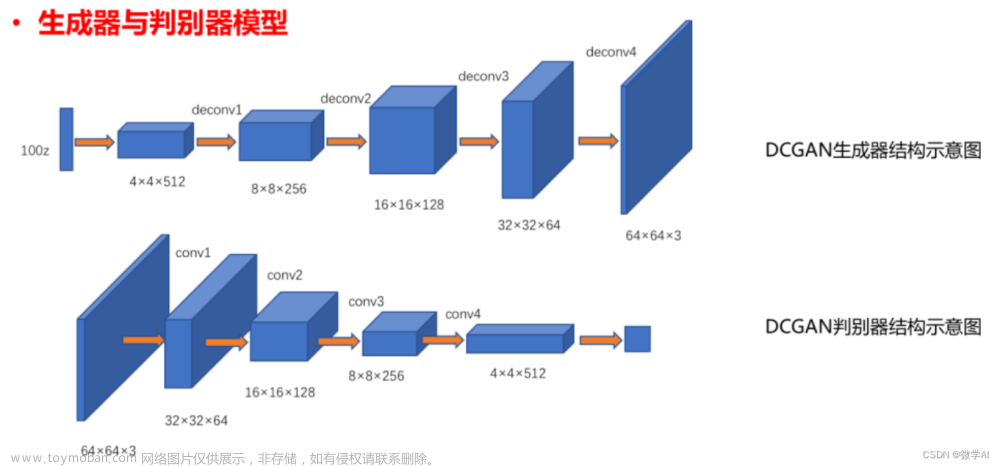
Building the model layers 生成模型层
What is a neural network 什么是神经网络
神经网络是按层连接的神经元的集合。每个神经元都是一个小的计算单元,执行简单的计算来共同解决问题。神经元分为 3 种类型的层:输入层、隐藏层和输出层。隐藏层和输出层包含许多神经元。神经网络模仿人脑处理信息的方式。
Components of a neural network 神经网络的组成部分
-
activation function 激活函数 决定神经元是否应该被激活。神经网络中发生的计算包括应用激活函数。如果神经元激活,则意味着输入很重要。有不同种类的激活函数。选择使用哪个激活函数取决于您想要的输出。激活函数的另一个重要作用是为模型添加非线性。
- Binary 如果函数结果为正,则用于将输出节点设置为 1;如果函数结果为零或负,则将输出节点设置为 0。 f ( x ) = { 0 , if x < 0 1 , if x ≥ 0 f(x)= {\small \begin{cases} 0, & \text{if } x < 0\\ 1, & \text{if } x\geq 0\\ \end{cases}} f(x)={0,1,if x<0if x≥0
- Sigmoid 用于预测输出节点介于 0 和 1 之间的概率。$f(x) = {\large \frac{1}{1+e^{-x}}} $
- Tanh 用于预测输出节点是否在 1 到 -1 之间,用于分类用例。$f(x) = {\large \frac{e^{x} - e{-x}}{e{x} + e^{-x}}} $
- ReLU (rectified linear activation function) 如果函数结果为负,则用于将输出节点设置为 0;如果结果为正,则保持结果值。 f ( x ) = { 0 , if x < 0 x , if x ≥ 0 f(x)= {\small \begin{cases} 0, & \text{if } x < 0\\ x, & \text{if } x\geq 0\\ \end{cases}} f(x)={0,x,if x<0if x≥0
-
Weights 权重 影响我们网络的输出与预期输出值的接近程度。当输入进入神经元时,它会乘以权重值,所得输出要么被观察,要么被传递到神经网络中的下一层。一层中所有神经元的权重被组织成一个张量。
-
Bias 偏差 弥补了激活函数的输出与其预期输出之间的差异。低偏差值表明网络对输出形式做出更多假设,而高偏差值对输出形式做出更少假设。
我们可以说,具有weights W W W 和bias b b b 的神经网络层的输出 y y y 的计算为,输入乘以 weights加上bias的总和。 $x = \sum{(weights * inputs) + bias} $,其中 f ( x ) f(x) f(x) 是激活函数。
Build a neural network 构建神经网络
神经网络由对数据执行操作的层/模块组成。torch.nn命名空间提供了构建您自己的神经网络所需的所有构建块。在PyTorch 中,每个模块都是nn.Module 的子类。神经网络本身就是一个模块,由其他模块(层)组成。这种嵌套结构允许轻松构建和管理复杂的架构。
在以下部分中,我们将构建一个神经网络,来对 FashionMNIST 数据集中的图像进行分类。
%matplotlib inline
import os
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
Get a hardware device for training 获取用于训练的硬件设备
我们希望能够在 GPU 等硬件加速器(如果可用)上训练我们的模型。让我们检查一下torch.cuda ,否则我们使用 CPU。
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print('Using {} device'.format(device))
Out:
Using cuda device
Define the Class 定义类
我们通过子类化nn.Module来定义我们的神经网络。在__init__中,初始化神经网络层。每个nn.Module子类都在forward方法中实现对输入数据的操作。
我们的神经网络由以下部分组成:
- 输入层具有 28x28 或 784 个特征/像素。
- 第一个线性模块采用输入 784 个特征,并将其转换为具有 512 个特征的隐藏层。
- ReLU 激活函数将应用于转换中。
- 第二个线性模块将第一个隐藏层的 512 个特征作为输入,并将其转换到具有 512 个特征的下一个隐藏层。
- ReLU 激活函数将应用于转换中。
