本次hadoop的安装系统为Windows10、Hadoop版本为3.3.6、Maven版本为3.9.4、Java版本为17.0.2。本教程基于前篇教程Hadoop集群、Java安装均完成后的后续教程,如未完成安装请查看前置教程。Hadoop、java安装
#############################################################################################
此外,大数据系列教程还在持续的更新中(包括跑一些实例、安装数据库、spark、mapreduce、hive等),欢迎大家关注我
客户端环境准备
Hadoop下载与解压
- 下载Hadoop3.3.6版本(具体版本根据自身需求修改)并解压至非中文目录下
本次选用3.3.6的版本。下载地址
Apache Hadoop
然后下载windows依赖包(依赖包支持版本应与Hadoop版本相匹配),并将依赖包解压至hadoop-3.3.6\bin目录下覆盖文件。
winutils包含绝大多数Hadoop版本
环境变量配置
- 配置
HADOOP_HOME环境变量
环境变量的位置在计算机-属性-高级系统设置-环境变量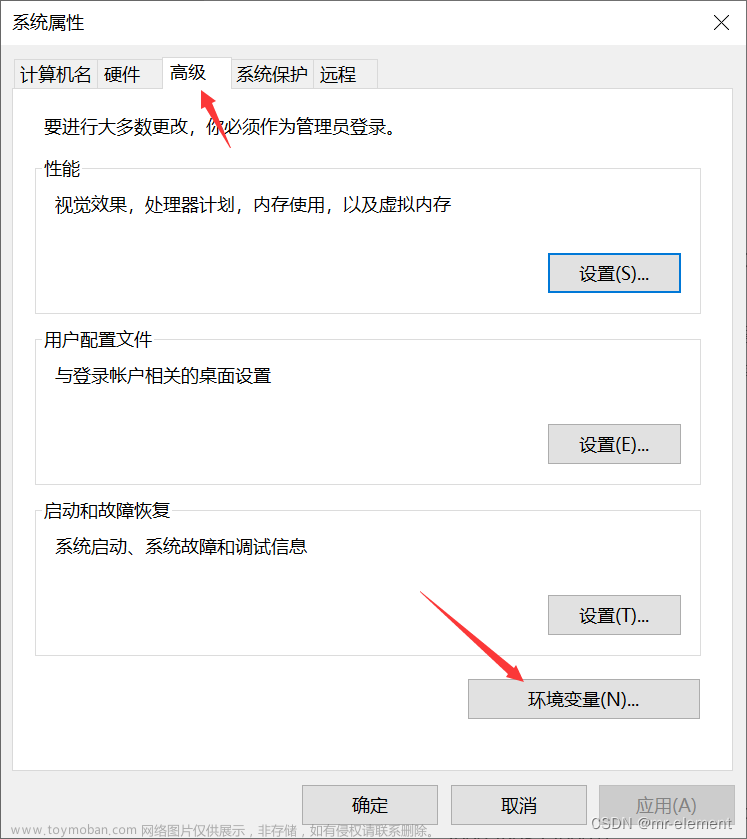
根据新建HADOOP_HOME系统变量你的Hadoop目录来填写
然后在用户变量选择Path点击编辑,新建以下变量
%HADOOP_HOME%\bin
%HADOOP_HOME%\sbin

验证Hadoop环境变量是否正常。双击hadoop-3.3.6\bin\winutils.exe,如果报如下错误。说明缺少微软运行库(正版系统往往有这个问题)。如果没有报错,而是黑色运行框一闪而过则代表运行正常。
运行库程序安装地址微软运行库修复
Maven的下载与配置
Maven的下载与安装
- Maven下载(本次使用版本为3.9.4版)
官网下载地址 - 下载完成后将压缩包解压到不含中文路径的目录里
- 在maven的文件夹里新建一个
repository用来存放仓库文件
Maven的配置
- 打开
apache-maven-3.9.4\conf路径下的settings.xml文件 - 定位到以下内容
<!-- localRepository
| The path to the local repository maven will use to store artifacts.
|
| Default: ${user.home}/.m2/repository
-->
- 在其后面增加内容:(repository路径填写为你刚刚新建的repository的路径)
<localRepository>repository路径</localRepository>

4. 设置镜像源
5. 依旧在settings.xml文件
6. 注释掉源镜像,并添加阿里镜像
<mirror>
<id>nexus-aliyun</id>
<name>nexus-aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
<mirrorOf>central</mirrorOf>
</mirror>
<!--
<mirror>
<id>maven-default-http-blocker</id>
<mirrorOf>external:http:*</mirrorOf>
<name>Pseudo repository to mirror external repositories initially using HTTP.</name>
<url>http://0.0.0.0/</url>
<blocked>true</blocked>
</mirror>
-->

7. 保存该文件
IDEA
在IDEA中修改Maven设置
- 按下
Ctrl+Alt+S打开IDEA的设置界面 - 依次选择
Build, Execution, Deployment——Build Tools——Maven
- 依次修改,并勾选
Use settings from .mvn/maven.config
Maven home path: Maven文件夹所在路径
User settings file: settings.xml所在路径
Local repository: repository所在路径

