项目要点
- 读取图片: image = cv2.imread('./images/page.jpg')
- 调整图片尺寸: resized = cv2.resize(image, (width, height), interpolation = cv2.INTER_AREA)
- 灰度化处理: gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
- 高斯模糊去噪点: gray = cv2.GaussianBlur(gray, (5,5), 0)
- 边缘检测: edged = cv2.Canny(gray, 75, 200)
- cnts = cv2.findContours(edged.copy(), cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)[0] 用边缘检测的结果进行轮廓检测 # 返回值两个: contours, hierarchy
- 按照面积排序: cnts = sorted(cnts, key = cv2.contourArea, reverse = True)
- 显示轮廓: image_contours = cv2.drawContours(image.copy(), cnts, -1, (0, 0, 255), 2)
- 计算轮廓周长: perimeter = cv2.arcLength(c, True) # for c in cnts:
- 多边形逼近: approx = cv2.approxPolyDP(c, 0.02 * perimeter, True)
- 显示轮廓: image_contours = cv2.drawContours(image.copy(), [screen_cnt], -1, (0,0,255), 2)
- 计算变换矩阵: M =cv2.getPerspectiveTransform(rect,dst) # rect 是原始坐标,dst 是调整后坐标
- 通过坐标透视变换转换: warped = cv2.warpPerspective(image, M, (max_width, max_height))
- 灰度化处理: warped = cv2.cvtColor(warped, cv2.COLOR_BGR2GRAY) # 二值化只能处理二维图片
- 二值化处理: ref = cv2.threshold(warped, 120, 255, cv2.THRESH_BINARY)[1] # 两个返回值: ret, thresh1
- 保存图片: cv2.imwrite('./scan1.jpg', ref)
- 图片转文字: text = pytesseract.image_to_string(Image.open('./scan1.jpg')) # 需调包
- 保存str 到 txt文件:
with open('test.txt','w', encoding='utf-8') as f:
f.write(text)图片转文字项目
1 图片预处理
1.1 显示原图
def cv_show(name, img):
cv2.imshow(name, img)
cv2.waitKey(0)
cv2.destroyAllWindows()# 导包
import numpy as np
import cv2
# 读取图片
image = cv2.imread('./images/page.jpg')
print(image.shape) # (3264, 2448, 3)
# 计算比例,限定高度500
ratio = image.shape[0] / 500.0
orig = image.copy()
cv_show('img', image) # 图片极大, 看不全...
1.2 图片尺寸调整
def resize(image, width = None, height = None, inter = cv2.INTER_AREA):
# cv2.resize()
dim = None
(h, w) = image.shape[:2]
# print(image.shape[:2])
if width is None and height is None:
return image
if width is None: # 只提供了高度
r = height /float(h)
dim = (int(w * r), height)
# print(dim)
else: # 如果只提供了宽度
r = width / float(w)
dim = (width, int(h * r))
resized = cv2.resize(image, dim, interpolation = inter)
return resized
# 对图片进行 resize
image = resize(orig, height = 500)
cv_show('img', image) 
1.3 灰度化处理和轮廓检测
# 灰度化处理
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 高斯模糊去噪点
gray = cv2.GaussianBlur(gray, (5,5), 0)
# 边缘检测
edged = cv2.Canny(gray, 75, 200)
cv_show('img', edged)
1.4 轮廓检测
# 用边缘检测的结果进行轮廓检测
cnts = cv2.findContours(edged.copy(), cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)[0]
# 按照面积排序
cnts = sorted(cnts, key = cv2.contourArea, reverse = True)
