1. 前言
在工程师实际开发过程中,可能会经常遇到这样的需求:数据从数据源端不断地持续输入FPGA,FPGA需要对数据进行处理,最后将处理好的数据输出至客户端。
在数据处理过程中,可能需要一系列的处理步骤。比如常规的信号进行处理步骤有(这里的处理步骤只是举个例子):信号解调、滤波、傅里叶变换。
假如数据源每10ns输入一个数据,一个采用数据经过信号解调需要10ns,完成滤波需20ns,傅里叶变换需要30ns。我们该如何用verilog语言设计硬件电路使得数据处理效率高效?
2. 面临问题
FPGA一个较大的优势是其并行处理机制,即利用并行架构实现信号/数据处理的功能。
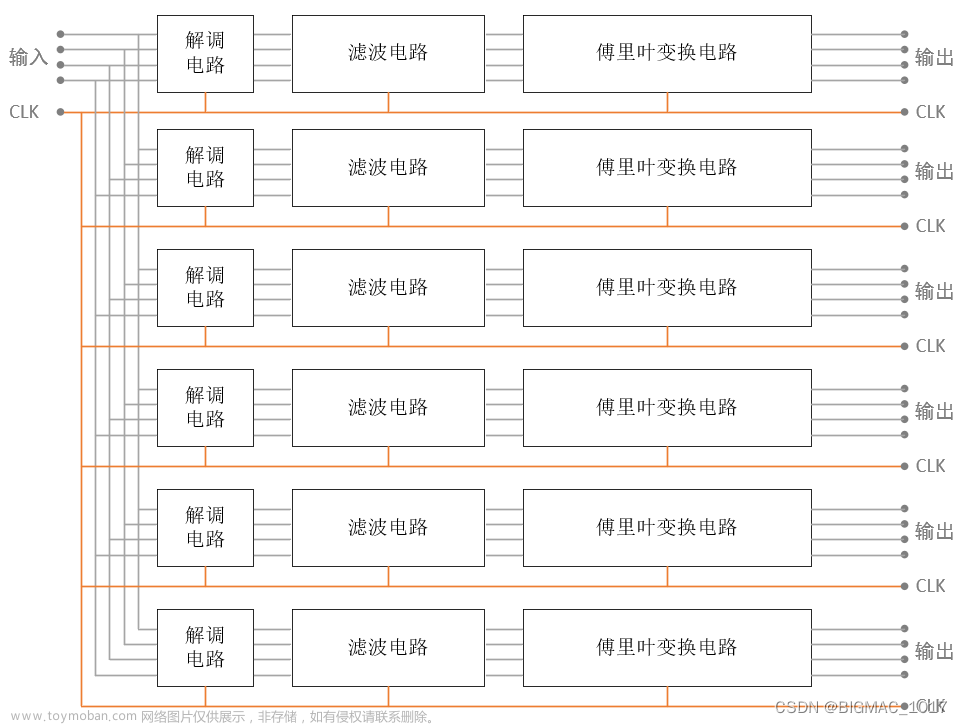
大家首先想到的方法就是复制多份数据处理电路,如下图所示:


将数据处理电路复制6份,这样即便每路数据处理需要60ns,也能保证整个由6路处理链路组成的数据模块能处理每10ns输出一个数据的数据源。
这种解决方案的确利用了FPGA独特的优势,但面临的问题是显而易见的,它需要消耗大量的硬件资源。比如当处理算法较复杂时,一条处理链路可能就用掉了FPGA相应60%的资源,这样除非换更大容量的FPGA,否则在当前FPGA上即使复制两遍处理链路的电路都是不支持的。
此外,我们深入分析会发现,电路虽然被复制了6份,但在同一时刻电路被使用率是很低的。假设输入一个数据时刻为0ns,则在第50ns时,真正处于工作状态的电路如下图所示(黄色标的区域):

可见同一时刻,工作的电路比例很低,其它白色的电路模块都是闲置的未工作的电路。
3. Pipeline解决方案
所谓流水线(pipeline)处理,如同生产装配线一样,将操作执行工作量分成若干个时间上均衡的操作段,从流水线的起点连续地输入,流水线的各操作段以重叠方式执行。
这使得操作执行速度只与流水线输入的速度有关,而与处理所需的时间无关。这样,在理想的流水操作状态下,其运行效率很高。
比如仍然以上面信号处理例子为例,我们不需要去复制6份同样的电路,而是去优化我们单条信号处理电路。利用pipeline的设计理念,我们需要把处理时间大于10ns的电路模块拆分成多个小于等于10ns的子电路(操作信号处理工作量分成若干个时间上均衡的处理段),并且每个子电路的输入是前一级子电路的输出,每一级子电路都能锁存当前时钟周期的输出结果。改造后的电路如下图所示:

对于一个输入数据的样本来说,数据是串行被处理的,但对于多个输入数据来说,各个处理阶段是并行执行的,所以数据处理从整体上看是并行执行的,由于是并行执行,所以能够充分利用FPGA资源。
需要注意的是,在工作时钟频率一定的情况下,pipeline的设计思路并不会提高对单个数据的处理速度,但该设计方式可以极大提高数据的吞吐率。同时由于pipeline的设计方式降低了FPGA寄存器间的传播延时,反而又使得设计出来的电路能以更高的系统时钟进行工作,某种程度上又会提高FPGA系统的工作速度获取更快的计算处理速率。
由于网上pipeline示例代码资源很多,本文就不提供pipeline的示例代码了。
4. 小结
利用pipeline的设计方法,可以提高FPGA系统的工作速度。这种方法可广泛运用于各种设计,特别是大型的、对速度要求较高的系统设计。虽然有时候采用流水线反而会增大对资源的使用,但是它可降低寄存器间的传播延时,保证系统维持高的系统时钟速度。文章来源:https://www.toymoban.com/news/detail-803149.html
在实际应用中,考虑到资源的使用和速度的要求,可以根据实际情况来选择流水线的级数以满足设计需要。文章来源地址https://www.toymoban.com/news/detail-803149.html
到了这里,关于南京观海微电子----Verilog流水线设计——Pipeline的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!