讲个有趣的小故事
我高二那年从乙班考入了甲班,对于那时的我 偏科英语最高只有108+班级平均英语成绩125+暴躁难为人女英语老师,使我上英语课时战战兢兢。英语老师很时尚,喜欢搞花里胡哨的词语让我们放松,也很尊重我虽然暴躁但维护着我的面子不让我出丑。
当时正逢《变形金刚》电影上映,我在电影院的海报里刚好看到了Transformer这个单词。周几的一天英语课,老师提问完我Transform这个词后问我知不知道Transformer什么意思,语气中带着平淡,似乎这是一个很平常的词,我应该会。班里鸦雀无声,知道老师开始"难为我这个新生(开玩笑)"了。
于是我扑通着心跳,以沉默的语气说出了"变形金刚",似乎就是一个很平常的词。那时我不但余光瞥见了老师的惊讶眼神,耳边还想起了同学们的"哇~"。
这也是为什么我选用这个封面。那是老师唯一一次考验我,她似乎看到了我的努力,我也没有辜负她的期待。
回归正题
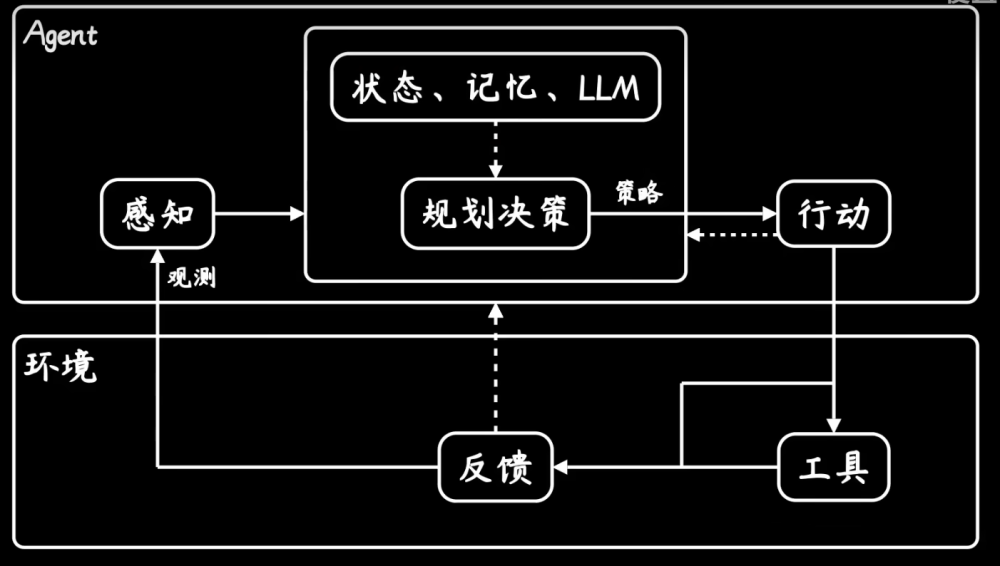
本文分成两个部分,前半部分我会以白话文(个人理解)的方式尽可能通俗易懂地将transformer介绍清楚,你只需要有一点CNN、RNN和一点文本处理的基础即可;后半部分我会以以前写AI遮天传的方式再把整体架构过一遍。学完这些再去做“transformer 实现看图说话”项目就显得很轻松啦。
文章内容较多,建议收藏。
一、Transformer是什么
我们以前学习过CNN、RNN以及它们的变种,像是VGG、Resnet、LSTM、GRU等等,都是神经网络模型,主要的工作就是在深度学习领域的“特征工程”中进行特征提取。
我们以CNN为例,回忆之前所学简单CNN模型的特点:卷积、池化、全连接,这些操作都是为了能够更好地将图片的特征提取出来:不同卷积层代表着不同感受野下提取不同的特征,同一层不同feature map又代表着该层不同方面的特征;哪怕是加上激活函数也是为了使得结果不断地向非线性(使直线弯折更加灵活)转化。通过反向计算不断地更新卷积核、全连接层等的参数,对比提高accuracy降低loss,得到最优秀的权重,来完成特征提取(重要的特征权重大)。

