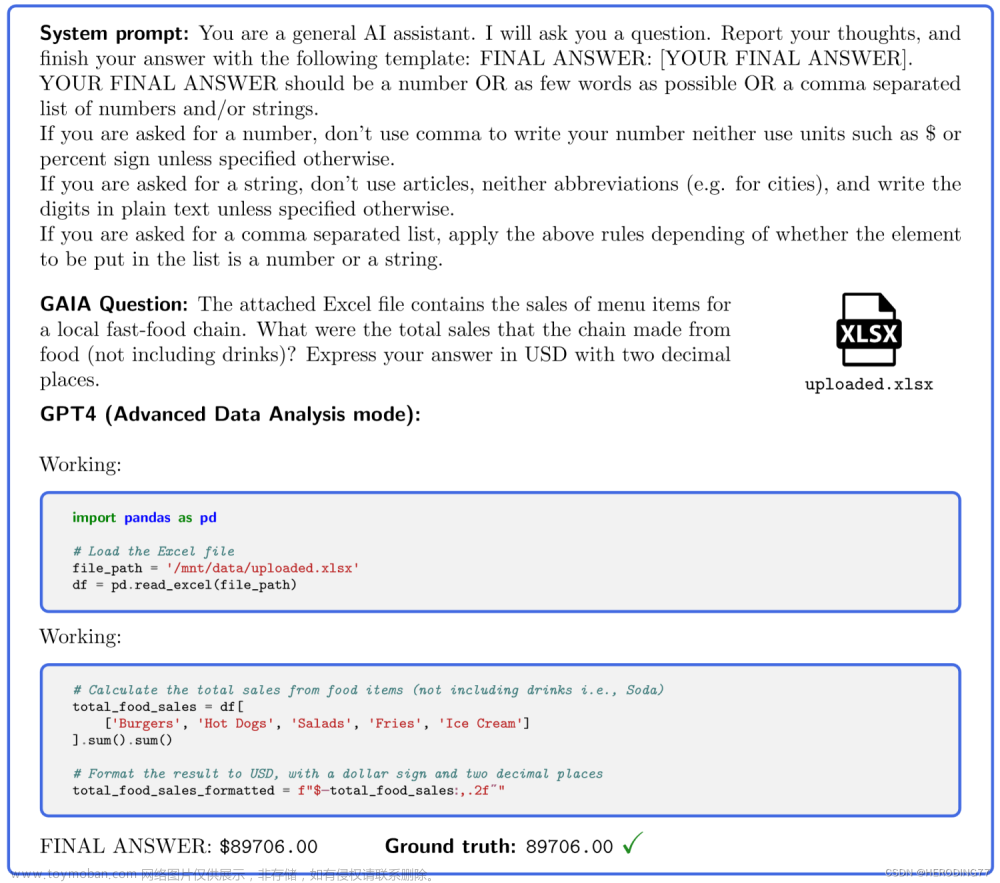
一、论文信息
1 论文标题
TRACE: A Comprehensive Benchmark for Continual Learning In Large Language Models
2 发表刊物
arXiv2023
3 作者团队
复旦大学
4 关键词
Benchmark、Continual Learing、LLMs
二、文章结构
三、引言
1 研究动机
- 已经对齐过的大模型 (Aligned LLMs )能力很强,但持续学习能力缺乏关注;
- 目前CL的benchmark对于顶尖的LLMs来说过于简单,并且在指令微调存在model的potential exposure。(这里的exposure是指什么,在担心安全吗?)
2 任务背景
Intro-P1:
- LLMs (通用能力)+fine-tuning (特长能力)+alignment(安全) 已经统治了NLP。但是对模型的需求能力仍然在增长,尤其是在domain-specific knowledge, multilingual proficiency, complex task-solving, tool usage等方面。
- 但重头训练LLMs代价太大不现实,因此通过持续学习方式incrementally训练已有的模型显得非常重要。这就引出一个重要问题:To what degree do Aligned LLMs exhibit catastrophic forgetting when subjected to incremental training?