- 第三个线性模块将 512 个特征作为来自第二个隐藏层的输入,并将这些特征转换到输出层,其中 10 是类的数量。
- ReLU 激活函数将应用于转换中。
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10),
nn.ReLU()
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
我们创建NeuralNetwork 的一个实例,并将其移动到device,并打印其结构。
model = NeuralNetwork().to(device)
print(model)
Out:
NeuralNetwork(
(flatten): Flatten(start_dim=1, end_dim=-1)
(linear_relu_stack): Sequential(
(0): Linear(in_features=784, out_features=512, bias=True)
(1): ReLU()
(2): Linear(in_features=512, out_features=512, bias=True)
(3): ReLU()
(4): Linear(in_features=512, out_features=10, bias=True)
(5): ReLU()
)
)
为了使用该model,我们将输入数据传递给它。这将执行model的forward以及一些background operations。不要直接调用model.forward()!在输入上调用model会返回一个二维张量,其中 dim=0 对应于每个类的 10 个原始predicted values的每个输出,dim=1 对应于每个输出的各个值。
我们通过,将它传递给nn.Softmax模块的实例,来获得prediction probabilities。
X = torch.rand(1, 28, 28, device=device)
logits = model(X)
pred_probab = nn.Softmax(dim=1)(logits)
y_pred = pred_probab.argmax(1)
print(f"Predicted class: {y_pred}")
Out:
Predicted class: tensor([7], device='cuda:0')
Weight and Bias 权重和偏差
nn.Linear 模块随机初始化每层的权重和偏差,并在内部将值存储在张量中。
print(f"First Linear weights: {model.linear_relu_stack[0].weight} \n")
print(f"First Linear biases: {model.linear_relu_stack[0].bias} \n")
Out:
First Linear weights: Parameter containing:
tensor([[ 8.9385e-03, -2.4055e-02, 1.9085e-03, ..., -1.8426e-05,
-9.0800e-04, 1.9594e-02],
[-7.0768e-03, 2.6314e-02, 2.8988e-02, ..., 2.2543e-02,
9.9050e-03, -4.3447e-03],
[-2.5320e-02, -3.2440e-02, -3.0216e-02, ..., -3.1892e-02,
-2.0309e-03, -2.5925e-02],
...,
[-6.6404e-03, -1.9659e-03, -3.3045e-02, ..., -5.3951e-03,
-1.1355e-02, 1.0398e-04],
[ 1.3734e-02, 3.3571e-02, 3.4846e-02, ..., 3.1258e-02,
-9.9484e-03, -1.1788e-02],
[-1.3908e-02, 1.1488e-02, -6.8923e-03, ..., -9.5730e-03,
-6.6496e-03, -4.7810e-03]], requires_grad=True)
First Linear biases: Parameter containing:
tensor([ 5.9986e-03, 1.9926e-02, -9.0487e-03, 9.3418e-03, 3.1350e-02,
-3.1133e-02, -1.9971e-02, 9.2257e-03, 2.4641e-02, -3.9794e-03,
-1.9599e-02, 1.5554e-02, -1.1251e-02, 2.0161e-02, 1.9584e-02,
