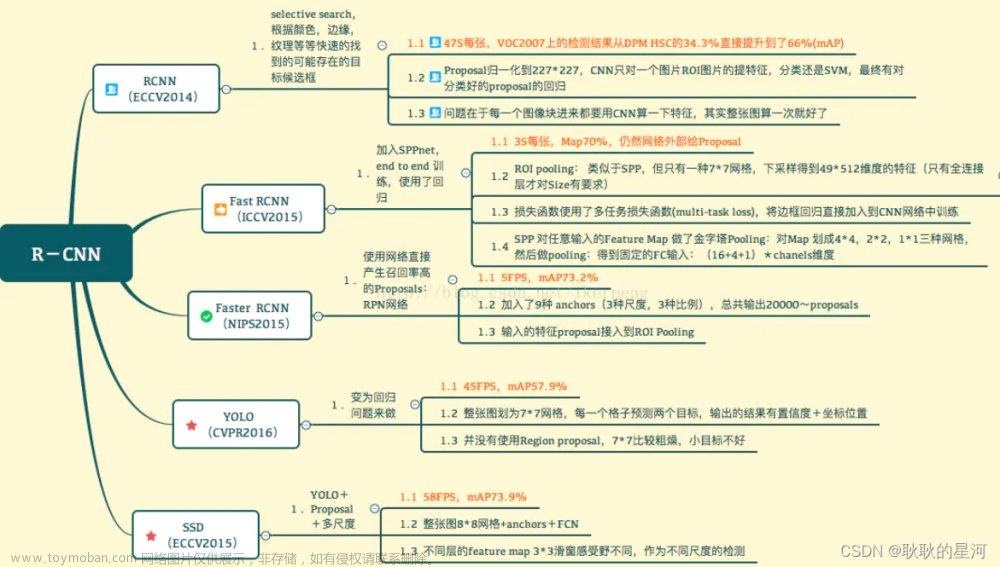
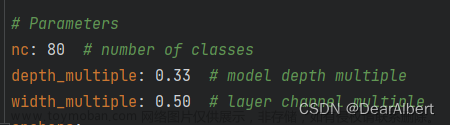
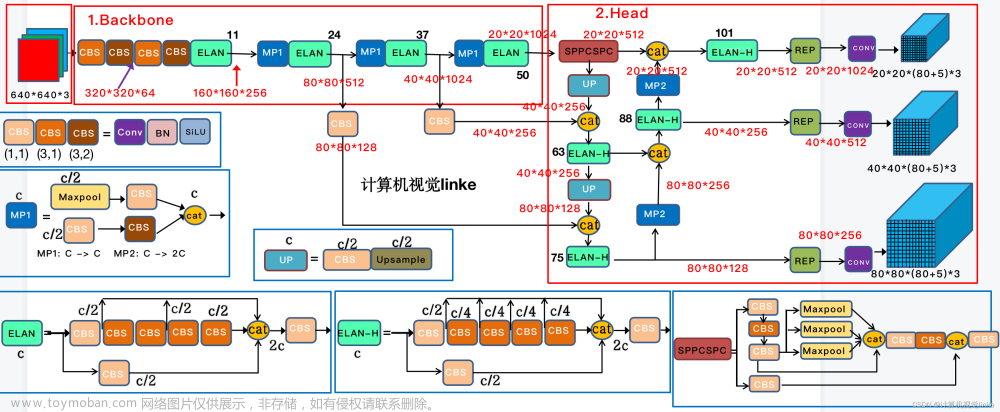
测试部分代码
import argparse
import json
import os
from pathlib import Path
from threading import Thread
import numpy as np
import torch
import yaml
from tqdm import tqdm
from models.experimental import attempt_load
from utils.datasets import create_dataloader
from utils.general import coco80_to_coco91_class, check_dataset, check_file, check_img_size, check_requirements, \
box_iou, non_max_suppression, scale_coords, xyxy2xywh, xywh2xyxy, set_logging, increment_path, colorstr
from utils.metrics import ap_per_class, ConfusionMatrix
from utils.plots import plot_images, output_to_target, plot_study_txt
from utils.torch_utils import select_device, time_synchronized, TracedModel
def test(data,
weights=None,
batch_size=32,
imgsz=640,
conf_thres=0.001,
iou_thres=0.6, # for NMS
save_json=False,
single_cls=False,
augment=False,
verbose=False,
model=None,
dataloader=None,
save_dir=Path(''), # for saving images
save_txt=False, # for auto-labelling
save_hybrid=False, # for hybrid auto-labelling
save_conf=False, # save auto-label confidences
plots=True,
wandb_logger=None,
compute_loss=None,
half_precision=True,
trace=False,
is_coco=False,
v5_metric=False):
# Initialize/load model and set device
training = model is not None
if training: # called by train.py
device = next(model.parameters()).device # get model device
else: # called directly
set_logging()
device = select_device(opt.device, batch_size=batch_size)
# Directories
save_dir = Path(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok)) # increment run
