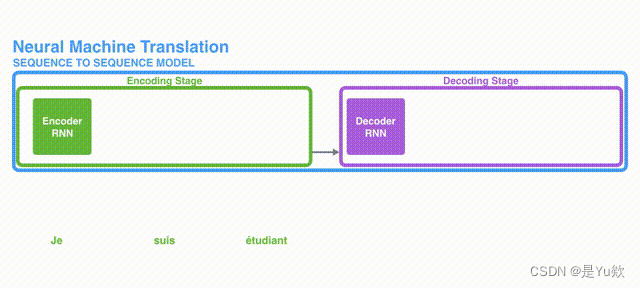
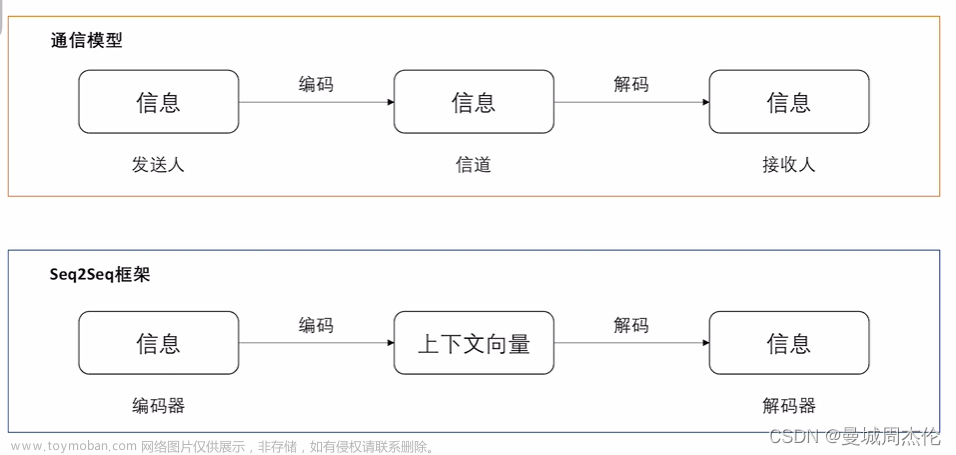
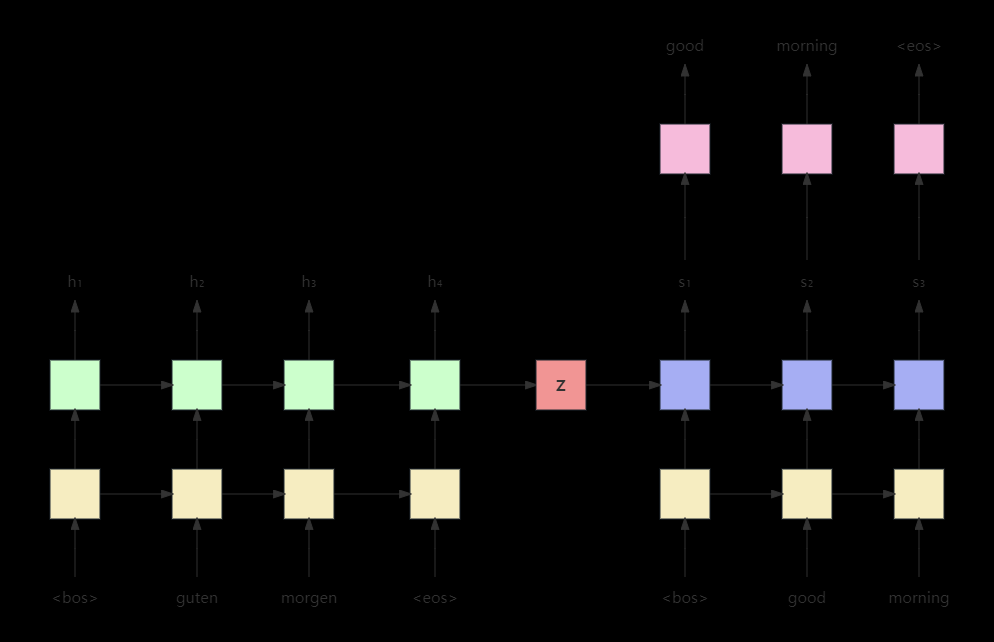
Knowledge Is Flat: A Seq2Seq Generative Framework for Various Knowledge Graph Completion
arxiv时间: September 15, 2022
作者单位i: 南洋理工大学
来源: COLING 2022
模型名称: KG-S2S
论文链接: https://arxiv.org/abs/2209.07299
项目链接: https://github.com/chenchens190009/KG-S2S
摘要
以往的研究通常将 KGC 模型与特定的图结构紧密结合,这不可避免地会导致两个缺点
- 特定结构的 KGC 模型互不兼容
- 现有 KGC 方法无法适应新兴 KG。
提出了KG-S2S
1. 引言
static KGC (SKGC)
temporal KGC (TKGC)
few-shot KGC (FKGC)
KG-S2S包括:
- the input representations of entities and relations using Entity Description, Soft Prompt and Seq2Seq Dropout
- the constrained inference algorithm empowered by the Prefix Constraints

