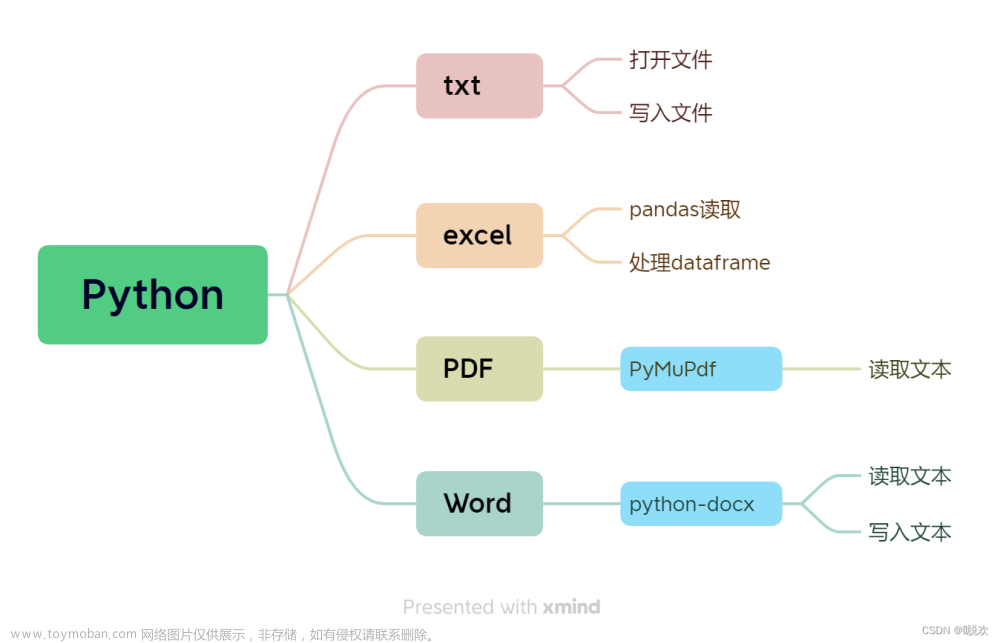
import os
import fitz
import shutil
import os,time
import fitz
from tkinter import filedialog
import tkinter as tk
from docx import Document
from docxcompose.composer import Composer
import win32com.client as win32
def covert2pic(file_path, zoom, png_path): #此函数用于把pdf文件导出成图片,并保存到对应文件夹下
doc = fitz.open(file_path)
total = doc.page_count
for pg in range(total):
page = doc[pg]
zoom = int(zoom) # 值越大,分辨率越高,文件越清晰
rotate = int(0)
trans = fitz.Matrix(zoom / 100.0, zoom / 100.0).prerotate(rotate)
pm = page.get_pixmap(matrix=trans, alpha=False)
if not os.path.exists(png_path):
os.mkdir(png_path)
save = os.path.join(png_path, '%s.png' %(pg+1))
pm.save(save)
doc.close()
def PCLPDFWJ(Pdf_file_path):
if Pdf_file_path=='':
print("你输入空目录")
else:
desktop_path = os.path.expanduser("~\Desktop") # 获取当前桌面路径
# ----读取文件夹下所有文件的名字并把他们用列表存起来------
datanames = os.listdir(Pdf_file_path)
list_Pdfname = []
for i in datanames:
# 获取文件名称中日期
list_Pdfname.append(i)
# -----------------------------------------------
for j in list_Pdfname:
s = j # 获取文件夹中PDF名称
pdfPath = Pdf_file_path + "\\" + s
print(pdfPath)
j = j[:-4] # 去掉最后4个字符.pdf
imagePath = desktop_path + "\\" + "临时文件夹" + "\\" + j
# 批量创建imagePath文件夹----------------------------------------------------
if not os.path.exists(imagePath):
os.makedirs(imagePath)
else:
# 清理历史遗留处理过的文件夹内容
shutil.rmtree(imagePath)
os.makedirs(imagePath)
covert2pic(pdfPath, 200, imagePath)
folder_path = imagePath #获取图片数量
file_count = len([f for f in os.listdir(folder_path) if os.path.isfile(os.path.join(folder_path, f))]) #获取图片数量
#print(file_count)
# 创建新的Word文档对象
document = Document()
# 获取指定文件夹路径
folder_path = imagePath
ysnb=1 #页数从第一页开始插入
# 遍历文件夹中的每张图片并插入到Word文档中
#for filename in os.listdir(folder_path):
while ysnb<=int(file_count):
filename=str(ysnb)+"."+"png" #获取转化后的临时文件夹中对应图片文件夹中的图片名称
image_path = os.path.join(folder_path, filename)
# 在当前光标位置插入图片
document.add_picture(image_path)
ysnb=ysnb+1
document.save(desktop_path + "\\" + "wordoutput" + "\\" + j + ".docx")
# 保存Word文档
# print(hb)
def qinglilingshiwenj(): #清理之前生成的临时文件夹,避免出错
desktop_path = os.path.expanduser("~\Desktop") #获取当前桌面路径
print("当前桌面路径:", desktop_path)
# 在当前操作系统桌面上创建wordoutput文件夹------------------------------------
if not os.path.exists(desktop_path + "\\" + "wordoutput"):