(save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
# Load model
model = attempt_load(weights, map_location=device) # load FP32 model
gs = max(int(model.stride.max()), 32) # grid size (max stride)
imgsz = check_img_size(imgsz, s=gs) # check img_size
if trace:
model = TracedModel(model, device, imgsz)
# Half
half = device.type != 'cpu' and half_precision # half precision only supported on CUDA
if half:
model.half()
# Configure
model.eval()
if isinstance(data, str):
is_coco = data.endswith('coco.yaml')
with open(data) as f:
data = yaml.load(f, Loader=yaml.SafeLoader)
check_dataset(data) # check
nc = 1 if single_cls else int(data['nc']) # number of classes
iouv = torch.linspace(0.5, 0.95, 10).to(device) # iou vector for mAP@0.5:0.95
niou = iouv.numel()
# Logging
log_imgs = 0
if wandb_logger and wandb_logger.wandb:
log_imgs = min(wandb_logger.log_imgs, 100)
# Dataloader
if not training:
if device.type != 'cpu':
model(torch.zeros(1, 3, imgsz, imgsz).to(device).type_as(next(model.parameters()))) # run once
task = opt.task if opt.task in ('train', 'val', 'test') else 'val' # path to train/val/test images
dataloader = create_dataloader(data[task], imgsz, batch_size, gs, opt, pad=0.5, rect=True,
prefix=colorstr(f'{task}: '))[0]
if v5_metric:
print("Testing with YOLOv5 AP metric...")
seen = 0
confusion_matrix = ConfusionMatrix(nc=nc)
names = {k: v for k, v in enumerate(model.names if hasattr(model, 'names') else model.module.names)}
coco91class = coco80_to_coco91_class()
s = ('%20s' + '%12s' * 6) % ('Class', 'Images', 'Labels', 'P', 'R', 'mAP@.5', 'mAP@.5:.95')
p, r, f1, mp, mr, map50, map, t0, t1 = 0., 0., 0., 0., 0., 0., 0., 0., 0.