2. 相关工作
Temporal KGC
许多 TKGC 模型在现有 KGC 方法的基础上加入了额外的特定时间参数。
Few-shot KGC
For one-shot learning on relations, Xiong et al. (2018) attempts to seek a matching metric that can be used to discover similar triples given one reference triple.
3. 方法

我们按照微调 Seq2Seq PLM(即 Cross-Entropy Loss)的常见做法,直接用正向示例训练 KG-S2S(KG-S2S 不需要负向采样技巧)。
两个问题
- 如何在 KG-S2S 编码器中有效地表示query?【3.3】
- 如何准确生成实体文本作为query的答案?【3.4】
3.3 Entity & Relation Representation
Entity Description
纯文本丢失了结构信息,在encoder中我们将实体名称和描述串联起来作为实体表示。在decoder上面我们训练 KG-S2S 在交叉熵损失条件下联合预测实体名称和实体描述。【有点意思】
KG Soft Prompt
we only apply the Soft Prompt to relations.
we insert the Relation Soft Prompt embeddings Pe1, Pe2, Pr1, Pr2 ∈ R ∣ R ∣ × d R^{|R|×d} R∣R∣×d,【见上图】
Seq2Seq Dropout
由于KGC 中不同训练查询中的实体描述保持不变,这很容易导致过度拟合。最初采用encoder droppout,但是效果很差,因此使用的seq2seq dropout.we randomly select and mask p% of the input tokens in X when calculating the encoder self-attention module and decoder cross-attention module.
3.4 KGC Inference
Decoding Methods
采用beam search方法
Prefix Constraints

我们提出了前缀约束,以控制 KG-S2S 解码器在给定前缀序列 p 的情况下生成有效标记。
For example, given E = {“Grammy Award for Best Rock Song”, “Grammy Award for Best Music Video”} and p = [Grammy, Award, for, Best], the Prefix Constraints only allow “Rock” and “Music” to be generated in the next step.
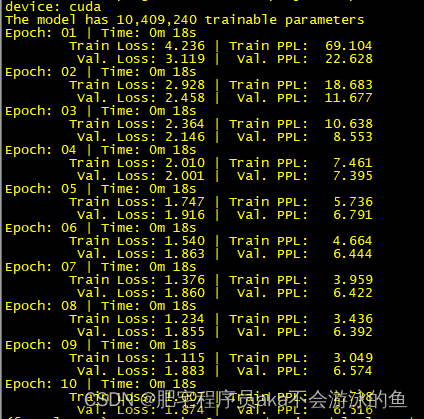
4. 实验
FB15K-237 包含许多过度简化的、不切实际的卡方乘积关系(CPR),这不适当地提高了模型的精度。例如,"东京一月份的平均低温为华氏 34 度 "这一多重事实被分解为多个 CPR 事实(东京,climate./month,1 月)和(东京,climate./average_min_temp,34),这显然是不现实的,在语义上也毫无意义。






【beam search和不使用,有区别,但是区别不大】文章来源:https://www.toymoban.com/news/detail-803533.html
5. 结论和未来工作
在本文中,我们介绍了针对各种知识图谱补全任务的 KG-S2S。通过将不同类型的知识图谱结构转换为 "文本-文本 "格式,KG-S2S 可以直接生成目标预测实体的文本。文章来源地址https://www.toymoban.com/news/detail-803533.html
到了这里,关于【论文笔记】Knowledge Is Flat: A Seq2Seq Generative Framework for Various Knowledge Graph Completion的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!