os.makedirs(desktop_path + "\\" + "wordoutput")
else:
# 清理历史遗留处理过的文件夹内容
shutil.rmtree(desktop_path + "\\" + "wordoutput")
os.makedirs(desktop_path + "\\" + "wordoutput")
# ---------把图片插入word文件中---------------------------
# 在当前操作系统桌面上创建wordoutput文件夹-----------------------------------------
if not os.path.exists(desktop_path + "\\" + "临时文件夹"):
os.makedirs(desktop_path + "\\" + "临时文件夹")
else:
# 清理历史遗留处理过的文件夹内容
shutil.rmtree(desktop_path + "\\" + "临时文件夹")
os.makedirs(desktop_path + "\\" + "临时文件夹")
#--------------------------------------------------------------------------------
#----------此函数用于合并wordoutput文件夹中所有word成为一个word文件,合并文件输出在桌面------
def hebing_word():
# 获取要处理的文件夹路径
folder_path = r"C:\Users\Thinkpad\Desktop\wordoutput"
datanames = os.listdir(folder_path)
list_wordoutname = []
for i in datanames:
# 获取文件名称中日期
list_wordoutname.append(folder_path + "\\" + i)
print(list_wordoutname)
# 以下函数用于合并指定文件夹中所有word文件
# 创建新的空白Word文档
merged_doc = Document()
def HB_wordwj(files, final_docx):
new_document = Document()
composer = Composer(new_document)
for fn in files:
composer.append(Document(fn))
composer.save(final_docx)
# 保存合并后的文档
desktop_path = os.path.expanduser("~\Desktop") # 获取当前桌面路径
merged_file_name = desktop_path + "\\" + "合并输出文件.docx"
print(merged_file_name)
HB_wordwj(list_wordoutname, merged_file_name)
print("已将文件夹中的所有Word文件合并为", merged_file_name)
# ------以下程序用于执行word中宏程序,用于调整合并插入的图片大小---------------------
# 创建 Word 应用程序对象
word = win32.gencache.EnsureDispatch('Word.Application')
# 打开文件
doc = word.Documents.Open(merged_file_name)
try:
# 运行宏
doc.Application.Run("setpicsize")
finally:
# 关闭文件并退出 Word 应用程序
doc.Close()
word.Quit()
#----------此函数用于合并wordoutput文件夹中所有word成为一个word文件,合并文件输出在桌面------
if __name__ == "__main__":
root = tk.Tk()
root.withdraw() # 隐藏tkinter的根窗口
folder_path = filedialog.askdirectory()
# 将路径从Unix格式转换为Windows格式
windows_path = folder_path.replace("/", "\\")
print("转换后的路径:", windows_path)
pdfPath = windows_path
qinglilingshiwenj() #清理之前生成的临时文件夹,避免出错
PCLPDFWJ(pdfPath)
hebing_word()
文章来源地址https://www.toymoban.com/news/detail-802453.html
文章来源:https://www.toymoban.com/news/detail-802453.html
到了这里,关于改进python批量处理pdf文件插入word页码乱问题的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!