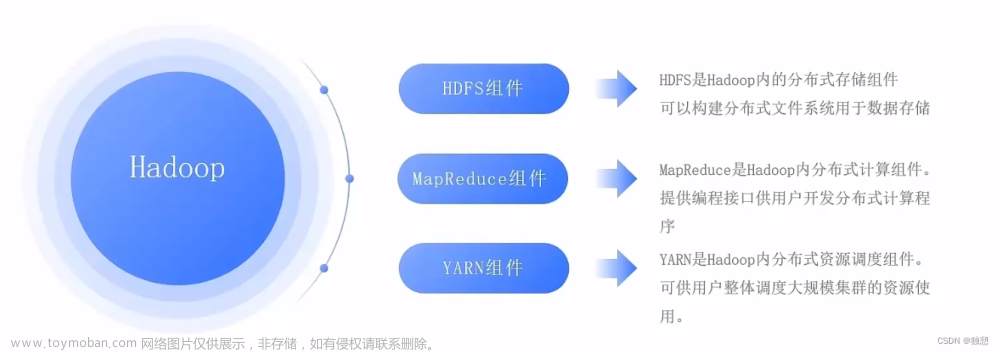
Hadoop分布式文件系统(Hadoop Distributed File System,HDFS)是Hadoop生态系统的核心组件之一,它是设计用于存储和处理大规模数据集的分布式文件系统。HDFS由多个组件组成,每个组件都有不同的功能。以下是HDFS的主要组件及其功能介绍:
1. NameNode(名称节点):NameNode是HDFS的主节点,负责管理文件系统的元数据。元数据包括文件和目录的命名空间、文件的块分配信息以及每个块的副本位置等。NameNode还负责处理客户端的文件系统操作请求,并管理数据块的复制和移动。
2. DataNode(数据节点):DataNode是HDFS的工作节点,负责存储实际的数据块。每个数据节点在本地存储上保存一个或多个数据块的副本,并定期向NameNode报告其存储情况。DataNode还处理客户端的读取和写入请求,并与其他数据节点之间进行数据块的复制和传输。
3. Secondary NameNode(辅助名称节点):Secondary NameNode并不是NameNode的备份,它的主要作用是协助NameNode进行元数据的备份和恢复。Secondary NameNode定期从NameNode获取元数据快照,并将其保存到本地磁盘上。这样,当NameNode发生故障时,可以使用Secondary NameNode的快照来恢复元数据。
4. Backup Node(备份节点):Backup Node是HDFS的可选组件,用于提供冷备份和热备份功能。Backup Node的作用类似于Secondary NameNode,但它可以在实时和连续的基础上备份NameNode的元数据,从而提供更快的故障恢复能力。
5. HDFS Federation(HDFS联邦):HDFS联邦是Hadoop 2.0引入的特性,它允许多个独立的HDFS命名空间共享一组数据节点。每个命名空间都有自己的NameNode,并管理自己的文件系统元数据。这样,可以将大规模的HDFS集群划分为多个相对较小的命名空间,以提高可扩展性和性能。
以上是HDFS的主要组件及其功能介绍。这些组件共同协作,实现了高可靠性、高可用性和高可扩展性的分布式文件存储和处理能力。