-2.3056e-02, 6.4135e-03, -1.2719e-02, 2.8192e-02, -1.1354e-02,
-2.5184e-02, 1.4313e-02, 1.9746e-02, -2.6794e-02, 4.5221e-03,
-1.9318e-02, 2.5716e-02, 2.3134e-03, -3.2787e-02, 2.5133e-02,
1.3309e-02, -2.2916e-02, -2.9163e-02, 2.0085e-02, -1.9987e-02,
-1.6186e-02, 2.7146e-02, 3.8904e-03, 3.3362e-02, 1.6783e-02,
-3.2172e-02, -2.0039e-02, 1.5975e-02, -1.7357e-02, -6.5472e-03,
-1.0733e-03, -6.6345e-03, 2.6318e-02, -1.3912e-02, 2.8931e-02,
-8.0001e-03, 2.2949e-02, 3.3579e-02, -1.4285e-02, -3.5026e-02,
-4.6408e-03, -3.2110e-02, 7.9603e-03, 1.6381e-02, -3.5188e-02,
2.5518e-02, 2.2947e-02, 2.8763e-02, 2.4568e-02, 3.1417e-02,
-4.2958e-03, 5.4503e-03, -2.6941e-02, -3.1337e-02, 6.5361e-03,
1.5351e-02, 2.4380e-02, 3.4527e-02, 1.9956e-02, -1.6002e-02,
-2.1571e-02, -3.1452e-02, -2.6187e-02, 2.8742e-02, 8.8401e-04,
2.7811e-02, -2.1074e-03, -5.2441e-03, 1.9205e-02, -2.1756e-02,
-2.8340e-02, -2.4008e-02, -3.2218e-02, 2.7938e-02, -1.8855e-02,
2.6310e-02, 8.5549e-03, 3.2544e-02, -8.7869e-03, -5.4650e-03,
-8.5808e-04, -1.9684e-02, -9.2285e-04, 2.6570e-02, 2.7112e-02,
1.0834e-02, 2.9951e-02, -2.8885e-02, -8.7398e-03, -3.2123e-02,
-3.4103e-02, -1.7104e-02, -3.5013e-02, 2.6816e-02, 1.3221e-02,
4.7024e-03, -1.1069e-02, 1.1744e-02, 1.1716e-02, 2.2116e-02,
-3.7134e-03, -3.1935e-02, -2.8137e-02, -4.2648e-03, 7.3065e-03,
2.7714e-03, -2.0125e-02, -7.4680e-03, -5.7435e-03, -2.3287e-02,
-1.8487e-02, -2.0353e-02, 3.4419e-02, 1.6447e-02, -2.6372e-02,
3.0840e-02, 2.7868e-02, -2.5893e-02, -1.6408e-02, -3.5142e-02,
2.4987e-02, -1.2068e-03, -3.3286e-02, 1.3896e-02, 1.4766e-02,
2.7921e-02, -1.9777e-02, 1.6009e-03, -3.0369e-03, 5.8204e-03,
1.3330e-02, -1.6057e-03, 3.3774e-02, 8.0411e-03, -1.3426e-02,
-3.0065e-02, -3.3407e-02, -1.1686e-02, -1.1754e-03, -3.1514e-02,
1.0637e-02, 3.4243e-02, 2.6827e-02, 1.9017e-02, 3.2513e-02,
1.4470e-02, -2.0612e-02, -3.4506e-02, -1.3239e-02, -1.1074e-02,
-2.1190e-02, 2.0960e-02, 1.1182e-02, -2.2666e-02, 6.2611e-03,
-2.8990e-02, 1.9382e-02, 2.3962e-03, -2.0972e-03, -8.4757e-03,
-9.1190e-03, -1.4236e-02, -2.2083e-03, -2.3094e-02, -2.9572e-03,
-2.9041e-03, 2.0682e-02, -1.7084e-03, -3.3577e-02, 8.6727e-03,