loss = torch.zeros(3, device=device)
jdict, stats, ap, ap_class, wandb_images = [], [], [], [], []
for batch_i, (img, targets, paths, shapes) in enumerate(tqdm(dataloader, desc=s)):
img = img.to(device, non_blocking=True)
img = img.half() if half else img.float() # uint8 to fp16/32
img /= 255.0 # 0 - 255 to 0.0 - 1.0
targets = targets.to(device)
nb, _, height, width = img.shape # batch size, channels, height, width
with torch.no_grad():
# Run model
t = time_synchronized()
out, train_out = model(img, augment=augment) # inference and training outputs
t0 += time_synchronized() - t
# Compute loss
if compute_loss:
loss += compute_loss([x.float() for x in train_out], targets)[1][:3] # box, obj, cls
# Run NMS
targets[:, 2:] *= torch.Tensor([width, height, width, height]).to(device) # to pixels
lb = [targets[targets[:, 0] == i, 1:] for i in range(nb)] if save_hybrid else [] # for autolabelling
t = time_synchronized()
out = non_max_suppression(out, conf_thres=conf_thres, iou_thres=iou_thres, labels=lb, multi_label=True)
t1 += time_synchronized() - t
# Statistics per image
for si, pred in enumerate(out):
labels = targets[targets[:, 0] == si, 1:]
nl = len(labels)
tcls = labels[:, 0].tolist() if nl else [] # target class
path = Path(paths[si])
seen += 1
if len(pred) == 0:
if nl:
stats.append((torch.zeros(0, niou, dtype=torch.bool), torch.Tensor(), torch.Tensor(), tcls))
continue
# Predictions
predn = pred.clone()
scale_coords(img[si].shape[1:], predn[:, :4], shapes[si][0], shapes[si][1]) # native-space pred
# Append to text file
if save_txt:
gn = torch.tensor(shapes[si][0])[[1, 0, 1, 0]] # normalization gain whwh
for *xyxy, conf, cls in predn.tolist():
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
with open(save_dir / 'labels' / (path.stem + '.txt'), 'a') as f:
f.write(('%g ' * len(line)).rstrip() % line + '\n')
# W&B logging - Media Panel Plots
if len(wandb_images) < log_imgs and wandb_logger.current_epoch > 0: # Check for test operation
if wandb_logger.current_epoch % wandb_logger.bbox_interval == 0:
box_data = [{"position": {"minX": xyxy[0], "minY": xyxy[1], "maxX": xyxy[2], "maxY": xyxy[3]},
"class_id": int(cls),
"box_caption": "%s %.3f" % (names[cls], conf),
"scores": {"class_score": conf},
"domain": "pixel"} for *xyxy, conf, cls in pred.tolist()]
boxes = {"predictions": {"box_data": box_data, "class_labels": names}} # inference-space
wandb_images.append(wandb_logger.wandb.Image(img[si], boxes=boxes, caption=path.name))
wandb_logger.log_training_progress(predn, path, names) if wandb_logger and wandb_logger.wandb_run else None
# Append to pycocotools JSON dictionary
if save_json:
# [{"image_id": 42, "category_id": 18, "bbox": [258.15, 41.29, 348.26, 243.78], "score": 0.236}, ...
image_id = int(path.stem) if path.stem.isnumeric() else path.stem
box = xyxy2xywh(predn[:, :4]) # xywh
box[:, :2] -= box[:, 2:] / 2 # xy center to top-left corner
for p, b in zip(pred.tolist(), box.tolist()):
jdict.append({'image_id': image_id,
'category_id': coco91class[int(p[5])] if is_coco else int(p[5]),
'bbox': [round(x, 3) for x in b],
'score': round(p[4], 5)})
# Assign all predictions as incorrect
correct = torch.zeros(pred.shape[0], niou, dtype=torch.bool, device=device)
if nl:
"""
predn: {x1, y1, x2, y2, conf, cls}
tensor([[319.32043, 43.82351, 426.80283, 110.60916, 0.90186, 17.00000],
[ 84.76453, 36.17760, 120.57571, 67.90933, 0.65967, 19.00000],
[3.41989, 57.74736, 94.48680, 110.90230, 0.51758, 8.00000]], device='cuda:0')
labels: {cls, x, y, w, h}
tensor([[ 19.00000, 148.48001, 75.52252, 44.80000, 46.05405],
[ 17.00000, 492.80002, 106.86487, 139.51996, 88.27026],
[ 17.00000, 79.36000, 124.77477, 124.16000, 52.45045]], device='cuda:0')
tobx: {x1, y1, x2, y2}
tensor([[ 86.04846, 34.00000, 121.06818, 70.00000],
[318.17920, 42.00001, 427.24057, 111.00000],
