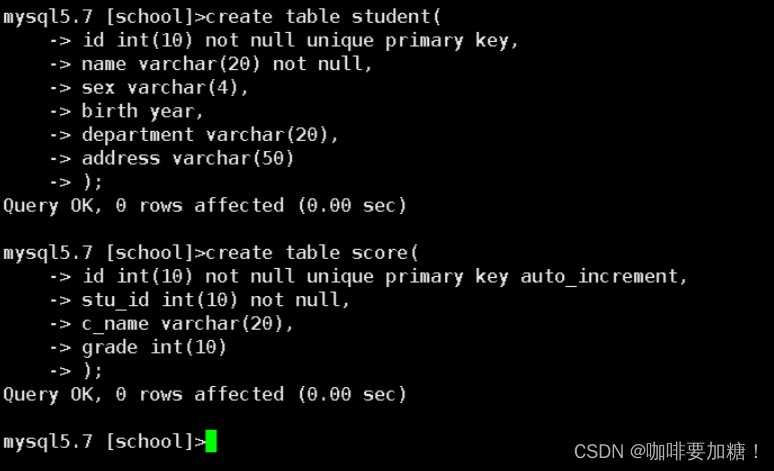
什么是窗口函数
可以像聚合函数一样对一组数据进行分析并返回结果,二者的不同之处在于,窗口函数不是将一组数据汇总成单个结果,而是为每一行数据都返回一个结果。

窗口函数组成部分
1.创建数据分区
窗口函数OVER子句中的PARTITION BY选项用于定义分区,其作用类似于查询语句中的GROUP BY子句。如果我们指定了分区选项,窗口函数将会分别针对每个分区单独进行分析。
1.另外开一列,求出每个部门的平均年龄
select *,avg(age) over(partition by dept) as 平均年龄 from testfunc order by id;

解释:另外添加一列,用于记录以分组到每个部门的窗口中,以deft为窗口分区,计算出每个部门的平均年龄
2.每位学生的总成绩
select s_id,sum(convert(score,double))as 总成绩 from sc group by s_id;

3.#以总成绩进行排名:窗口函数
dense_rank()是的排序数字是连续的、不间断。当有相同的分数时,它们的排名结果是并列的
select s_id,sum(convert(score,double))as 总成绩,
dense_rank() over(order by sum(convert(score,double))desc)as 排名
from sc group by s_id;

解释:指定总成绩为窗口分区,并且总成绩降序排序。再接着dense_rank()再一次排序
4.#每科目下的总成绩进行排名
select c_id,sum(convert(score,double))as 总成绩,
dense_rank() over(partition by c_id order by sum(convert(score,double)) desc)as 排名
from sc group by c_id;
解释:分组到c_id窗口,以总成绩的降序排列,对c_id窗口分区进行对每一行匹配,并且再一次排序
#以平均分降序排列成绩信息:
select *,avg(convert(score,double)) over(partition by s_id)as 平均成绩 from sc order by 平均成绩 desc;

#按总成绩进行降序排列
-- 若按学生总成绩进行降序排序
select *,sum(convert(score,double)) over(partition by s_id) as 总成绩 from sc order by 总成绩 desc;
-- 若按科目的总成绩进行排序
select *,sum(convert(score,double)) over(partition by c_id) as 总成绩 from sc order by 总成绩 desc;

5.-- 求每个访客每个月访问次数,和累计访问次数
select *from visitor;
select userId,month(visitDate)as 月,sum(visitCount)as 月访问次数 from visitor group by userId,月;

-- 月累计访问次数,月累计:sum(sum(visitCount))
select userId,month(visitDate)as 月,sum(visitCount)月访问次数,sum(sum(visitCount))over(partition by userId order by month(visitDate))as 该客户月累计次数
from visitor group by use9999rId,月 order by userId;

6.-- 尝试不使用窗口函数得到并列形式排名(1,2,2,4...)
select a.name ,a.subject ,max(a.score) 主成绩 ,count(b.name)+1 行统计值【排名】
from score a left join score b on a.subject =b.subject and b.score >a.score
group by a.name, a.subject order by a.subject ,主成绩 desc;
select * from books_goods;