-9.0417e-03, -1.5183e-02, 1.6578e-02, 2.5495e-02, -9.8740e-03,
3.2653e-03, -2.2072e-02, 1.0324e-02, 1.1515e-02, 2.2550e-02,
-2.9260e-02, 7.6638e-03, 1.9953e-02, 2.0006e-02, -2.0214e-02,
8.8572e-03, 1.0404e-02, 2.4252e-02, -3.2847e-02, -1.3980e-02,
2.4789e-02, -5.2448e-03, 5.9182e-03, -2.0305e-02, 2.7687e-02,
-2.7491e-02, 3.4065e-02, -1.5964e-02, -5.7720e-03, -2.2380e-02,
-2.6087e-02, 1.7129e-04, 2.5295e-03, -3.2620e-02, -8.9806e-03,
-1.7327e-02, -3.1212e-03, -1.8227e-02, 2.5046e-02, 3.3874e-02,
-3.4658e-02, -3.3325e-02, 1.5169e-02, 2.9721e-02, -2.1360e-02,
1.9001e-02, -3.4234e-02, -2.0162e-03, -3.3659e-02, -1.5272e-02,
-3.6956e-03, -8.6415e-03, -2.1750e-02, -3.3776e-02, 3.4642e-02,
1.6748e-04, -9.6430e-03, 3.1374e-02, 2.2172e-02, -2.1042e-02,
2.7340e-02, 6.1807e-03, 1.2675e-03, -1.6533e-02, -1.1356e-03,
2.8314e-02, 7.1925e-03, -2.1810e-02, -4.2207e-03, 5.8930e-03,
-3.1270e-02, -2.1335e-02, -1.2622e-02, -2.5292e-02, -2.4345e-03,
3.3701e-02, -5.3965e-03, 1.0012e-02, -8.9052e-04, -2.1508e-02,
3.4990e-02, -3.1931e-02, 2.1711e-02, 1.7907e-02, 1.1928e-02,
-2.4449e-02, 1.3951e-02, -1.2408e-02, -9.4584e-03, 1.6864e-02,
-2.8035e-02, 2.9146e-02, -3.4494e-02, -3.4326e-02, 6.5326e-03,
3.3425e-02, -2.1809e-02, -2.9216e-02, -6.3335e-03, 1.5225e-03,
-2.3894e-02, -1.1101e-02, 9.0631e-03, 2.9225e-02, 5.1517e-03,
-1.8896e-02, 2.1768e-02, -3.5104e-02, -2.2003e-02, 8.9227e-03,
2.4530e-02, 4.0939e-03, 4.1382e-03, 5.8822e-03, -1.1990e-02,
1.1077e-02, -9.5397e-03, -3.5084e-02, -2.9436e-02, -1.1752e-02,
-1.3748e-02, 3.5164e-02, -1.6435e-02, -3.4502e-02, 3.3773e-03,
-2.9251e-02, -2.1990e-02, 4.2471e-03, -2.3697e-02, 9.6990e-05,
-3.2504e-02, -7.1421e-03, 1.7027e-02, 3.3400e-02, 6.4107e-03,
1.1713e-03, 2.4070e-02, -1.2695e-02, -8.9952e-04, 2.4428e-02,
-2.7448e-02, -3.6027e-03, 1.6652e-02, -1.2338e-03, 1.0408e-02,
4.3328e-03, 1.8153e-02, 3.1082e-02, 2.7676e-02, 5.3654e-03,
6.1815e-03, -2.0798e-02, -2.4612e-02, -3.3156e-02, 2.5055e-02,
2.5179e-02, -1.5044e-02, -2.1547e-02, -2.2172e-02, 2.7281e-02,
2.0324e-02, 2.7768e-02, -3.5495e-02, -1.7735e-02, -1.8990e-02,
-7.6506e-03, 2.4374e-02, -2.6513e-02, -2.2248e-02, 4.7401e-03,