[1.00056, 70.00000, 98.05522, 111.00000]], device='cuda:0')
tcls_tensor: {cls}
tensor([19., 17., 17.], device='cuda:0')
"""
detected = [] # target indices
tcls_tensor = labels[:, 0]
# target boxes
tbox = xywh2xyxy(labels[:, 1:5])
scale_coords(img[si].shape[1:], tbox, shapes[si][0], shapes[si][1]) # native-space labels
if plots:
confusion_matrix.process_batch(predn, torch.cat((labels[:, 0:1], tbox), 1))
# Per target class
# for cls in torch.unique(tcls_tensor):
# ti = (cls == tcls_tensor).nonzero(as_tuple=False).view(-1) # prediction indices
# pi = (cls == pred[:, 5]).nonzero(as_tuple=False).view(-1) # target indices
# # Search for detections
# if pi.shape[0]:
# # Prediction to target ious
# ious, i = box_iou(predn[pi, :4], tbox[ti]).max(1) # best ious, indices
# # Append detections
# detected_set = set()
# for j in (ious > iouv[0]).nonzero(as_tuple=False):
# d = ti[i[j]] # detected target
# if d.item() not in detected_set:
# detected_set.add(d.item())
# detected.append(d)
# correct[pi[j]] = ious[j] > iouv # iou_thres is 1xn
# if len(detected) == nl: # all targets already located in image
# break
# # Append statistics (correct, conf, pcls, tcls)
# stats.append((correct.cpu(), pred[:, 4].cpu(), pred[:, 5].cpu(), tcls))
# # Plot images
# if plots and batch_i < 3:
# f = save_dir / f'test_batch{batch_i}_labels.jpg' # labels
# Thread(target=plot_images, args=(img, targets, paths, f, names), daemon=True).start()
# f = save_dir / f'test_batch{batch_i}_pred.jpg' # predictions
# Thread(target=plot_images, args=(img, output_to_target(out), paths, f, names), daemon=True).start()
confusion_matrix.plot(save_dir=save_dir, names=list(names.values()))
# Compute statistics
stats = [np.concatenate(x, 0) for x in zip(*stats)] # to numpy
if len(stats) and stats[0].any():
p, r, ap, f1, ap_class = ap_per_class(*stats, plot=plots, v5_metric=v5_metric, save_dir=save_dir, names=names)
ap50, ap = ap[:, 0], ap.mean(1) # AP@0.5, AP@0.5:0.95
mp, mr, map50, map = p.mean(), r.mean(), ap50.mean(), ap.mean()
nt = np.bincount(stats[3].astype(np.int64), minlength=nc) # number of targets per class
else:
nt = torch.zeros(1)
# Print results
pf = '%20s' + '%12i' * 2 + '%12.3g' * 4 # print format
print(pf % ('all', seen, nt.sum(), mp, mr, map50, map))
# Print results per class
if (verbose or (nc < 50 and not training)) and nc > 1 and len(stats):
for i, c in enumerate(ap_class):
print(pf % (names[c], seen, nt[c], p[i], r[i], ap50[i], ap[i]))
# Print speeds
t = tuple(x / seen * 1E3 for x in (t0, t1, t0 + t1)) + (imgsz, imgsz, batch_size) # tuple
if not training:
print('Speed: %.1f/%.1f/%.1f ms inference/NMS/total per %gx%g image at batch-size %g' % t)
# Plots
if plots:
confusion_matrix.plot(save_dir=save_dir, names=list(names.values()))
if wandb_logger and wandb_logger.wandb:
val_batches = [wandb_logger.wandb.Image(str(f), caption=f.name) for f in sorted(save_dir.glob('test*.jpg'))]
wandb_logger.log({"Validation": val_batches})
if wandb_images:
wandb_logger.log({"Bounding Box Debugger/Images": wandb_images})
# Save JSON
if save_json and len(jdict):
w = Path(weights[0] if isinstance(weights, list) else weights).stem if weights is not None else '' # weights
anno_json = './coco/annotations/instances_val2017.json' # annotations json
pred_json = str(save_dir / f"{w}_predictions.json") # predictions json
print('\nEvaluating pycocotools mAP... saving %s...' % pred_json)
with open(pred_json, 'w') as f:
json.dump(jdict, f)
try: # https://github.com/cocodataset/cocoapi/blob/master/PythonAPI/pycocoEvalDemo.ipynb
from pycocotools.coco import COCO
from pycocotools.cocoeval import COCOeval
anno = COCO(anno_json) # init annotations api
pred = anno.loadRes(pred_json) # init predictions api
eval = COCOeval(anno, pred, 'bbox')
if is_coco:
eval.params.imgIds = [int(Path(x).stem) for x in dataloader.dataset.img_files] # image IDs to evaluate
