正文开始前给大家推荐个网站,前些天发现了一个巨牛的 人工智能学习网站, 通俗易懂,风趣幽默,忍不住分享一下给大家。 点击跳转到网站。
命令行参数
什么是命令行参数?
我们平时写的代码中写写到的主函数main函数是可以有参数的。

我们可以看一下这段代码的运行结果。
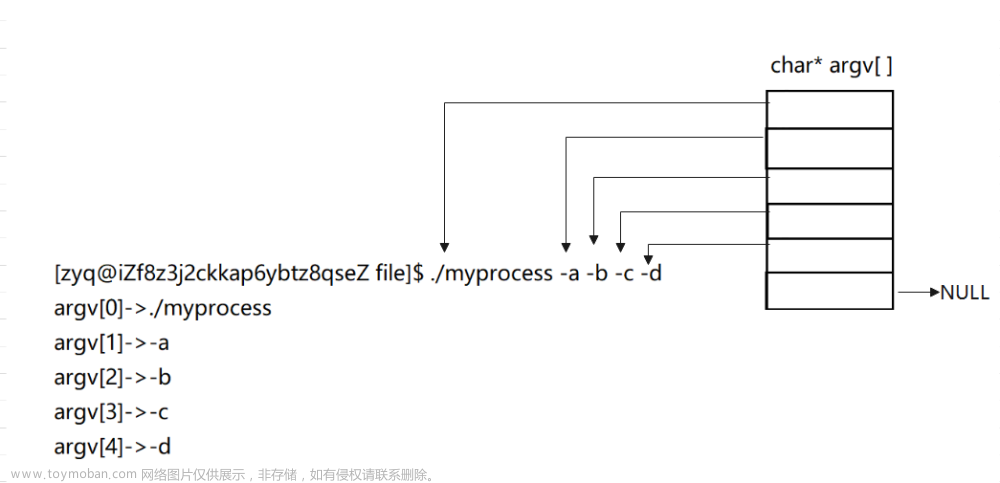
我们可以看到我们输入的字符串被一空格为分隔符分成了若干个字串,并且argc就是字串的个数,argv中放的都是被分割出来的字串。而argv数组最后一个原始是存放的空的,有了这个东西,我们的程序就可以支持各种各样的命令行级别的指令选项的设置,也是为了让我们的一个程序对不同的选项做出不同的动作。
环境变量
环境变量(environment variables)一般是指在操作系统中用来指定操作系统运行环境的一些参数如:我们在编写C/C++代码的时候,在链接的时候,从来不知道我们的所链接的动态静态库在哪里,但是照样可以链接成功,生成可执行程序,原因就是有相关环境变量帮助编译器进行查找。环境变量通常具有某些特殊用途,还有在系统当中通常具有全局特性。
常见的环境变量
我们在执行自己的可执行程序但是都需要加一个./,不然运行不要,系统找不到我们的可执行程序,但是在执行系统的命令是却不需要这样做,直接输入程序名称就可以运行,这是为什么?为什么系统的命令直接就可以执行我们的程序就必须要加一个./,我们直到不管是什么程序,系统要执行,就必须找到它,我们的执行不了而系统的可以执行只有一个原因,就是系统中一定存在默认的搜索路径。
这个默认的搜索路径就放在一个环境变量PATH中。Linux中可以使用$环境变量来查看环境变量中的内容。
所以PATH环境变量就是存放系统默认的搜索路径。只要我们将我们自己的程序的路径加到这个默认路径中,我们的进程也可以直接运行。
除了PATH环境变量外还有HOME,PWD等等很多环境变量。
其中HOME就是我们的家目录,PWD就是我们当前所处的目录。
这也就可以解释为为什么我们普通用户登录后是在/home/xxx,而root是在/root下的原因了。

系统中会存在大量的环境变量,每一个环境变量都有它自己特殊的用途,用来完成特定的系统功能。
在Linux中查看所有的环境变量命令是env。
我们也可以创建环境变量,在Linux中直接在命令行中使用 环境变量名=什么 就可以创建一个变量,不过这种变量不是环境变量叫做本地变量,我们需要用export导出一下才是环境变量,而且每一次我们重新登录服务器时,环境变量都会被更新,不会保留之前的操作,也就是说,就算我们修改了系统的环境变量也没关系,只需要重新登录一下云服务器就好了,那么为什么这样呢?
我们的命令行启动的进程都是shell/bash的子进程,子进程的命令行参数和环境变量都是父进程给我们传递的,而我们更改的是命令行内部的环境变量信息,而我们每一次重新登录都会给我们都会给我们形成新的bash解释器并且新的bash解释器自动读取新的环境变量表信息,所以我们可以大胆的推测,父进程的环境变量是以脚本配置的文件存在的。
而在我们目前的系统中,我们每一次登录我们的bash都会读取 .bash_profile文件,文件中的内容为我们形成一张环境变量表信息。
这个文件一般是存在我们的家目录中的。
我们在外面可以很好的获取环境变量,但是编码如何获取环境变量呢?
- 我们可以通过函数getenv来获取环境变量