print(len(cnts)) # 16 轮廓数量
# 显示轮廓
image_contours = cv2.drawContours(image.copy(), cnts, -1, (0, 0, 255), 2)
cv_show('img', image_contours)
1.5 找出最大轮廓
# 遍历轮廓,找出最大轮廓
for c in cnts:
# 计算轮廓周长
perimeter = cv2.arcLength(c, True)
# 多边形逼近
approx = cv2.approxPolyDP(c, 0.02 * perimeter, True)
if len(approx) == 4:
screen_cnt = approx
break
# 显示轮廓
image_contours = cv2.drawContours(image.copy(), [screen_cnt], -1, (0, 0, 255), 2)
cv_show('img', image_contours)
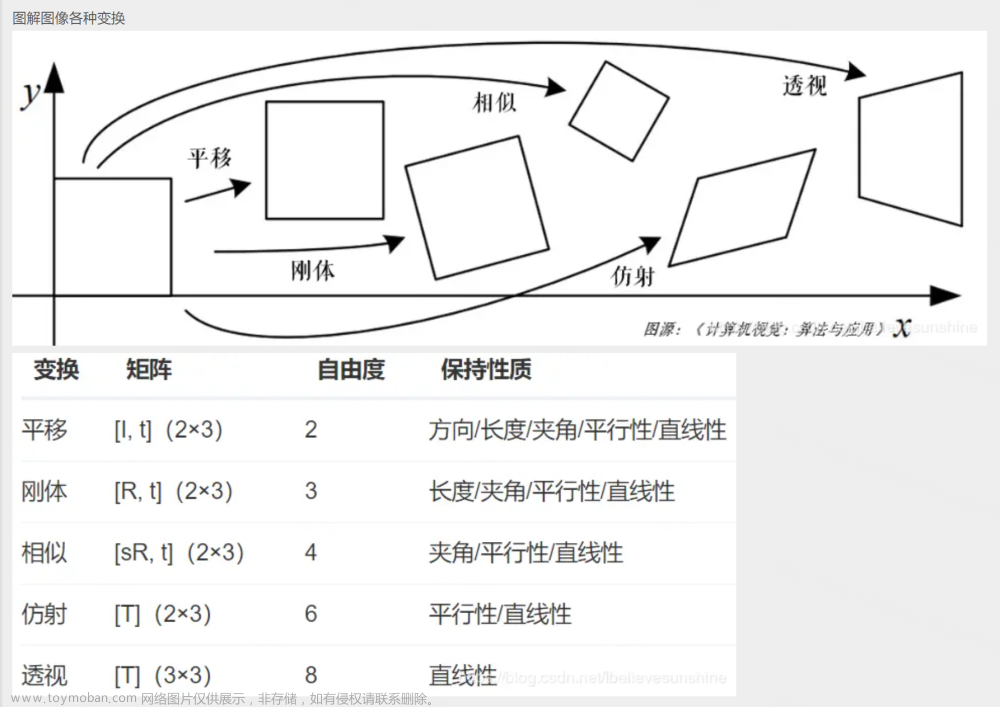
2 透视变换,拉正视角
2.1 透视转换
def order_points(pts):
# 创建全为0 的矩阵, 来接收找到的坐标
rect = np.zeros((4, 2), dtype = 'float32')
s = pts.sum(axis = 1)
# 左上角的坐标一定是X,Y相加最小的,右下为最大的
rect[0] = pts[np.argmin(s)]
rect[2] = pts[np.argmax(s)]
# 右上角的x,y 相减的差值一定是最小的
# 左下角的x,y 相减,差值一定是最大的
diff = np.diff(pts, axis = 1)
rect[1] = pts[np.argmin(diff)]
rect[3] = pts[np.argmax(diff)]
return rectdef four_point_transform(image, pts):
rect = order_points(pts)
(tl, tr, br, bl) = rect
widthA = np.sqrt((br[0] - bl[0]) ** 2 + (br[1] - bl[1]) ** 2)
widthB = np.sqrt((tr[0] - tl[0]) ** 2 + (tr[1] - tl[1]) ** 2)
max_width = max(int(widthA), int(widthB))
heightA = np.sqrt((tr[0] - br[0]) ** 2 + (tr[1] - br[1]) ** 2)
heightB = np.sqrt((tl[0] - bl[0]) ** 2 + (tl[1] - bl[1]) ** 2)
max_height = max(int(heightA), int(heightB))
dst = np.array([
[0, 0],
[max_width - 1, 0],
[max_width -1, max_height - 1],
[0, max_height -1]], dtype = 'float32')
M = cv2.getPerspectiveTransform(rect, dst)
warped = cv2.warpPerspective(image, M, (max_width, max_height))
return warped# 视图透视变换, 将视图转为正对透视
warped = four_point_transform(orig, screen_cnt.reshape(4, 2) * ratio)
# 二值化处理
warped = cv2.cvtColor(warped, cv2.COLOR_BGR2GRAY)
ref = cv2.threshold(warped, 120, 255, cv2.THRESH_BINARY)[1]
print(ref.shape) # (2624, 1962)
cv_show('ref', ref)
# 把处理好的图片写入文件
cv2.imwrite('./scan1.jpg', ref)
cv_show('warp', warped)
cv2.imwrite('./warped.jpg', warped)
 文章来源:https://www.toymoban.com/news/detail-803256.html
文章来源:https://www.toymoban.com/news/detail-803256.html
3 tesseract 进行识别
import pytesseract # 调用电脑的识图转文字功能
from PIL import Image
# pytesseract要求的image不是OpenCV读进来的image, 而是pillow这个包, 即PIL
text = pytesseract.image_to_string(Image.open('./scan1.jpg'))
print(text)
with open('test.txt','w', encoding='utf-8') as f:
f.write(text)- 文字识别结果
 文章来源地址https://www.toymoban.com/news/detail-803256.html
文章来源地址https://www.toymoban.com/news/detail-803256.html
到了这里,关于16- 图片转文字识别实操 (OpenCV系列) (项目十六)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!