eval.evaluate()
eval.accumulate()
eval.summarize()
map, map50 = eval.stats[:2] # update results (mAP@0.5:0.95, mAP@0.5)
except Exception as e:
print(f'pycocotools unable to run: {e}')
# Return results
model.float() # for training
if not training:
s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else ''
print(f"Results saved to {save_dir}{s}")
maps = np.zeros(nc) + map
for i, c in enumerate(ap_class):
maps[c] = ap[i]
return (mp, mr, map50, map, *(loss.cpu() / len(dataloader)).tolist()), maps, t
if __name__ == '__main__':
parser = argparse.ArgumentParser(prog='test.py')
parser.add_argument('--weights', nargs='+', type=str, default='runs/train/exp10/weights/best.pt', help='model.pt path(s)')
parser.add_argument('--data', type=str, default='data/voc.yaml', help='*.data path')
parser.add_argument('--batch-size', type=int, default=1, help='size of each image batch')
parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.5, help='object confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.65, help='IOU threshold for NMS')
parser.add_argument('--task', default='test', help='train, val, test, speed or study')
parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--single-cls', action='store_true', help='treat as single-class dataset')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--verbose', action='store_true', help='report mAP by class')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-hybrid', action='store_true', help='save label+prediction hybrid results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--save-json', action='store_true', help='save a cocoapi-compatible JSON results file')
parser.add_argument('--project', default='runs/test', help='save to project/name')
parser.add_argument('--name', default='yolov7_640_val', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--no-trace', action='store_true', help='don`t trace model')
parser.add_argument('--v5-metric', action='store_true', help='assume maximum recall as 1.0 in AP calculation')
opt = parser.parse_args()
opt.save_json |= opt.data.endswith('coco.yaml')
opt.data = check_file(opt.data) # check file
print(opt)
#check_requirements()
if opt.task in ('train', 'val', 'test'): # run normally
test(opt.data,
opt.weights,
opt.batch_size,
opt.img_size,
opt.conf_thres,
opt.iou_thres,
opt.save_json,
opt.single_cls,
opt.augment,
opt.verbose,
save_txt=opt.save_txt | opt.save_hybrid,
save_hybrid=opt.save_hybrid,
save_conf=opt.save_conf,
trace=not opt.no_trace,
v5_metric=opt.v5_metric
)
elif opt.task == 'speed': # speed benchmarks
for w in opt.weights:
test(opt.data, w, opt.batch_size, opt.img_size, 0.25, 0.45, save_json=False, plots=False, v5_metric=opt.v5_metric)
elif opt.task == 'study': # run over a range of settings and save/plot
# python test.py --task study --data coco.yaml --iou 0.65 --weights yolov7.pt
x = list(range(256, 1536 + 128, 128)) # x axis (image sizes)
for w in opt.weights:
f = f'study_{Path(opt.data).stem}_{Path(w).stem}.txt' # filename to save to
y = [] # y axis
for i in x: # img-size
print(f'\nRunning {f} point {i}...')
r, _, t = test(opt.data, w, opt.batch_size, i, opt.conf_thres, opt.iou_thres, opt.save_json,
plots=False, v5_metric=opt.v5_metric)
y.append(r + t) # results and times
np.savetxt(f, y, fmt='%10.4g') # save
os.system('zip -r study.zip study_*.txt')
plot_study_txt(x=x) # plot
混淆矩阵代码:
class ConfusionMatrix:
# Updated version of https://github.com/kaanakan/object_detection_confusion_matrix
def __init__(self, nc, conf=0.25, iou_thres=0.45):
self.matrix = np.zeros((nc + 1, nc + 1))
self.nc = nc # number of classes
self.conf = conf
self.iou_thres = iou_thres
def process_batch(self, detections, labels):
"""
Return intersection-over-union (Jaccard index) of boxes.
Both sets of boxes are expected to be in (x1, y1, x2, y2) format.
