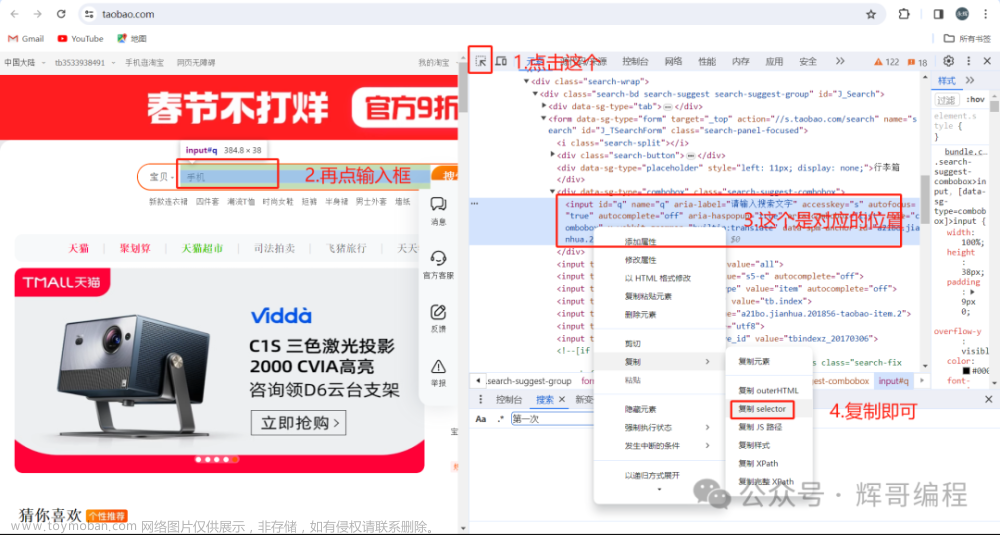
== 测试环境:
1) Selenium:
pip config set global.index-url --site https://pypi.tuna.tsinghua.edu.cn/simple
pip install selenium hashlib xlrd xlwt pandas numpy hashlib
#chromedriver for version>
解压chromedriver文件,放置chrome的安装目录下
https://edgedl.me.gvt1.com/edgedl/chrome/chrome-for-testing/119.0.6045.21/win64/chromedriver-win64.zip
-----------------------------------
global driver # 设置全局变量
chromedriver_path =r"C:\Users\AppData\Local\Google\Chrome\Application\chromedriver.exe"
driver = webdriver.Chrome(chromedriver_path)
driver.get("https://baidu.com/")
-----------------------------------
#firefox dirver geckodriver
解压geckodriver文件,放置firefox的安装目录下
https://mirrors.huaweicloud.com/geckodriver/v0.34.0/geckodriver-v0.34.0-win64.zip
2) python38 + anaconda +Jupyter notebook
=== 参考文章 :
a ) Selenium操作全指南,2w字超全总结
https://blog.csdn.net/IT_LanTian/article/details/122986725?utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_baidulandingword~default-0-122986725-blog-80609651.235^v40^pc_relevant_rights_sort&spm=1001.2101.3001.4242.1&utm_relevant_index=3
b ): Firefox 添加 selenium ID
第一步:打开火狐浏览器,找到最右边的菜单,选择附加组件,如图所示
找到selenium IDE添加到Firefox,进行安装;
解决find_element_by_id方法被弃用
https://blog.csdn.net/alijunshan/article/details/128730615
===code
import hashlib
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
#webdriver.Firefox(executable_path="C:/tmp/geckodriver.exe")
login_url = 'https://www.ybm100.com/login/login.htm' # 登录页面的URL
url=login_url
driver = webdriver.Firefox()
#driver = webdriver.Firefox(executable_path="C:/tmp/geckodriver.exe")
#driver.get('https://www.baidu.com')
driver.get(url)
#driver.find_element_by_xpath("//input[@id='kw']").send_keys("selenium")
#driver.find_element_by_xpath("//input[@id='su']").click()
driver.maximize_window()
#元素定位用户名输入框
username=driver.find_element(By.ID,"inputPhone")
#输入用户名
username.send_keys("xxxxx")
#元素定位密码输入框
password=driver.find_element(By.ID,"inputPassword")
pstring = "xxx"
# 创建MD5对象
hash_object = hashlib.md5()
# 更新MD5对象,传入要加密的字符串
hash_object.update(pstring.encode())
# 获取加密后的字符串
md5_str = hash_object.hexdigest()
#输入密码
password.send_keys(md5_str)
driver.find_element(By.ID,"agreement").click()
#元素定位登录按钮
#login=driver.find_element(By.CLASS_NAME,"sui-btn btn-primary")
login=driver.find_element(By.CLASS_NAME,"sui-btn")
#点击登录
login.click()文章来源:https://www.toymoban.com/news/detail-802079.html
#等待1s
sleep(10)文章来源地址https://www.toymoban.com/news/detail-802079.html
到了这里,关于爬虫小试 Selenium+Firefox的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!