1.5162e-02, 1.1040e-02, -2.7058e-02, -9.3053e-03, -1.1417e-03,
1.9759e-02, 8.8142e-03, -1.1458e-02, -3.0437e-02, 2.6083e-03,
2.3219e-02, -1.3296e-02, 2.3401e-02, 2.9435e-02, -2.4347e-02,
-2.8407e-02, 3.2922e-03, -9.7309e-03, -3.1861e-03, 1.5294e-02,
-3.1260e-02, 1.6128e-02, -2.6976e-02, -2.3860e-02, -2.8258e-02,
3.3300e-02, 2.1957e-02, 1.8276e-02, 3.3821e-02, 3.2459e-02,
-1.4380e-02, 2.8679e-02, -1.8167e-02, 1.4250e-02, -2.6868e-02,
4.6922e-03, 3.0262e-02, 3.3328e-02, 1.7418e-03, -1.3915e-03,
2.1020e-02, -3.2912e-04, 2.7675e-02, 2.8924e-02, 2.6323e-02,
1.4407e-03, 1.7175e-02, -1.7259e-02, -2.4208e-02, 2.5289e-02,
3.4845e-02, 8.8181e-03, 1.3848e-02, 2.3637e-02, 2.6063e-02,
1.7485e-02, -5.0237e-03, 1.5242e-02, -5.2527e-03, 2.8615e-02,
-6.4647e-03, 2.7292e-02, 1.2469e-02, 1.4604e-02, 2.3259e-02,
-1.3001e-02, -1.4321e-02, -7.7171e-03, 9.9475e-03, 1.7257e-03,
-1.4338e-02, 2.7782e-03, -1.9520e-02, -1.1003e-03, -3.5199e-02,
5.0515e-03, 6.2458e-03, 3.1785e-02, 2.2085e-02, -1.8765e-02,
-1.9637e-02, 5.6673e-03, 3.9483e-03, 6.8746e-03, -9.1332e-03,
3.7987e-03, -1.3767e-02, -1.0537e-02, 2.8263e-02, 3.3773e-02,
3.3666e-02, -9.3893e-03, -1.2266e-03, 3.4049e-02, 2.3165e-03,
-3.1737e-02, -3.4418e-02, -5.2358e-03, -1.8076e-02, -1.0501e-02,
7.2267e-03, -2.5573e-02, 1.2106e-02, 2.1317e-02, 1.4924e-02,
7.0579e-03, -1.9364e-02, -6.4564e-03, -2.1039e-02, -1.1712e-02,
-1.3358e-02, 2.7151e-02, -1.2927e-03, -5.1539e-03, -2.5093e-02,
-1.7757e-02, -2.6099e-02, 1.2471e-02, 1.8767e-02, -1.4756e-02,
-2.7813e-02, -1.0629e-02, 2.9636e-02, 7.8347e-03, -4.1875e-03,
-5.7266e-03, -2.7923e-02, -2.1416e-02, 3.4688e-02, -1.2472e-02,
1.8679e-02, 2.6543e-02, 1.3168e-02, 2.9893e-02, 1.3526e-02,
-1.8278e-02, -8.5952e-03, -1.6681e-02, -2.1498e-03, 3.2721e-02,
-1.2839e-02, -3.3540e-02, -1.6349e-02, -3.5600e-02, -1.3388e-02,
-1.4139e-02, -1.4343e-02, -1.3964e-02, -2.3136e-02, 3.4252e-02,
1.4078e-02, 2.8221e-02, 8.8933e-03, -2.3626e-02, 1.8151e-03,
2.0952e-02, 2.1661e-02], requires_grad=True)
Model Layers 模型层
让我们分解 FashionMNIST model中的layers。为了说明这一点,我们将采用 3 张大小为 28x28 的图像的小批量样本,看看当我们将其传递到网络时会发生什么。