Intro-P2:
目前的CL benchmark不适合用于评估SOTA LLMs,原因如下:
- 很多常见且简单的NLU数据集。对于LLMs来说太简单,而且很多已经作为训练数据喂给LLMs,再用来evaluate不合适。
- 现存的benchmark只关注模型在序列任务的表现,缺乏对新任务泛化性、人类指令遵循性和安全保护性等方面的评估。
Intro-P3:
提出了适用于aligned LLMs的CL benchmark: TRACE
- 8 distinct datasets spanning challenging tasks
- domain-specific tasks
- multilingual capabilities
- code generation
- mathematical reasoning
- equal distribution
- 3 metrics
- general ability delta
- instruction following delta
- safety delta
Intro-P4:
在TRACE上评估了5个LLMs:
- 几乎所有LLMs在通用能力上都会明显下降;
- LLMs的多语言能力会提高;
- 全量微调相比LoRA更容易合适目标任务,但在通用能力上下降明显;
- LLMs的指令遵循能力也会下降;
Intro-P5:
- 使用一些推理方法会有效保存模型的能力;
- 提出了 Reasoning-augmented Continual Learning (RCL)
- not only boosts performance on target tasks but also significantly upholds the inherent strengths of LLMs;
3 相关工作
3.1 CL
经典3分类,可以参考之前的文章。
3.2 CL Benchmark in NLP
Standard CL Benchmark;
15个分类;
3.3 COT
COT;
Zero shot COT;
fine-tune COT;
四、创新方法
1 模型结构
![[论文阅读笔记] TRACE: A Comprehensive Benchmark for Continual Learning In Large Language Models,阅读笔记,持续学习,大语言模型,论文阅读,笔记,语言模型,自然语言处理,人工智能](https://imgs.yssmx.com/Uploads/2024/01/801421-1.png)
TRACE consists of two main components:
- A selection of eight datasets constituting a tailored set of tasks for continual learning, covering challenges in domain-specific tasks, multilingual capabilities, code generation, and mathematical reasoning.
- A post-training evaluation of LLM capabilities. In addition to traditional continual learning metrics, we introduce General Ability Delta, Instruction Following Delta, and Safety Delta to evaluate shifts in LLM’s inherent abilities.
2 数据构建
![[论文阅读笔记] TRACE: A Comprehensive Benchmark for Continual Learning In Large Language Models,阅读笔记,持续学习,大语言模型,论文阅读,笔记,语言模型,自然语言处理,人工智能](https://imgs.yssmx.com/Uploads/2024/01/801421-2.png)
3 评测指标
- General Ability Delta: Δ R t G = 1 M ∑ i = 1 M ( R t , i G − R 0 , i G ) \Delta R_t^G=\frac1M\sum_{i=1}^M(R_{t,i}^G-R_{0,i}^G) ΔRtG=M1∑i=1M(Rt,iG−R0,iG), 其中 t , i t,i t,i表示已经训练到第t个任务时的模型在第i个任务上的表现。 0 , i 0,i 0,i表示模型直接在i上的表现。
- Instruction Following Delta: Δ R t I = 1 N ∑ i = 1 N ( R t , i I − R 0 , i I ) \Delta R_t^I=\frac1N\sum_{i=1}^N(R_{t,i}^I-R_{0,i}^I) ΔRtI=N1∑i=1N(Rt,iI−R0,iI)
- Safety Delta: Δ R t S = 1 L ∑ i = 1 L ( R t , i S − R 0 , i S ) \Delta R_t^S=\frac1L\sum_{i=1}^L(R_{t,i}^S-R_{0,i}^S) ΔRtS=L1∑i=1L(Rt,iS−R0,iS)
上述指标计算方式一致,区别在于用于评测的数据集不同。
4 实验设置
4.1 baselines
-
Sequential Full-Parameter Fine-Tuning (SeqFT): This method involves training all model
parameters in sequence. - LoRA-based Sequential Fine-Tuning (LoraSeqFT): Only the low-rank LoRA matrices are fine-tuned, leaving the LLM backbone fixed. This method is chosen based on prior findings of reduced forgetting with ”Efficient Tuning” .
- Replay-based Sequential Fine-Tuning (Replay): Replay, a common continual learning strategy, is employed for its simplicity and effectiveness. We incorporate alignment data from LIMA into the replay memory, replaying 10% of historical data.
- In-Context Learning (ICL): Task demonstrations are supplied as part of the language prompt, acting as a form of prompt engineering. A 6-shot setting is used for our experiments.