RNN同样有着自己的工作方式。在Transformer创作之初,它用来解决机器翻译(自然语言处理)方向“RNN无法并行计算”、“即使使用了GRU或者LSTM,RNN仍然需要注意力机制提供对于任意状态的访问”等问题,来自于论文“Attention is all you need”,于2017年在自然语言处理方向大火,2020年应用在计算机视觉方向后效果卓越,后续的bert、detr乃至如今爆火的chatGPT模型,都是基于Transformer来实现的。

所以,简单来说,transformer是一种近些年来非常优秀的网络模型、特征提取器(CV)、序列到序列(NLP)的转换器。
二、传统方法的问题
前面所说,它创作之初用来解决机器翻译(自然语言处理)中,RNN无法并行计算等问题。其基本组成依旧是传统机器翻译模型中常见的seq2seq网络,即序列到序列,所以会有编码器和解码器两个框架。
补充:许多NLP任务可以表述为序列到序列,再简单来说就是向量到向量:
机器翻译 (法语 → 英语)
总结 (长文本 → 短文本)
对话 (先前的话语 → 接下来的话语)
代码生成 (自然语言 → Python 代码)
旋律产生 (一个乐句 → 下一个乐句)
语音识别 (声音 → 文本)
回顾传统RNN,将其展开,它的下一个输入需要上一时刻的输出:

而transformer通过矩阵运算的形式完成了并行计算,这个后面会讲到。
此外,传统的word2vec也存在如“无法区分不同语境中同一个词的表达”,“训练好的向量就永久不变”这样的问题

而transformer通过前后文“注意力机制”来完成区分不同语境中同一个词的表达,(有一点点像n-gram,但本质不同,n-gram是滑动窗口部分,RNN变种是用门控开关来一个个设置词的权重,在我看来注意力机制是整体地观察上下文然后提取主干部分。后面会讲到。)
三、Attention、self-attention、multi-headed attention
即注意力、自注意力、多头注意力。
3.1 这里的注意力指的是什么
比如这里这句话:“小明今天开心地踢了一个绿色的皮球”,这句话的关键词/重要的部分是 "小明踢球",其他的次要,次次要。我们把注意力放在这些重要的上面,即分配一些权重。
这是在语言中,图片中也是一样的,比如猫狗识别,我记得猫有胡须而狗没有,可以把注意力放在胡须上。又或者说图片有前景和背景,我们应该把注意力放在更重要的前景里。
这样,我们人类下意识地提取出了"小明踢球" 和 猫狗识别时忽略背景、区分猫狗特征来完成识别,就叫做注意力。当然本质上还是权重的不同,不过本次引入了一种新的做法:自注意力。
3.2 self-attention是什么
顾名思义自注意力,自己注意自己这句话,以下面这句话为例:
The animal didn't cross the street because it was too tired.
The animal didn't cross the street because it was too narrow.
首先看第一句话,这个动物没有穿过街道因为它太累了。因此在进行动物这个词的计算的时候,动物没穿过街道因为累作为句子主体部分要被分予的注意力(权重)更大些。更精简一些则是动物累了,显然计算animal时animal和tired更加"引人注意"。
同理,动物没有穿过街道因为它太窄了,这里说的是街道窄,因此计算animal时更注意animal、street、narrow,计算street时更注意street、narrow。

我们观察上面这张图,我们不提计算动物、街道、累这几个词的时候,但看it这个词,在动物没有穿过街道因为它太累了这句话里it指的是动物,因此训练的效果应该是 The animal 对于it的注意力更大,颜色更深。
这里谁对于谁关乎到后面所学Q、K、V中Q*K这步操作,后面会介绍到。
一般到第五层的时候,单词就开始有根据地关注其他词。


3.3 self-attention如何计算
计算来了!不过放心这里先不写公式,依旧是白话文!