input_image = torch.rand(3,28,28)
print(input_image.size())
Out:
torch.Size([3, 28, 28])
nn.Flatten
我们初始化nn.Flatten layer,将每个 2D 28x28 图像转换为 784 个像素值的连续数组,维持小批量维度(在 dim=0 时)。
flatten = nn.Flatten()
flat_image = flatten(input_image)
print(flat_image.size())
Out:
torch.Size([3, 784])
nn.Linear
linear layer是一个使用其存储的权重和偏差对输入应用线性变换的模块。输入层中每个像素的灰度值将连接到隐藏层中的神经元进行计算。用于转换的计算是 ${{weight * input + bias}} $。
layer1 = nn.Linear(in_features=28*28, out_features=20)
hidden1 = layer1(flat_image)
print(hidden1.size())
Out:
torch.Size([3, 20])
nn.ReLU
非线性激活是在模型的输入和输出之间创建复杂映射的原因。它们在线性变换后应用以引入非线性,帮助神经网络学习各种现象。
在此模型中,我们在线性层之间使用nn.ReLU,但还有其他激活可以在模型中引入非线性。
ReLU 激活函数获取线性层计算的输出,并将负值替换为零。
Linear output: ${ x = {weight * input + bias}} $。
ReLU:
$
f(x)=
\begin{cases}
0, & \text{if } x < 0\
x, & \text{if } x\geq 0\
\end{cases}
$
print(f"Before ReLU: {hidden1}\n\n")
hidden1 = nn.ReLU()(hidden1)
print(f"After ReLU: {hidden1}")
Out:
Before ReLU: tensor([[ 0.4158, -0.0130, -0.1144, 0.3960, 0.1476, -0.0690, -0.0269, 0.2690,
0.1353, 0.1975, 0.4484, 0.0753, 0.4455, 0.5321, -0.1692, 0.4504,
0.2476, -0.1787, -0.2754, 0.2462],
[ 0.2326, 0.0623, -0.2984, 0.2878, 0.2767, -0.5434, -0.5051, 0.4339,
0.0302, 0.1634, 0.5649, -0.0055, 0.2025, 0.4473, -0.2333, 0.6611,
0.1883, -0.1250, 0.0820, 0.2778],
[ 0.3325, 0.2654, 0.1091, 0.0651, 0.3425, -0.3880, -0.0152, 0.2298,
0.3872, 0.0342, 0.8503, 0.0937, 0.1796, 0.5007, -0.1897, 0.4030,
0.1189, -0.3237, 0.2048, 0.4343]], grad_fn=<AddmmBackward0>)
After ReLU: tensor([[0.4158, 0.0000, 0.0000, 0.3960, 0.1476, 0.0000, 0.0000, 0.2690, 0.1353,
0.1975, 0.4484, 0.0753, 0.4455, 0.5321, 0.0000, 0.4504, 0.2476, 0.0000,
0.0000, 0.2462],
[0.2326, 0.0623, 0.0000, 0.2878, 0.2767, 0.0000, 0.0000, 0.4339, 0.0302,
0.1634, 0.5649, 0.0000, 0.2025, 0.4473, 0.0000, 0.6611, 0.1883, 0.0000,
0.0820, 0.2778],
[0.3325, 0.2654, 0.1091, 0.0651, 0.3425, 0.0000, 0.0000, 0.2298, 0.3872,
0.0342, 0.8503, 0.0937, 0.1796, 0.5007, 0.0000, 0.4030, 0.1189, 0.0000,
0.2048, 0.4343]], grad_fn=<ReluBackward0>)
nn.Sequential
nn.Sequential是模块的有序容器。数据按照定义的相同顺序传递通过所有模块。您可以使用顺序容器来组合一个快速网络,例如seq_modules.