To evaluate the resilience of safety alignment models from diverse training backgrounds and strategies, we select five aligned models from three organizations:
- Meta:
- LLaMa-2-7B-Chat,
- LLaMa-2-13B-Chat
- BaiChuan:
- Baichuan 2-7B-Chat
- Large Model Systems Organization
- Vicuna-13B-V1.5
- Vicuna-7B-V1.5
实验结果
主实验结果表格![[论文阅读笔记] TRACE: A Comprehensive Benchmark for Continual Learning In Large Language Models,阅读笔记,持续学习,大语言模型,论文阅读,笔记,语言模型,自然语言处理,人工智能](https://imgs.yssmx.com/Uploads/2024/01/801421-3.png)
序列任务上的表现
- In-Context Learning (ICL) Performance: ICL methods generally perform lower than SeqFT and Replay methods. This suggests that the TRACE benchmark is indeed challenging, and LLMs can’t readily identify solutions just through simple demonstrations.
-
Replay Performance: Among all the baselines, Replay achieved the highest OP score. With its
BWT score being positive, it indicates that Replay effectively retains its performance on sequential tasks without significant forgetting. This makes Replay a straightforward and efficient strategy in a continual learning context. -
Full Parameter Training vs. LoRA: Full parameter training demonstrates better task-specific
adaptability compared to LoRA, with a smaller BWT score. For instance, LLaMA-2-7B-Chat’s
SeqFT OP(BWT) is 48.7 (8.3%), while LoRASeqFT stands at 12.7 (45.7%). This suggests that
when the focus is primarily on sequential tasks, full parameter fine-tuning should be prioritized over parameter-efficient methods like LoRA.
通用能力的适应
From the Model Perspective:
- Nearly all models display a negative General Ability Delta, indicating a general decline in overall capabilities after continual learning.
- Larger models, in comparison to their smaller counterparts, show a more pronounced (明显的) forgetting in factual knowledge and reasoning tasks.
From the Task Perspective:
- Despite the presence of CoT prompts, there is a noticeable decline in math and reasoning abilities across all models, suggesting that these abilities are highly sensitive to new task learning.
- Excluding the llama2-7b model, most models exhibit a significant drop in performance on MMLU, suggesting a gradual loss of factual knowledge through continual learning.
- TydiQA task sees a general boost post-training, possibly due to the inclusion of Chinese and German datasets in our sequential tasks. Even more intriguing is the observed enhancement (and some declines) in other languages on TydiQA, suggesting potential cross-linguistic transfer characteristics.
- Performance shifts on PIQA for most models are subtle(不明显的), indicating the relative robustness of commonsense knowledge during continual learning.
From the Methodological Perspective:
- The Replay method proves beneficial in preserving reasoning and factuality skills. Especially for larger models, the mitigation of forgetting through Replay is more pronounced. For instance, for LLaMA-2-7B-Chat, Replay offers a 6.5 EM score boost compared to methods without Replay, while for LLaMA-2-13B-Chat, the increase is 17.1 EM score.
实验图1![[论文阅读笔记] TRACE: A Comprehensive Benchmark for Continual Learning In Large Language Models,阅读笔记,持续学习,大语言模型,论文阅读,笔记,语言模型,自然语言处理,人工智能](https://imgs.yssmx.com/Uploads/2024/01/801421-4.png)
- Figure 2 (a) illustrates the win rate % for instruction following sequentially trained LLMs and their original versions. Here, the win rate can be approximated as an indicator for the Instruction-following delta. It’s evident that all three training methods exhibit a marked decline in instruction-following capabilities compared to their initial versions, with the decline being most pronounced in the LoRA method. Therefore, be cautious when exploring approaches like LoRA for continual learning in LLMs. 概括:说明LoRA微调完很可能不遵循指令。
- Figure 2(b) shows the win rate % for instruction following between the new LLMs and their starting versions. Here, the win rate can be used as a measure for the Safety Delta. Compared to the original models, most answers were rated as ’Tie’. This suggests that the safety of the model’s answers is largely unaffected by continual learning on general tasks. 概括:说明大部分情况下安全性不太受持续学习训练的影响。
LLMs遗忘的影响因子
数据质量和训练步数
![[论文阅读笔记] TRACE: A Comprehensive Benchmark for Continual Learning In Large Language Models,阅读笔记,持续学习,大语言模型,论文阅读,笔记,语言模型,自然语言处理,人工智能](https://imgs.yssmx.com/Uploads/2024/01/801421-5.png)
- Performance improves as data volume grows, indicating at least 5000 samples from the TRACE-selected datasets are needed for full fitting.