Arguments:
detections (Array[N, 6]), x1, y1, x2, y2, conf, class
labels (Array[M, 5]), class, x1, y1, x2, y2
Returns:
None, updates confusion matrix accordingly
"""
detections = detections[detections[:, 4] > self.conf]
gt_classes = labels[:, 0].int()
detection_classes = detections[:, 5].int()
iou = general.box_iou(labels[:, 1:], detections[:, :4])
x = torch.where(iou > self.iou_thres)
if x[0].shape[0]:
matches = torch.cat((torch.stack(x, 1), iou[x[0], x[1]][:, None]), 1).cpu().numpy()
if x[0].shape[0] > 1:
matches = matches[matches[:, 2].argsort()[::-1]]
matches = matches[np.unique(matches[:, 1], return_index=True)[1]]
matches = matches[matches[:, 2].argsort()[::-1]]
matches = matches[np.unique(matches[:, 0], return_index=True)[1]]
else:
matches = np.zeros((0, 3))
n = matches.shape[0] > 0
m0, m1, _ = matches.transpose().astype(np.int16)
for i, gc in enumerate(gt_classes):
j = m0 == i
if n and sum(j) == 1:
self.matrix[gc, detection_classes[m1[j]]] += 1 # correct
else:
self.matrix[self.nc, gc] += 1 # background FP
if n:
for i, dc in enumerate(detection_classes):
if not any(m1 == i):
self.matrix[dc, self.nc] += 1 # background FN
def matrix(self):
return self.matrix
def plot(self, save_dir='', names=()):
try:
import seaborn as sn
# self.matrix:------------> (21, 21)
print("self.matrix:------------>", self.matrix.shape)
array = self.matrix / (self.matrix.sum(0).reshape(1, self.nc + 1) + 1E-6) # normalize
array[array < 0.005] = np.nan # don't annotate (would appear as 0.00)
fig = plt.figure(figsize=(12, 9), tight_layout=True)
sn.set(font_scale=1.0 if self.nc < 50 else 0.8) # for label size
labels = (0 < len(names) < 99) and len(names) == self.nc # apply names to ticklabels
sn.heatmap(array, annot=self.nc < 30, annot_kws={"size": 8}, cmap='Blues', fmt='.2f', square=True,
xticklabels=names + ['background FP'] if labels else "auto",
yticklabels=names + ['background FN'] if labels else "auto").set_facecolor((1, 1, 1))
fig.axes[0].set_xlabel('True')
fig.axes[0].set_ylabel('Predicted')
fig.savefig(Path(save_dir) / 'confusion_matrix.png', dpi=250)
except Exception as e:
pass
def print(self):
for i in range(self.nc + 1):
print(' '.join(map(str, self.matrix[i])))
数据集划分代码:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
import random
from shutil import copyfile
classes = ["aeroplane",
"bicycle",
"bird",
"boat",
"bottle",
"bus",
"car",
"cat",
"chair",
"cow",
"diningtable",
"dog",
"horse",
"motorbike",
"person",
"pottedplant",
"sheep",
"sofa",
"train",
"tvmonitor"]
TRAIN_RATIO = 70
def clear_hidden_files(path):
dir_list = os.listdir(path)
for i in dir_list:
abspath = os.path.join(os.path.abspath(path), i)
if os.path.isfile(abspath):
if i.startswith("._"):
os.remove(abspath)
else:
clear_hidden_files(abspath)
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('VOCdevkit/VOC2007/Annotations/%s.xml' % image_id)
out_file = open('VOCdevkit/VOC2007/YOLOLabels/%s.txt' % image_id, 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
# difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
in_file.close()
out_file.close()
wd = os.getcwd()
wd = os.getcwd()
data_base_dir = os.path.join(wd, "VOCdevkit/")
if not os.path.isdir(data_base_dir):
os.mkdir(data_base_dir)
work_sapce_dir = os.path.join(data_base_dir, "VOC2007/")
if not os.path.isdir(work_sapce_dir):
os.mkdir(work_sapce_dir)