seq_modules = nn.Sequential(
flatten,
layer1,
nn.ReLU(),
nn.Linear(20, 10)
)
input_image = torch.rand(3,28,28)
logits = seq_modules(input_image)
nn.Softmax
神经网络的最后一个线性层返回logits ( [-infty, infty] 中的原始值)被传递到 nn.Softmax模块。Softmax激活函数用于计算神经网络输出的概率。它仅用于神经网络的输出层。Logits 缩放为值 [0, 1],表示模型对每个类别的预测概率。dim参数指示维度,沿该维度值的总和必须为 1。具有最高概率的节点预测所需的输出。
softmax = nn.Softmax(dim=1)
pred_probab = softmax(logits)
Model Parameters 模型参数
神经网络内的许多层都是参数化的。在训练期间,优化的相关权重和偏差。子类化nn.Module会自动跟踪模型对象中定义的所有字段,并使所有参数都可以使用模型parameters()或named_parameters()方法进行访问。
在此示例中,我们迭代每个参数,并打印其大小及其值的预览。
print(f"Model structure: {model}\n\n")
for name, param in model.named_parameters():
print(f"Layer: {name} | Size: {param.size()} | Values : {param[:2]} \n")
Out:
Model structure: NeuralNetwork(
(flatten): Flatten(start_dim=1, end_dim=-1)
(linear_relu_stack): Sequential(
(0): Linear(in_features=784, out_features=512, bias=True)
(1): ReLU()
(2): Linear(in_features=512, out_features=512, bias=True)
(3): ReLU()
(4): Linear(in_features=512, out_features=10, bias=True)
)
)
Layer: linear_relu_stack.0.weight | Size: torch.Size([512, 784]) | Values : tensor([[ 0.0273, 0.0296, -0.0084, ..., -0.0142, 0.0093, 0.0135],
[-0.0188, -0.0354, 0.0187, ..., -0.0106, -0.0001, 0.0115]],
device='cuda:0', grad_fn=<SliceBackward0>)
Layer: linear_relu_stack.0.bias | Size: torch.Size([512]) | Values : tensor([-0.0155, -0.0327], device='cuda:0', grad_fn=<SliceBackward0>)
Layer: linear_relu_stack.2.weight | Size: torch.Size([512, 512]) | Values : tensor([[ 0.0116, 0.0293, -0.0280, ..., 0.0334, -0.0078, 0.0298],
[ 0.0095, 0.0038, 0.0009, ..., -0.0365, -0.0011, -0.0221]],
device='cuda:0', grad_fn=<SliceBackward0>)
Layer: linear_relu_stack.2.bias | Size: torch.Size([512]) | Values : tensor([ 0.0148, -0.0256], device='cuda:0', grad_fn=<SliceBackward0>)
Layer: linear_relu_stack.4.weight | Size: torch.Size([10, 512]) | Values : tensor([[-0.0147, -0.0229, 0.0180, ..., -0.0013, 0.0177, 0.0070],
[-0.0202, -0.0417, -0.0279, ..., -0.0441, 0.0185, -0.0268]],
device='cuda:0', grad_fn=<SliceBackward0>)
Layer: linear_relu_stack.4.bias | Size: torch.Size([10]) | Values : tensor([ 0.0070, -0.0411], device='cuda:0', grad_fn=<SliceBackward0>)
知识检查
PyTorch 中所有神经网络模块的基类为 torch.nn.Module
Further Reading 进一步阅读
- torch.nn API
Build the Neural Network — PyTorch Tutorials 2.2.0+cu121 documentation
Build the Neural Network — PyTorch Tutorials 2.2.0+cu121 documentation
References 参考资料
使用 PyTorch 进行机器学习的简介 - Training | Microsoft Learn
使用 PyTorch 进行机器学习的简介 - Training | Microsoft Learn
Github
storm-ice/PyTorch_Fundamentals文章来源地址https://www.toymoban.com/news/detail-802779.html文章来源:https://www.toymoban.com/news/detail-802779.html
storm-ice/PyTorch_Fundamentals
到了这里,关于【PyTorch简介】4.Building the model layers 生成模型层的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!