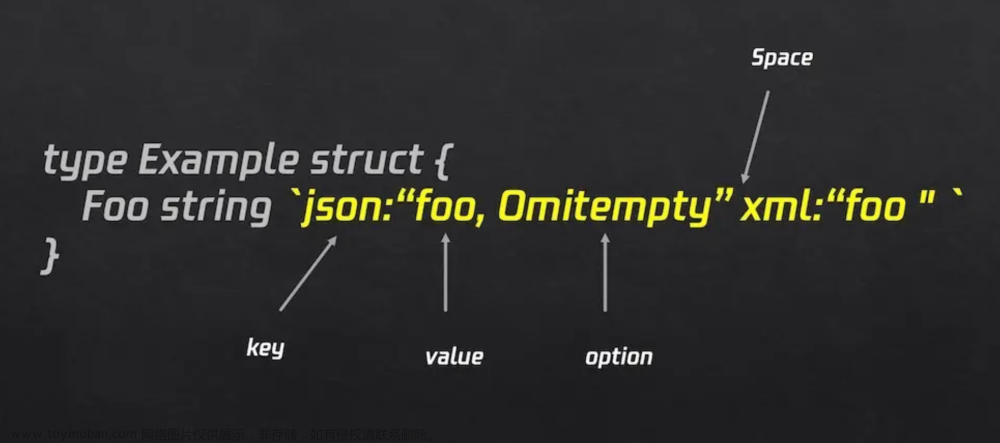
【Go】rune和byte类型的认识与使用
大家好 我是寸铁👊
总结了一篇rune和byte类型的认识与使用的文章✨
喜欢的小伙伴可以点点关注 💝
byte和rune类型定义
byte,占用1个字节,共8个比特位,所以它实际上和uint8没什么本质区别,它表示的是一个ASCII码字符。
rune,占用4个字节,共32个比特位,所以它实际上和int32没什么本质区别,它表示的是一个Unicode字符
(Unicode是一种能表示世界上绝大部分字符的编码格式)
不妨来验证一下,能否用uint8和byte一样去表示一个字符,能否用int32和rune一样去表示一个字符?
Demo
package main
import "fmt"
func main() {
//byte与uint32
var a byte = 'a'
var b uint8 = 'a'
fmt.Println("使用byte类型表示字符:", string(a)) //a
fmt.Println("使用uint8类型表示字符串: ", string(b)) //a
fmt.Println("---------------")
var c rune = 'b'
var d int32 = 'b'
fmt.Println("使用rune类型表示字符:", string(c)) //b
fmt.Println("使用int32类型表示字符串: ", string(d)) //b
}
运行结果如下:
答案是可以的,也证明了这两种实际上并无本质区别。
这次来验证一下,能否用uint8和byte数组去表示一个字符串,能否用int32和rune数组一样去表示一个字符串?
demo
package main
import "fmt"
func main() {
str := "nana"
s := []byte(str)
fmt.Println("使用byte类型表示字符串: ", string(s)) //nana
str1 := "nana"
s1 := []uint8(str1)
fmt.Println("使用uint8类型表示字符串: ", string(s1)) //nana
fmt.Println("____________________")
str2 := "nanago"
s2 := []rune(str2)
fmt.Println("使用rune类型表示字符串: ", string(s2)) //nanago
str3 := "nanago"
s3 := []int32(str3)
fmt.Println("使用int32类型表示字符串: ", string(s3)) //nanago
}
运行结果如下:
答案是可以的,也证明了这两种实际上并无本质区别。
有人会问:既然本质没什么区别,为什么还要创建byte和rune类型?
这就涉及到类型别名的概念,众所周知,Go语言有两种类型声明方式:一种叫类型定义声明;另一种叫类型别名声明。其中,别名的使用在大型项目重构中作用最为明显,它能够解决代码升级或者迁移过程中可能存在的类型兼容性问题。而rune和byte是Go语言中仅有的两个类型别名,专门用于处理字符。当然,我们可以通过type等关键字加=号的方式声明更多的类型别名。
rune的使用
我们知道,字符串由字符组成,字符的底层由字节组成,而一个字符串的底层的表示是一个字节序列(数组)。在Go语言中,字符可以被分成两种类型处理: 对占一个字节的英文类字符,可以使用byte或者uint8。对占1~4个字节的其他字符,可以使用rune或者int32,如中文、日文、特殊符号等。
示例说明:
rune类型表示中文符号
如下图:这说明可以用rune表示中文符号,不能用byte表示中文符号,没有定义rune类型去表示中文符号,会出现溢出现象。
为什么会出现精度溢出?