annotation_dir = os.path.join(work_sapce_dir, "Annotations/")
if not os.path.isdir(annotation_dir):
os.mkdir(annotation_dir)
clear_hidden_files(annotation_dir)
image_dir = os.path.join(work_sapce_dir, "JPEGImages/")
if not os.path.isdir(image_dir):
os.mkdir(image_dir)
clear_hidden_files(image_dir)
yolo_labels_dir = os.path.join(work_sapce_dir, "YOLOLabels/")
if not os.path.isdir(yolo_labels_dir):
os.mkdir(yolo_labels_dir)
clear_hidden_files(yolo_labels_dir)
yolov5_images_dir = os.path.join(data_base_dir, "images/")
if not os.path.isdir(yolov5_images_dir):
os.mkdir(yolov5_images_dir)
clear_hidden_files(yolov5_images_dir)
yolov5_labels_dir = os.path.join(data_base_dir, "labels/")
if not os.path.isdir(yolov5_labels_dir):
os.mkdir(yolov5_labels_dir)
clear_hidden_files(yolov5_labels_dir)
yolov5_images_train_dir = os.path.join(yolov5_images_dir, "train/")
if not os.path.isdir(yolov5_images_train_dir):
os.mkdir(yolov5_images_train_dir)
clear_hidden_files(yolov5_images_train_dir)
yolov5_images_test_dir = os.path.join(yolov5_images_dir, "val/")
if not os.path.isdir(yolov5_images_test_dir):
os.mkdir(yolov5_images_test_dir)
clear_hidden_files(yolov5_images_test_dir)
yolov5_labels_train_dir = os.path.join(yolov5_labels_dir, "train/")
if not os.path.isdir(yolov5_labels_train_dir):
os.mkdir(yolov5_labels_train_dir)
clear_hidden_files(yolov5_labels_train_dir)
yolov5_labels_test_dir = os.path.join(yolov5_labels_dir, "val/")
if not os.path.isdir(yolov5_labels_test_dir):
os.mkdir(yolov5_labels_test_dir)
clear_hidden_files(yolov5_labels_test_dir)
train_file = open(os.path.join(wd, "yolov7_train.txt"), 'w')
test_file = open(os.path.join(wd, "yolov7_val.txt"), 'w')
train_file.close()
test_file.close()
train_file = open(os.path.join(wd, "yolov7_train.txt"), 'a')
test_file = open(os.path.join(wd, "yolov7_val.txt"), 'a')
list_imgs = os.listdir(image_dir) # list image files
prob = random.randint(1, 100)
print("Probability: %d" % prob)
for i in range(0, len(list_imgs)):
path = os.path.join(image_dir, list_imgs[i])
if os.path.isfile(path):
image_path = image_dir + list_imgs[i]
voc_path = list_imgs[i]
(nameWithoutExtention, extention) = os.path.splitext(os.path.basename(image_path))
(voc_nameWithoutExtention, voc_extention) = os.path.splitext(os.path.basename(voc_path))
annotation_name = nameWithoutExtention + '.xml'
annotation_path = os.path.join(annotation_dir, annotation_name)
label_name = nameWithoutExtention + '.txt'
label_path = os.path.join(yolo_labels_dir, label_name)
prob = random.randint(1, 100)
print("Probability: %d" % prob)
if (prob < TRAIN_RATIO): # train dataset
if os.path.exists(annotation_path):
train_file.write(image_path + '\n')
convert_annotation(nameWithoutExtention) # convert label
copyfile(image_path, yolov5_images_train_dir + voc_path)
copyfile(label_path, yolov5_labels_train_dir + label_name)
else: # test dataset
if os.path.exists(annotation_path):
test_file.write(image_path + '\n')
convert_annotation(nameWithoutExtention) # convert label
copyfile(image_path, yolov5_images_test_dir + voc_path)
copyfile(label_path, yolov5_labels_test_dir + label_name)
train_file.close()
test_file.close()
文章来源地址https://www.toymoban.com/news/detail-803550.html
文章来源:https://www.toymoban.com/news/detail-803550.html
到了这里,关于yolov7混淆矩阵的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!