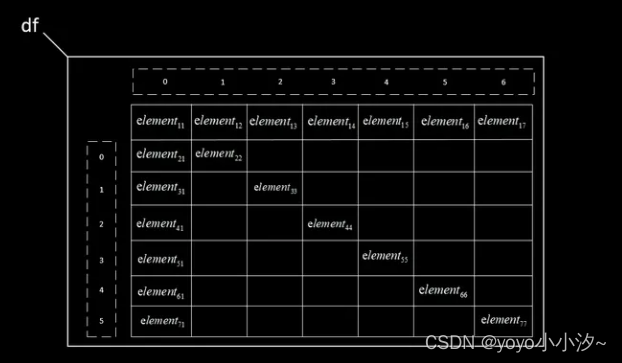
大家好,Pandas是一个功能强大的数据分析库,它提供了许多灵活且高效的方法来处理和分析数据。本文将介绍如何使用Pandas读取HTML数据和JSON数据,并展示一些常见的应用场景。
一、读取HTML网页
HTML(超文本标记语言)是一种用于创建网页的标准标记语言。网页通常由HTML标签和内容组成,这些标签描述了网页的结构和样式。在网页上,数据可以以表格、列表或其他形式展示。Pandas可以读取这些HTML数据,并将其转换为数据框,方便我们进行进一步的分析和处理。
1.读取HTML数据
Pandas提供了一个函数read_html(),可以直接从HTML文件或URL中读取数据。下面是读取HTML数据的基本语法:
import pandas as pd
data = pd.read_html('file.html') # 从HTML文件读取数据
data = pd.read_html('http://example.com/table.html') # 从URL读取数据这个函数会返回一个包含所有HTML表格的列表。每个表格都被转换为一个数据框,可以像处理其他数据框一样进行操作。
2.处理HTML数据
一旦我们将HTML数据读取到Pandas中,我们就可以使用各种方法处理和分析数据,下面是一些常见的操作。
- 查看数据
使用head()方法可以查看数据的前几行,默认显示前5行。
print(data[0].head()) # 查看第一个表格的前5行- 数据清洗
HTML数据通常包含一些不需要的行或列,可以使用Pandas的数据清洗方法来删除这些数据。
clean_data = data[0].dropna() # 删除含有NaN值的行
clean_data = clean_data.drop(columns=['Unnamed: 0']) # 删除指定列- 数据转换
有时,HTML数据中的某些列可能被错误地识别为字符串,可以使用Pandas的数据转换方法将其转换为正确的数据类型。
clean_data['Price'] = clean_data['Price'].str.replace('$', '').astype(float) # 将价格列转换为浮点数- 数据分析
一旦数据清洗和转换完成,就可以使用Pandas提供的各种方法进行数据分析,比如计算平均值、中位数、标准差等统计指标。
mean_price = clean_data['Price'].mean() # 计算价格的平均值
median_price = clean_data['Price'].median() # 计算价格的中位数
std_price = clean_data['Price'].std() # 计算价格的标准差3.实际应用
下面将通过一个实际的例子来演示如何使用Pandas读取和处理HTML数据。假设要分析一个网站上的证券数据,网站上的数据以HTML表格的形式展示,可以使用Pandas读取这些数据,并进行进一步的分析。
首先,需要安装Pandas库。可以使用以下命令来安装:
pip install pandas
然后,可以使用以下代码来读取HTML数据:
import pandas as pd
data = pd.read_html('http://example.com/stock.html')
接下来可以查看数据的前几行,并进行数据清洗和转换:
clean_data = data[0].dropna()
clean_data['Price'] = clean_data['Price'].str.replace('$', '').astype(float)
最后进行数据分析,并输出结果:
mean_price = clean_data['Price'].mean()
median_price = clean_data['Price'].median()
std_price = clean_data['Price'].std()
print('平均价格:', mean_price)
print('中位数价格:', median_price)
print('价格标准差:', std_price)
通过这些步骤,可以轻松地读取和分析HTML数据,从而得到有关证券价格的统计指标。
二、读取JSON文件
JSON是一种常用的数据交换格式,Pandas提供了一个函数read_json(),可以直接从JSON文件或URL中读取数据。下面是读取JSON数据的基本语法:
import pandas as pd
data = pd.read_json('file.json') # 从JSON文件读取数据
data = pd.read_json('http://example.com/data.json') # 从URL读取数据1.处理JSON数据
一旦将JSON数据读取到Pandas中,就可以使用各种方法处理和分析数据,下面是一些常见的操作。
- 查看数据
使用head()方法可以查看数据的前几行,默认显示前5行。
print(data.head()) # 查看数据的前5行
- 数据清洗
在处理JSON数据时,可能会遇到一些缺失值或异常值。Pandas提供了一些方法来处理这些情况。
清除缺失值:使用dropna()方法可以删除包含缺失值的行或列。
data.dropna() # 删除包含缺失值的行
data.dropna(axis=1) # 删除包含缺失值的列
填充缺失值:使用fillna()方法可以将缺失值替换为指定的值。
data.fillna(0) # 将缺失值替换为0
- 数据转换
Pandas提供了一些方法来转换数据类型,以及对数据进行重塑和透视。
转换数据类型:使用astype()方法可以将一列数据转换为指定的数据类型。
data['column_name'].astype(int) # 将一列数据转换为整数类型
重塑数据:使用pivot()方法可以将数据从长格式转换为宽格式。
data.pivot(index='column1', columns='column2', values='value') # 将数据从长格式转换为宽格式
- 数据分析
Pandas提供了丰富的方法来进行数据分析,包括数据聚合、数据排序、数据统计等。
数据聚合:使用groupby()方法可以对数据进行分组,并进行聚合操作。
data.groupby('column').sum() # 按列进行分组,并计算每组的总和
数据排序:使用sort_values()方法可以按指定的列对数据进行排序。
data.sort_values('column') # 按列对数据进行排序
数据统计:使用describe()方法可以计算数据的统计指标,如平均值、中位数、标准差等。
data.describe() # 计算数据的统计指标2.输出数据
在处理和分析数据之后,可以将结果保存为其他格式的文件,如CSV、Excel等。
-
保存为CSV文件:使用to_csv()方法可以将数据保存为CSV文件。
data.to_csv('output.csv') # 将数据保存为CSV文件
-
保存为Excel文件:使用to_excel()方法可以将数据保存为Excel文件。文章来源:https://www.toymoban.com/news/detail-802323.html
data.to_excel('output.xlsx') # 将数据保存为Excel文件综上所述,本文介绍了如何使用Pandas读取和处理HTML、JSON数据。通过Pandas的函数,可以轻松地从JSON文件或HTML中读取数据,并将其转换为DataFrame,进而使用Pandas提供的各种方法进行数据清洗、转换和分析。 文章来源地址https://www.toymoban.com/news/detail-802323.html
到了这里,关于使用pandas读取HTML和JSON数据的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!