7.-- 对同个类别【t_categor】的价格进行降序排序,并给与排名值(但是row_number()不会跳过重复序号)
select row_number() over(partition by t_category order by t_price desc)as 排名,t_category,t_name,t_price,t_upper_time
from books_goods;

8.rank() 序号函数
能够对序号进行并列排序,并且会跳过重复的序号,得到并列排名 --- 效果与 excel 中 rank.eq()类似
select rank() over(partition by t_category order by t_price desc)as 排名,t_category,t_name,t_price,t_upper_time
from books_goods;

dense_rank() 函数
DENSE_RANK()函数对序号进行并列排序,并且不会跳过重复的序号,比如序号为1、1、2。
select rank() over(partition by t_category order by t_price desc)as 排名,t_category,t_name,t_price,t_upper_time
from books_goods;

9.percent_rank() 分布函数
于计算分区或结果集中行的百分位数
percent_rank() 返回一个从0到1的数字
对于指定的行, percent_rank()计算行的等级减1,除以评估的分区或查询结果集中的行数减一
select percent_rank() over(partition by t_category order by t_price desc) as 排名百分位,
rank() over(partition by t_category order by t_price desc) as 排名,
t_category,t_name, t_price,t_upper_time
from books_goods;

即:当前的排名-1/当前的行量-1;
10.cume_dist() 分布函数
主用于查询小于或等于某个值的比例
-- 比如统计大于等于当前售价的产品数占总产品数的比例,其窗口函数中的排序为降序即可
select cume_dist() over(order by t_price desc) as 占比,
t_category,t_name, t_price,t_upper_time
from books_goods;

- 比如统计小于等于当前售价的产品数占总产品数的比例
select cume_dist() over(order by t_price asc) as 占比,
t_category,t_name, t_price,t_upper_time
from books_goods;

前后函数:lag(expr,n)/lead(expr,n)
11.现想查看统一组别中的价格差值
- 2、计算当前价格与上一个价格之间的差值
select *,t_price-pre_price as 差值 from(
#1、得到当前商品的前一个商品价格(价格先按低的排序)
select t_category_id t_category,t_name, t_price,
lag(t_price,1) over(partition by t_category order by t_price asc) as pre_price
from books_goods
) t

把over 后的窗口分组排序方式语句单独提出来,设置别名:w 【名字可自取】,同时将其可应用于多个窗口函数上
想要输出分组后的前一个价格和后一个价格
select t_category_id t_category,t_name, t_price,
lag(t_price,1) over h as pre_price ,
lead(t_price,1) over h as last_price
from books_goods
window h as (partition by t_category order by t_price asc);

12.首尾函数FIRST_VALUE(expr)/LAST_VALUE(expr)
头尾函数应用于:返回第一个或最后一个expr的值;
应用场景:截止到当前,按照日期排序查询当前最大的月收入【LAST_VALUE】 或最小月收入值【FIRST_VALUE】是多少
比如:按价格排序,查询每个类目中最低和最高的价格是多少,方便与后续计算当前书籍的价格与最大价格 或最小价格的差值(但是没有分组来返回值)
select t_category_id t_category,t_name, t_price,
first_value(t_price) over h as 最小价格 ,
last_value(t_price) over h as 最大价格
from books_goods
window h as (partition by t_category order by t_price asc );

但结果发现:last_value 的结果并没有按照我们所想的以当前分组的窗口表中的所有数据进行判断最大值的
原因:last_value默认统计范围是取当前行数据 与 当前行之前的数据做比较的
解决方案:over 中的排序 order by 条件后加上一个固定语句:rows between unbounded preceding and unbounded following ,也是前面无界 和 后面无界 之间的行比较
select t_category_id t_category,t_name, t_price,
first_value(t_price) over h as 最小价格 ,
last_value(t_price) over h as 最大价格
from books_goods
window h as (partition by t_category order by t_price asc rows between unbounded preceding and unbounded following);

13.请利用窗口函数找出每门学科的前三名【并列且连续的排名效果】
select t.* from(
select name,subject,score,dense_rank() over(partition by subject order by score desc) as 排名 from score
) t where t.排名 3;文章来源:https://www.toymoban.com/news/detail-803658.html
 文章来源地址https://www.toymoban.com/news/detail-803658.html
文章来源地址https://www.toymoban.com/news/detail-803658.html
到了这里,关于SQL-窗口函数的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!