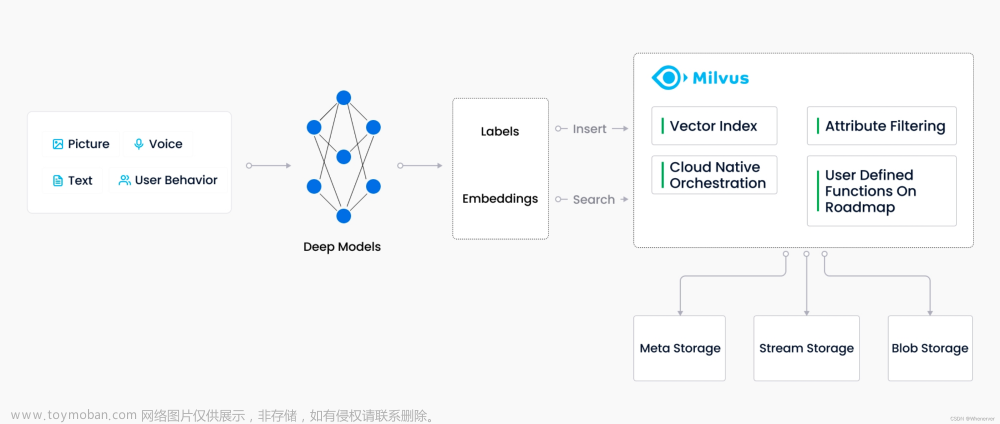
在数据库中,Schema 常有,而动态 Schema 不常有。
文章来源地址https://www.toymoban.com/news/detail-801363.html
例如,SQL 数据库有预定义的 Schema,但这些 Schema 通常都不能修改,用户只有在创建时才能定义 Schema。Schema 的作用是告诉数据库使用者所希望的表结构,确保每行数据都符合该表的 Schema。NoSQL 数据库通常都支持动态 Schema 或可以不创建 Schema(即在创建数据库时无需为每个对象定义属性)。
而在 Milvus Cloud社区中,支持动态 Schema 亦是呼声较高的功能之一。为了更好地满足用户需求,Milvus Cloud在 2.2.9 中发布了这一功能,数据库 Schema 便可以根据用户添加数据而“动态变化”。此后,用户无需像以前一样在插入数据时严格遵循预先定义的 Schema,可以像在 NoSQL 数据库中一般,以 JSON 格式添加数据。
不过,我们发现很多用户对于在向量数据库中使用动态 Schema 的 A、B 面及其作用仍有不少疑问,本文将一一解答。
01.
什么是数据库 Schema?
什么是数据库 Schema?我们举例来看:

Schema 定义了如何在数据库中插入和存储数据,上图展示了如何为关系型数据库创建一个标准的 Schema。
在上图的数据库中, 一共有 4 张表,每张表都有各自的 Schema。图片中间的表有 4 列数据,其余 3 张表有 2 列数据。
此外,我们还需要在 Schema 中定义数据类型。“Employee”、“Title”和“DeptName”列都将是字符串(即VARCHAR),“CourseID”也是字符串,“EmpID”和“DeptID”列数据是整数,而“Date”列数据类型可以是日期或 VARCHAR。
02.
什么是向量数据库 Schema?文章来源:https://www.toymoban.com/news/detail-801363.html
到了这里,关于一文详解向量数据库Milvus Cloud动态 Schema的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!