上图 以输入一句话(这里两个词)为例,Thinking和Machine,经过embedding后得到两个低维词向量X1, X2,接下来就要开始了:
此时出现 

 三个矩阵,我们先不管它是怎么来的(当然有W了那就证明是权重矩阵,既然是权重那就一开始初始化然后训练更新。) X1,X2分别与三个矩阵相乘,得到各自的q1、k1、v1和q2、k2、v2向量。当然放在一起就是矩阵乘以矩阵等于矩阵了。
三个矩阵,我们先不管它是怎么来的(当然有W了那就证明是权重矩阵,既然是权重那就一开始初始化然后训练更新。) X1,X2分别与三个矩阵相乘,得到各自的q1、k1、v1和q2、k2、v2向量。当然放在一起就是矩阵乘以矩阵等于矩阵了。

其中
Q:query,要去查询的
K:key,要被查询的
V:value,这个词的含义即实际特征
Q和K一起看,然后谈V
接下来,矩阵Q与矩阵K点乘,分开来看就是向量q1分别乘以k1,k2,k3... 向量q2分别乘以k1,k2,k3... ,放在一起不就是矩阵相乘吗。
至于Q*K的含义,可以这样理解,下图左侧各词分别是q1、q2...,右边是k1、k2...
不过就是单词->embedding->乘以一个 矩阵,一个放在左边一个放在右边,每个单词相互之间进行计算嘛。
矩阵,一个放在左边一个放在右边,每个单词相互之间进行计算嘛。
以上方Thinking和Machine为例的话,计算Thinking就是q1·k1, q1·k2

如果这里q1和k1有关系的话那两个向量就接近于平行内积大,无关则是垂直向量点乘为0.
计算完之后,接下来要经过一次softmax计算,再与矩阵V相乘。因为V是该词的特征含义,至少要把各自的v放进去才有实际含义。
即softmax( /根号下维度 ) ·
/根号下维度 ) ·  得到结果
得到结果 

上面Q·K完成了各词之间的”评分“,用softmax归一化一下,得到的都是0.几的影响度(放在以前就是概率了),乘以V,得到结果Z。
至于除以根号下维度则是因为随着矩阵维度增加结果也会变大。这步叫Scaled Dot-Product Attention


这样同一词上下文不同注意力也会不同,表达的意思也会不同。
同时矩阵的运算也是并行的,不同词之间直接计算,无论是X·W还是Q·K又或是后面的计算。
3.4 multi-headed机制
多头注意力,也有叫多重注意力,即很多组不同的注意力。
我们上面最开始说到X和相乘得到Q、K、V矩阵,实际上这个可以有多组,得到多组不同的Q、K、V矩阵,以得到很组不同的结果,这便是多头注意力机制。就像特征图一样。

我们得到了不同的结果Z0 Z1 Z2 Z3... 一般有8个

将它们拼接在一起concat,进行一次全连接来降维得到最后的输出结果Z

不同的头结果往往是不同的:

3.5 局部模型观察1
下面便是Transformer模型的结构,左侧是编码器encoder和解码器decoder。

此时我们已经了解了muti-head attention

多组Q、K、V输入,softmax(/根号下维度 ) · 得到多个结果,拼在一起(Concat)进行一次全连接(Linear)降维 。
其中Scaled Dot-Product Attention是softmax那里进行的操作,字母h表示头的数量。
3.6 堆叠多层
一层不够用,那就加!

上图是向量输入 输出向量形式画的,我们依旧按矩阵来想,那就还和前面一样,多头注意力(上图是单个)我们得到多个z拼在一起全连接降维得到Z,接下来要经过Feed Forward Neural Network,得到矩阵R,这里的R就像一开始的X一样,当作输入去输入下一层的muti-head层里和去运算。计算方法都是相同的。
即刚刚那样的事要再经历一次!

3.7 位置信息表达
在self-attention中每个词都会考虑整个序列的加权,所以其出现位置(先后顺序)并不会对结果产生什么影响,但是这跟实际就有些不符合了,我们希望模型能对位置有额外的认识。
此时,就有了位置编码 Positional Embedding

embedding后得到的X与位置矩阵T相加得到新的Positional Embedding的X。当然实际操作比这麻烦点,加入如正弦余弦函数这样的时钟周期函数,详情自行查阅。
3.8 Add与Normalize
层归一化和残差连接
层归一化

之前我们为例让数据、训练"可控"、别太跑偏,使用的是Batch Normalize,而这里使用的是Layer Normalize,区别如上图,即前者对于每个Batch,后者是对于每个数据。
残差连接