修改完成后保存
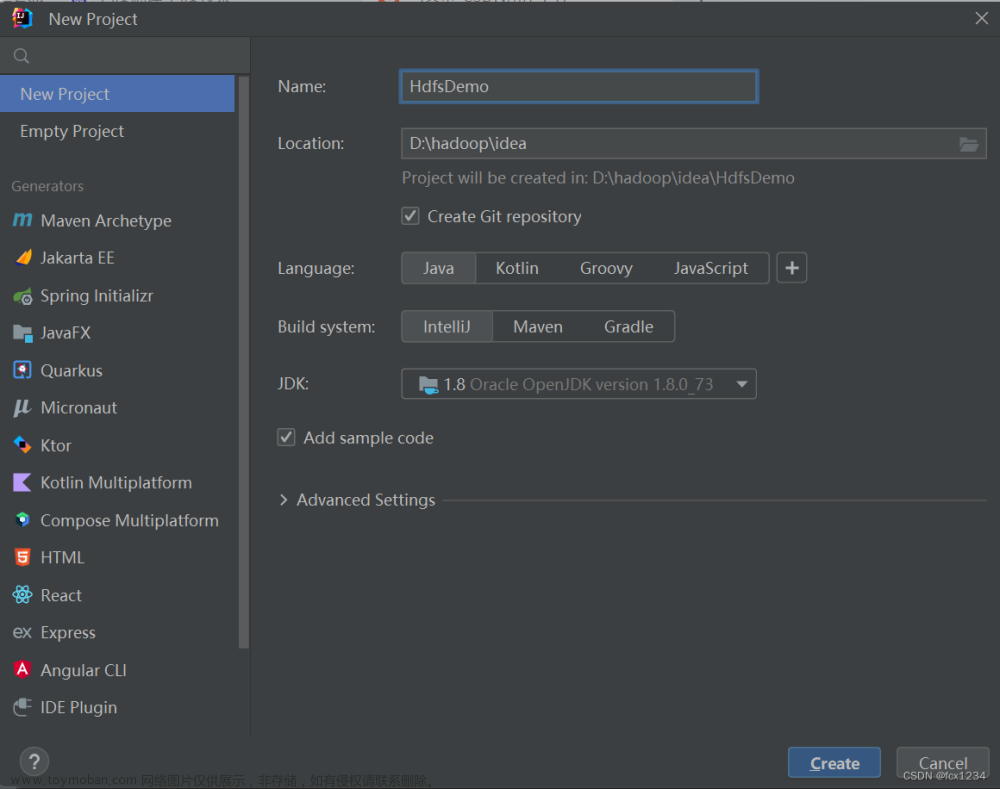
在IDEA中创建Maven工程
- 打开IDEA,选择
File-New-Project
- 选择
Maven Archetype其中Archetype选择为maven-archetype-quickstart
打开Advanced Settings可以设置更多,其他的选项根据自己的需求来(对应翻译如下图所示)。
- 导入相应的依赖坐标+日志添加,将下述内容粘贴到
pom.xml的</project>之前
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.6</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.30</version>
</dependency>
</dependencies>
注意hadoop-client的版本号根据你下载的版本修改,依赖包通过网络下载,下载速度与网速有关
4. 在项目的 src/main/resources目录下,新建一个文件,命名为“log4j.properties”,在文件中填入 (打印日志,级别)
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n

5. 创建包名:com.hadoop.hdfs (在java下)
8. 创建 HdfsClient 类
9. HdfsClient 类中,输入
package com.hadoop.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.Test;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
public class HdfsClient {
@Test
public void testMkdirs() throws IOException, URISyntaxException, InterruptedException {
// 1 获取文件系统
Configuration configuration = new Configuration();
//错误演示:没有设置用户,会报权限错误 FileSystem fs = FileSystem.get(newURI("hdfs://hadoop102:8020"), configuration);
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop01:8020"), configuration,"root");
//hadoop01修改为namenode所在节点的地址
// 2 创建目录
fs.mkdirs(new Path("/xiyou/huaguoshan/"));
// 3 关闭资源
fs.close();
}
}
若有下划波浪线表示需要抛出异常(alt+Enter)Ctrl+p提示函数的参数
10. 执行程序
若程序可以正常运行,则在hdfs系统中会出现/xiyou/huaguoshan/文件夹。
客户端去操作 HDFS 时,是有一个用户身份的。默认情况下,HDFS 客户端 API 会从采
用 Windows 默认用户访问 HDFS,会报权限异常错误。所以在访问 HDFS 时,一定要配置用户。
org.apache.hadoop.security.AccessControlException: Permission denied:
user=56576, access=WRITE,
inode="/xiyou/huaguoshan":hadoop:supergroup:drwxr-xr-x
- 程序改进:常用步骤进行封装
(1)首先将准备工作封装到init中,如下:
public void init() throws URISyntaxException, IOException, InterruptedException {
//连接的集群的nn地址
URI uri = new URI("hdfs://hadoop102:8020"); //8020为hdfs内部通信端口
// URI uri = new URI("hdfs://hadoop102:8020")
//创建一个配置文件
Configuration conf = new Configuration();
//用户
String user = "hadoop";
//获取到客户
// 端对象
fs = FileSystem.get(uri, conf,user);
}
此处init中的fs若要在close()和testMkdirs()使用,必须定义为全局变量。选中fs按ctrl+alt+f会弹出定义形式,按enter键定义。
(2)将关闭资源的操作也进行封装,如下:
public void close() throws IOException {
//3.关闭资源
fs.close();
}
(3)原先的testMkdirs() 函数仅用于处理主逻辑即可:文章来源:https://www.toymoban.com/news/detail-801009.html
public void testMkdirs() throws URISyntaxException, IOException, InterruptedException {
//2.创建一个文件夹
fs.mkdirs(new Path("/xiyou/huaguoshan1"));
}
(4)最后:要利用Junit测试,@Test指定要测试的代码,@Before指定执行测试代码前要执行的初始化代码,@After指定在指定代码执行之后要执行的操作。文章来源地址https://www.toymoban.com/news/detail-801009.html
到了这里,关于Windwos安装Hadoop 并在IDEA中利用Maven实现HDFS API操作的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!