hdfs数据存储过程:
HDFS的数据存储过程可以分为以下几个步骤:
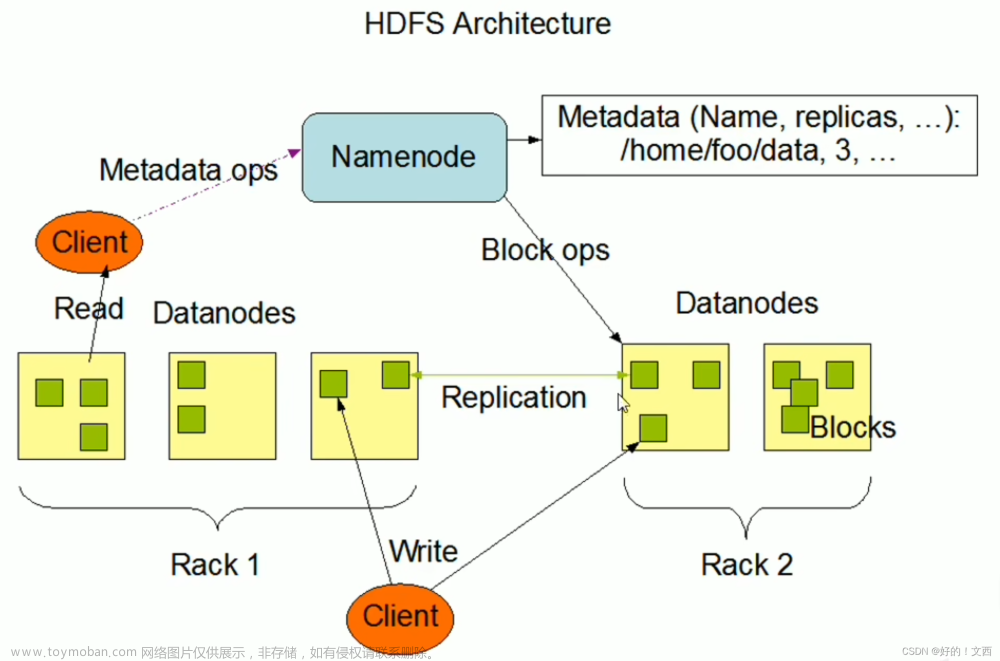
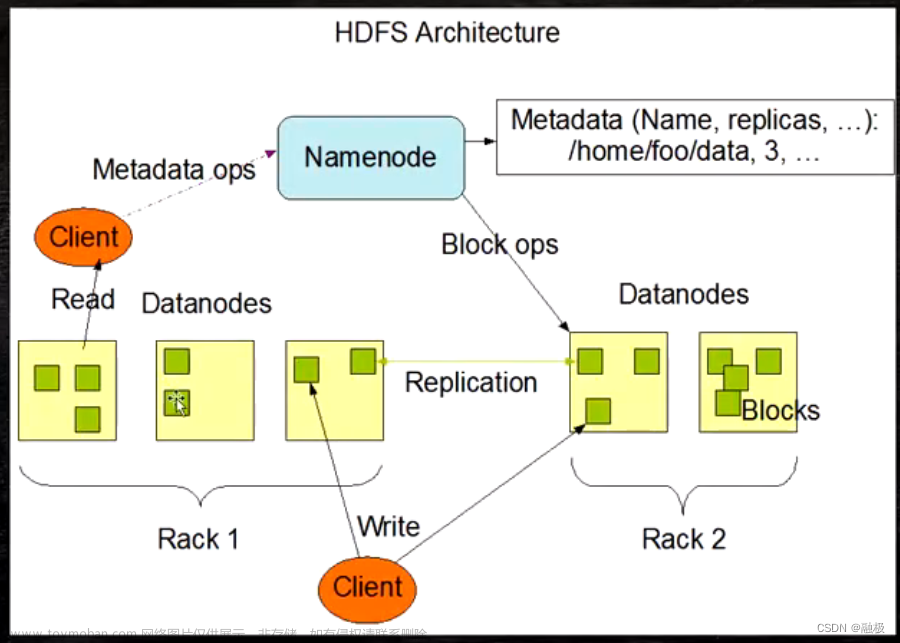
1. 切分文件:当一个文件要存储到HDFS中时,HDFS会将文件切分为固定大小的数据块(默认情况下为128MB)。切分文件的目的是为了将大文件分成更小的部分,便于分布式存储和处理。
2. 副本选择:HDFS会为每个数据块选择多个副本(默认情况下为3个)。副本的选择是通过网络拓扑和数据节点的负载情况来确定的。副本的分布在不同的数据节点上,以提高数据的可靠性和可用性。
3. 数据块存储:HDFS将数据块写入数据节点的本地文件系统中。每个数据节点会保存一个或多个数据块的副本,并定期向NameNode报告其存储情况。
4. 数据块复制:HDFS会自动对数据块进行复制,以提高数据的冗余和容错能力。副本的复制是通过数据节点之间的协作来完成的。当一个数据节点上的副本发生故障或不可用时,HDFS会自动将其复制到其他可用的节点上。
5. 数据读取:当客户端需要读取一个文件时,它会向NameNode发送请求,获取文件的元数据和数据块的位置信息。然后,客户端会直接与数据节点通信,读取相应的数据块。
6. 数据写入:当客户端需要向一个文件写入数据时,它会将数据分成固定大小的数据包,并与最近的数据节点建立连接。客户端会将数据包发送给数据节点,并由数据节点存储在本地文件系统中。当一个数据包被写入后,数据节点会向客户端发送确认信号。文章来源:https://www.toymoban.com/news/detail-802908.html
以上是HDFS的数据存储过程。通过数据的切分、副本选择、数据块存储和复制等步骤,HDFS实现了高可靠性、高可用性和高性能的分布式数据存储。文章来源地址https://www.toymoban.com/news/detail-802908.html
到了这里,关于HDFS及各组件功能介绍的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!