这是个老知识了,即这样不会使得训练效果变差,因为每次都加上了之前的x。
3.9 局部模型观察-Encoder
至此Encoder所需要的就都介绍完啦

两个子层
多头注意力层
2层的前馈网络
两个小技巧
残差链接
层归一化:将输入归一化为均值为0,方差为1
完整的编码器
每一层单元使用前一层的输出作为Q, K, V的输入
根据实验结果,组成单元的层数被设定为6
3.10 Decoder中的Masked Muti-Head Attention
与Encoder不同,Decoder中加入了Mask机制,不过Decoder也是输入一个序列输出一个序列。

前面介绍了Encoder中矩阵运算,而Decoder中的答案则是一个接着一个出的,以机器翻译为例,翻译出I am a student,除了要看前一种语言的序列以外,翻译到am时要考虑I,翻译到a的时候要考虑 I am...
因此,在不断地输入的时候,并不能像Encoder一样X直接放进去,而是需要加入Mask机制,即翻译到a的时候要考虑 I am,而student此时还没有翻译出来,要用掩码给它掩盖掉。这样Embedding、Embedding with time signal时都看不到,输入进去的时候也”不知道“了。

Masked Muti-Head Attention它最终只输出一个Q,与Encoder中的K, V放在一起作为输入传递给Decoder中的Muti-Head Attention进行预测,得到最终最终的结果。

损失函数使用cross-entropy即可
3.11 整体网络架构梳理和其它技巧
架构:编码器-解码器
输入:字节对编码 + 位置编码
模型:多层编码/解码模型单元的堆叠
输出:下个单词的概率
损失函数:在softmax层之后使用标准的交叉熵损失函数
架构:编码器-解码器

输入:输入=字节对编码 + 位置编码

模型:多层编码/解码模型单元的堆叠

其中,Masked Muti-Head Attention它最终只输出一个Q,与Encoder中的K, V放在一起作为输入传递给Decoder中的Muti-Head Attention进行预测。
输出:下个单词的概率
损失函数:在softmax层之后使用标准的交叉熵损失函数

其他技巧
检查点平均
ADAM优化器
在训练时,加上每一层的残差前使用dropout
标签平滑
带有束搜索和长度惩罚的自回归解码
3.12 补充:字节编码和位置编码
Input = BPE + PE 字节对编码+位置编码
字节对编码(Byte Pair Encoding, BPE)
不是对词进行编码,而是将词分割成更小的单元进行编码。
一种单词分割算法
从所有字母组成的单词表开始
将频率最高的n-gram变成新的词表单词


字节对编码 (Byte Pair Encoding, BPE)
将出现次数少和未见过的单词编码成子词单元 (subword units) 的序列,解决未登录词 (out of vocabulary, OOV) 的问题
在上面的例子中,未登录词 “best” 将会被切割成 “b est”。这样便将之前未见过的单词转化为相应的子词单元
位置编码 (Positional encoding, PE)
设字节对编码维度为d,接下来在字节编码中加入位置编码
Transformer的组成单元对于在不同位置的的相同单词不敏感
加入位置编码后,在不同位置的相同单词会有不同表示


𝑖 是embedding的索引, 取值范围是 0 到 d/2
Input = BPE + PE
位置编码可视化

上图可见每一行相当于一个position即第几个位置,每一列相当于embedding的维度。这是偶数位和奇数位的位置编码。
一个位置编码的例子,上图包含了20个单词(每一行)和512维向量长度(每一列)。可以发现图中PE的。

取值好像从中间分开了。这是因为这个图中的左边的值是由sin函数生成的,右边的值是由cos生成 的,这两个函数生成的值之后被拼接起来形成了最终的位置编码。
四、总结
机器翻译结果:

Transformer是一个高效的模型,在NLP的很多任务中非常有效
证明了注意力机制的有效性
为最新NLP的前沿进展 (如BERT和XLNet) 提供了启示文章来源:https://www.toymoban.com/news/detail-802312.html
然而,Transformer框架不容易优化,对于参数修改比较敏感文章来源地址https://www.toymoban.com/news/detail-802312.html
到了这里,关于占有统治地位的Transformer究竟是什么的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!