很明显,刚才说到byte是一个字节,而rune是1~4个字节。我们知道,英文是1个字节,中文是3个字节。byte最多只能表示一个字节的字符,但是,中文是3个字节的,byte1个字节去表示3个字节的字符,必定是不够的,也就造成overflow(溢出)现象。
demo
package main
import "fmt"
func main() {
//使用rune类型表示一个中文 一个字符 字节序列
var a rune = '云'
fmt.Println(string(a))
var b byte = '云'
fmt.Println(string(b))
//统计带中文的字符串长度
}
运行结果如下:
所以,rune的第一个作用是表示中文符号。
统计字符串的长度
举个例子:统计带中文的字符串的长度
demo
package main
import "fmt"
func main() {
//统计带中文字符串的长度
fmt.Println(len("Go语言编程")) //14
//转换为rune数组后统计带中文字符串的长度
fmt.Println(len([]rune("Go语言编程"))) //6
}
运行结果如下:
分析一下结果:为什么直接打印就是14,转换为rune[]数组后打印为6?
分析:字符串在底层表示的是一个字节(byte)序列。其中,英文字符占用1个字节,中文字符占用3个字节。所以得到的是1+1+3*4 = 14,是底层中字节序列占用字节的长度,而不是字符的长度。使用rune[]数组后,便可以统计出带中文字符串的字符长度。
所以,第二个功能是统计字符串的长度。
截取字符串
举个例子:截取带中文的字符串
截取Go语言这一段,字符串的底层是一个字节序列(数组),字符串的截取 左闭右开 1+1+3+3=8 下标从0开始,起始索引为0,终止索引为8(考虑到右边为开区间)。
demo
s := "Go语言编程"
fmt.Println(s[0:8])
//字符串的截取 左闭右开 1+1+3+3=8 下标从0开始
运行结果如下:
结果是对的,但是存在一个缺陷:就是每次截取时,必须先计算出需要截取的字符串的
字节索引,如果说字节数计算错误,就会出现乱码的情况。
验证一下:
s := "Go语言编程"
fmt.Println(s[0:7])
s2 := "Go语言编程"
fmt.Println(s2[0:4])
运行结果如下:
很明显,出现乱码的情况。
除此之外,假设字符串的长度非常大,通过字节的方式去截取显然不是一个高效的方法。应该是取出字符的方式去截取字符串,rune类型便可以实现这一点。其实,从刚才的len取出byte和rune数组的长度就可以知道,rune是直接操作字符,而不是像byte一样去一个个操作字节。
使用rune类型运行截取字符串运行结果如下:
所以,rune的第三个功能是截取字符串。
rune实现分析
为什么rune类型可以做到这一点?
简述:
首先,先弄清楚string、byte、rune三者之间的关系。
字符串在底层的表示是由单个字节组成的一个不可修改的字节序列,字节使用UTF-8编码标识Unicode文本。Unicode文本意味着.go文件可以包含世界上的任意语言或者字符,该文件在任意系统上打开都不会乱码。UTF-8是Unicode的一种实现方式,是一种针对Unicode可变长度的字符编码,它定义了字符串以何种方式存储在内存中。UTF-8使用1~4为每个字符编码。
Go语言把字符分为byte和rune两种类型处理,byte是uint8类型的别名,用于存放占用1个字节的ASCII字符,如英文字符,返回的是字符的原始字节。rune类型是int32类型的别名,用于存放多字节字符,如占3个字节的中文字符,返回的是字符Unicode码点值。
验证一下
说明上述的分析成立!
demo
s := "Go语言编程"
fmt.Println("byte类型: ", []byte(s))
//输出: byte类型: [71 111 232 175 173 232 168 128 231 188 150 231 168 139]
fmt.Println("rune类型: ", []rune(s))
//输出: rune类型: [71 111 35821 35328 32534 31243]
具体实现细节参考下面网址:
https://www.cnblogs.com/cheyunhua/p/16007219.html文章来源:https://www.toymoban.com/news/detail-803595.html
看到这里的小伙伴,恭喜你又掌握了一个知识点👊
希望大家能取得胜利,坚持就是胜利💪
我是寸铁!我们下期再见💕文章来源地址https://www.toymoban.com/news/detail-803595.html
到了这里,关于【Go面试向】rune和byte类型的认识与使用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
![go 语言中 json.Unmarshal([]byte(jsonbuff), &j) 字节切片得使用场景](https://imgs.yssmx.com/Uploads/2024/01/818811-1.png)