- Performance improves with up to 5 training epochs, confirming our baseline epoch setting balances target task optimization and retaining existing capabilities.
![[论文阅读笔记] TRACE: A Comprehensive Benchmark for Continual Learning In Large Language Models,阅读笔记,持续学习,大语言模型,论文阅读,笔记,语言模型,自然语言处理,人工智能](https://imgs.yssmx.com/Uploads/2024/01/801421-6.png)
How exactly does the reasoning capability of LLMs transform during the continual learning process?
- a surge in the model’s reasoning prowess post-training on the ScienceQA task, while it declined for other tasks.
- even though the two tasks from NumGLUE are mathematically inclined, their answers don’t provide a clear reasoning path. ScienceQA does offer such a pathway in its answers. This observation suggests the potential advantage of incorporating reasoning paths during training to preserve and perhaps even enhance the model’s reasoning capability.
Reasoning-Augmented Continual Learning
motivation:
Instead of treating LLMs as traditional models and inundating them with large volumes of data to fit a task’s distribution, might we leverage their inherent abilities for rapid task transfer?
method
![[论文阅读笔记] TRACE: A Comprehensive Benchmark for Continual Learning In Large Language Models,阅读笔记,持续学习,大语言模型,论文阅读,笔记,语言模型,自然语言处理,人工智能](https://imgs.yssmx.com/Uploads/2024/01/801421-7.png)
results
![[论文阅读笔记] TRACE: A Comprehensive Benchmark for Continual Learning In Large Language Models,阅读笔记,持续学习,大语言模型,论文阅读,笔记,语言模型,自然语言处理,人工智能](https://imgs.yssmx.com/Uploads/2024/01/801421-8.png) 文章来源:https://www.toymoban.com/news/detail-801421.html
文章来源:https://www.toymoban.com/news/detail-801421.html
讨论
Can traditional continual learning methods be effectively applied to LLMs?
![[论文阅读笔记] TRACE: A Comprehensive Benchmark for Continual Learning In Large Language Models,阅读笔记,持续学习,大语言模型,论文阅读,笔记,语言模型,自然语言处理,人工智能](https://imgs.yssmx.com/Uploads/2024/01/801421-9.png) 文章来源地址https://www.toymoban.com/news/detail-801421.html
文章来源地址https://www.toymoban.com/news/detail-801421.html
- High Training Cost: LLMs require significant data for both pre-training and alignment, leading to a high training cost. Using simple replay to maintain past capabilities can be very expensive. Therefore, selecting key data from past training to keep LLMs’ diverse predictive abilities is essential.
- Large Number of Parameters: The huge parameter size of LLMs demands advanced hardware for training. Many regularization techniques need to store gradients from past tasks, which is a big challenge for both CPU and GPU memory.
- One-for-All Deployment of LLMs: LLMs are designed for a wide range of tasks, meaning tailoring parameters for specific tasks might limit their ability to generalize to new tasks. Additionally, methods that adjust the network dynamically can complicate deployment, as it becomes tricky to handle multiple task queries at once.
How should LLMs approach continual learning?
- Direct end-to-end training of Language Model (LLMs) might cause them to excessively focus on specific patterns of the target task, potentially hindering their performance in more general scenarios.
- LLMs are already trained on diverse datasets and possess the ability to handle multiple tasks, even with limited examples. Building upon the Superficial Alignment Hypothesis proposed by LIMA, the focus should be on aligning LLMs’ existing capabilities with new tasks rather than starting from scratch.
- Therefore, strategies like the RCL approach, which leverage LLMs’ inherent abilities for quick transfer to novel tasks, can be effective in mitigating catastrophic forgetting.
到了这里,关于[论文阅读笔记] TRACE: A Comprehensive Benchmark for Continual Learning In Large Language Models的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!