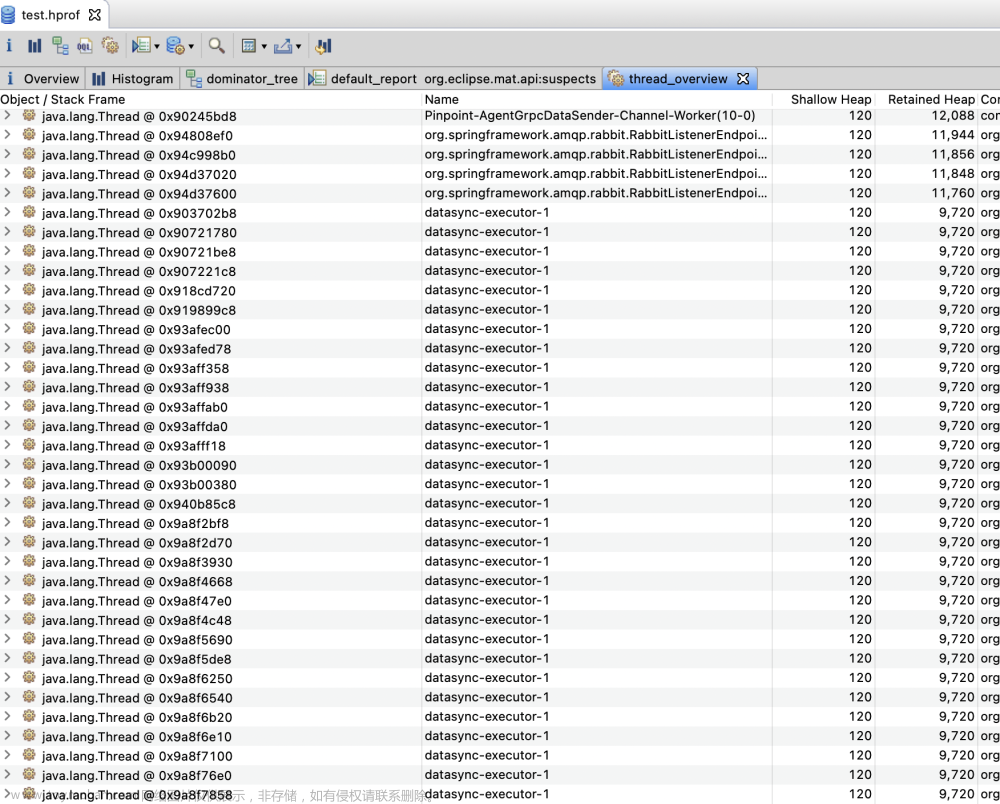
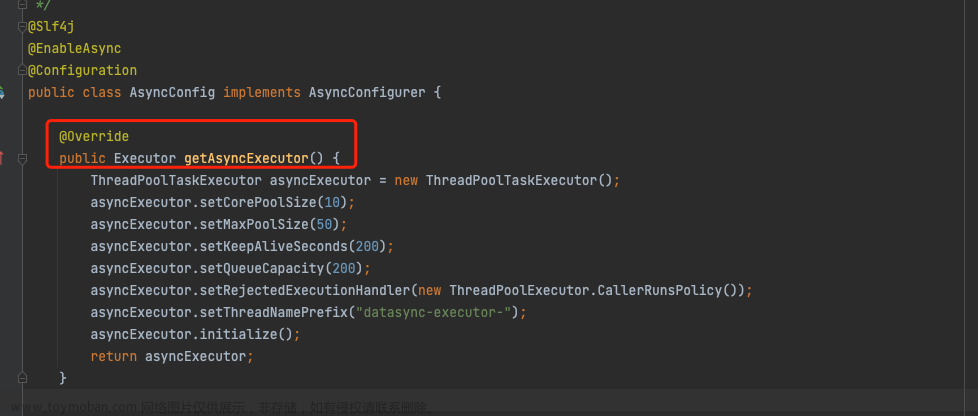
线程数量最多的线程名字为datasync-execuotr-1,到代码中查看是否有类似线程
 文章来源:https://www.toymoban.com/news/detail-800971.html
文章来源:https://www.toymoban.com/news/detail-800971.html
每消费一次订单表的数据,调用一次 asyncConfig.getAsyncExecutor()方法,就会新创建一个线程池,核心线程数为10,不断创建线程导致内存和 CPU 不断飙升,消息不能正常消费,后续消费消息改成使用一个固定的线程池后,消息正常消费文章来源地址https://www.toymoban.com/news/detail-800971.html
到了这里,关于Kafka 消息不能正常消费问题排查的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!