- main函数是可以有第三个参数的,第三个参数就是环境变量表

这个环境变量表最后也是以null结尾的。
- C语言是有一个全局变量指向环境变量表的

我们可以直接使用envrion来获取环境变量。

环境变量通常具有全局属性,可以被子进程继承下去。
如果我们把PATH清空,我们会发现大部分命令都跑不了,但是还有一部分命令是可以跑的。
我们知道Linux是又C/C++写的,Linux中大部分命令都是子进程,但是也有一部分是Shell的一个函数。
所以Linux的命令就分为两种:
- 常规命令,Shell使用fork让子进程去执行的
- 内建命令,Shell命令行的一个函数
本地变量VS环境变量
本地变量只在bash内部有效,不会被子进程继承下去,而环境变量通过让所有子进程继承的方式实现自身的全局属性。
进程地址空间
对于我们C/C++程序员来说,内存空间一般分为如下几个区域:
其中堆和栈中间有一块很大的区域,堆是向上增长的,而栈是向下增长的,堆栈相对而生。我们创建的变量都是指向低地址的起始位置,变量的本质就是起始地址+偏移量的访问形式。那么这个东西就是我们平时在系统层面说的内存吗?我们可以先来看一个代码
#include <stdio.h>
2 #include <sys/types.h>
3 #include <unistd.h>
4 int val = 10;
5 int main()
6 {
7 pid_t id = fork();
8
9 if(id == 0)
10 {
11 //子进程
12 int cnt = 5;
13 while(1)
14 {
15 if(cnt--==0)
16 {
17 val = 5;
18 }
19 printf("i am child, i am pid %d, val = %d, &val = %p\n",getpid(),val,&val);
20 sleep(1);
21 }
22 }
23 else{
24 while(1)
25 {
26 printf("i am parent, i am pid %d, val = %d, &val = %p\n",getpid(),val,&val);
27 sleep(1);
28 }
29 }
30 return 0;
31 }

我们可以看到在5秒过后,父进程和子进程的val地址一样,但是里面的内容确不一样,那么就只有一个原因,就是他们一定不是物理内存。我们平时写代码用到的地址都是虚拟地址/线性地址。所以说上面的那个图不是内存,是进程地址空间!
在进程地址空间和物理内存中间存在一个叫页表的东西,而页表就是虚拟地址对应映射的物理地址,也就是说,我们每一个运行起来的进程都会有一个进程地址空间,并且都要在系统层面有自己的页表映射结构。
当我们的父进程创建子进程是,把它的进程地址空间和页表都给子进程拷贝一份,然后他们遵循写时拷贝的原则,当需要修改时,由于进程间是存在独立性的,所以子进程修改不能影响父进程,所以它就要重新再物理内存中开一块空间,然后修改自己的页表映射,所以才会存在同一块地址但是里面的东西是不一样的,本质就是他们映射的物理内存是不一样的。

地址空间每一个进程都有,所以OS也要对地址空间进行管理,所以地址空间就是一个内核的数据结构对象,就是一个内核结构体,里面需要对各个区域进行划分,我们每一个进程都可以使用00000000~FFFFFFFF这么大的内存,但是每个进程都不可能使用这么多的内存,因为就算你能用的了OS也不会允许,所以每一地址空间的内核数据结构中都是一些XXX_start,XXX_end的一些字段,表示一个区域的范围,如果某个需要增加,就修改字段就可以了。在Linux中这个虚拟地址空间就是叫做 struct mm_struct{}.
页表结构除了有虚拟地址->物理地址的映射外,在页表的后面还会存在两个字段,一个是该区域的访问权限字段,还有一个是映射的物理地址是否进行了空间分配&&是否存在内容,我们知道对于代码段和字符常量去的数据是不可以修改的,所以有人恶意修改的话,OS在页表层面就把它阻止了,所以我们平时对字符常量没法修改,本质还是它在页表映射中访问权限为只读,而第二个字段就是如果我们进程在阻塞的时候,OS可能会把我们的代码和数据暂时移除内存,所以我们在访问前要先看数据是否在内存中,如果不在内存中,OS就需要为我们开辟物理内存,把数据拷贝进来,然后进行页表映射,然后才能正常的执行我们的代码,该过程也叫做缺页中断。
CPU中是存在一个寄存器CR3存的是页表的地址(物理地址).
为什么存在进程地址空间呢?
- 让进程以统一的视角看待内存,所以任意一个进程,可以通过地址空间+页表将乱序的内存数据变为有序,分门别类规划好。
- 存在虚拟地址空间和页表,可以很好的进行访问内存的安全检查。
- 通过页表,进程管理只管页表左边的一部分,不管右边的,右边的由操作系统的内存管理来完成,所以可以很好的将进程管理和内存管理解耦。而且通过页表可以让相同地址的内容映射到不同的物理地址中,实现进程的独立性。
写时拷贝文章来源:https://www.toymoban.com/news/detail-802151.html

我们知道创建子进程后,子进程和父进程数据和代码都是共享的,当有一方要修改时要发生写时拷贝,那么这个写时拷贝OS是什么时候做的呢?
其实在我们创建子进程时,代码和数据父进程和子进程都是共享的,并且他们在页表中的权限也被设置了为只读,所以当OS要进行写入时,会对它进程检查,如果是数据区是可以写入的,那么就写时拷贝,如果是代码区,本身就是只读的,就报错。所以当页表因为权限问题出错时,有可能是真的错了,也有可能不是出错,而是触发写时拷贝机制。文章来源地址https://www.toymoban.com/news/detail-802151.html
到了这里,关于命令行参数环境变量和进程空间地址的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!


![[Linux 进程(三)] 进程优先级,进程间切换,main函数参数,环境变量](https://imgs.yssmx.com/Uploads/2024/01/810166-1.png)