目录
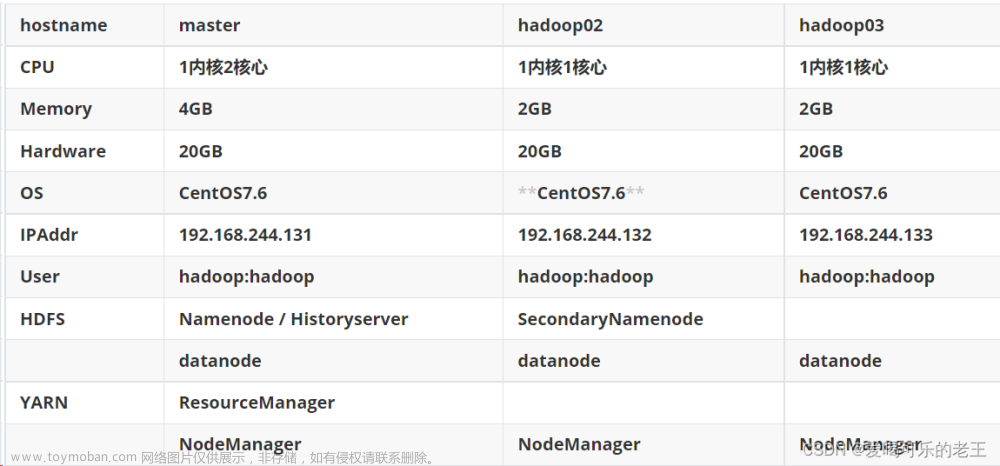
架构设计:
一、下载hadoop安装包
二、解压及构建软连接
三、 修改配置文件
1. 配置workers文件 //hadoop02中叫slaves
2. 修改hadoop-env.sh
3. 修改core-site.xml
4. 修改hdfs-site.xml
5. 配置:mapred-site.xml文件
6. 配置yarn-site.xml文件
四、根据hdfs-site.xml的配置项,准备数据目录
五、配置hadoop02和hadoop03
六、配置环境变量
七、 授权hadoop用户
八、启动集群
九、测试用例
十、关闭集群
十一、通过日志排查问题
架构设计:
一、下载hadoop安装包
1.直接使用wget命令下载
cd /export/software //安装包下载到这个目录
wget https://archive.apache.org/dist/hadoop/common/hadoop-3.3.5/hadoop-3.3.5.tar.gz2.官网自行下载
Index of /dist/hadoop/common (apache.org)https://archive.apache.org/dist/hadoop/common/下载的安装包统一放在/export/software目录中。
可通过rz上传到当前目录(需提前切换到/export/software),上传速度是几个MB/s。
也可通过FinalShell或xftp拖动到目标目录(需提前切换到/export/software),速度是几十个MB/s.很快的。
```
二、解压及构建软连接
tar -zxvf hadoop-3.3.5.tar.gz -C /export/servers
cd /export/servers
ln -s hadoop-3.3.5 hadoop
# 不推荐用mv hadoop-3.3.5 hadoop修改目录的名字
三、 修改配置文件
配置文件都在这个目录下:/export/servers/hadoop/etc/hadoop
1. 配置workers文件 //hadoop02中叫slaves
cd /export/servers/hadoop/etc/hadoop
vim workers
#删除localhost,填入如下内容,表明Datanode是哪几个
master
Hadoop02
Hadoop032. 修改hadoop-env.sh
vim hadoop-env.sh
# 在hadoop-env.sh的最上面插入以下所有内容
# 配置Java安装路径
export JAVA_HOME=/export/servers/jdk
# 配置Hadoop安装路径
export HADOOP_HOME=/export/servers/hadoop
# Hadoop hdfs 配置文件路径
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
# Hadoop YARN 配置文件路径
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
# Hadoop YARN 日志文件夹
export YARN_LOG_DIR=$HADOOP_HOME/logs/yarn
# Hadoop hdfs 日志文件夹
export HADOOP_LOG_DIR=$HADOOP_HOME/logs/hdfs
# 为防止意外,root用户默认是不让启动集群的。如下强制设置后root用户可启动集群,其他用户就不能启动集群了
#export HDFS_NAMENODE_USER=root
#export HDFS_DATANODE_USER=root
#export HDFS_SECONDARYNAMENODE_USER=root
#export YARN_RESOURCEMANAGER_USER=root
#export YARN_NODENANAGER_USER=root
#export YARN_PROXYSERVER_USER=root
```3. 修改core-site.xml
vim core-site.xml
# 把<configuration> </configuration> 替换为以下内容,粘贴后注意检查<configuration>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
<description>HDFS文件系统的网络通讯路径,应用协议为hdfs://,namenode为master,通讯端口为8020</description>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
<description>io操作文件缓冲区大小,128KB</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/export/servers/hadoop/tmp</value>
<description>临时目录</description>
</property>
</configuration>
```4. 修改hdfs-site.xml
vim hdfs-site.xml
# 把<configuration> </configuration> 替换为以下内容,粘贴后注意检查<configuration>
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop02:50090</value>
<description>SecondaryNamenode在Hadoop02上</description>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
<description>副本数量,默认3</description>
</property>
<property>
<name>dfs.datanode.data.dir.perm</name>
<value>755</value>
<description>hdfs文件系统管理文件的权限,默认755,即rwxr-xr-x所属用户拥有全部权限</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/nn</value>
<description>元数据的存储位置,在master的/data/nn目录下Path on the local filesystem where the Namenode stores the namespace and transactions logs persistently.</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/dn</value>
<description>数据存储目录,即数据存储在master,hadoop02,hadoop03的/data/dn目录中</description>
</property>
<property>
<name>dfs.namenode.hosts</name>
<value>master,hadoop02,hadoop03</value>
<description>NN允许加入集群的DN,master,hadoop02,hadoop03被允许加入。List of permitted DataNodes.</description>
</property>
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
<description>hdfs默认的块大小,256MB</description>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
<description>NN处理的并发线程数,以100个并行度处理文件系统的管理任务</description>
</property>
</configuration>
5. 配置:mapred-site.xml文件
vim mapred-site.xml
# 把<configuration> </configuration> 替换为以下内容,粘贴后注意检查<configuration>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>资源管理调度用YARN</description>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
<description>HistoryServer在master上</description>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
<description></description>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
<description></description>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
<description></description>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
<description></description>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/data/mr-history/tmp</value>
<description></description>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/data/mr-history/done</value>
<description></description>
</property>
</configuration>
6. 配置yarn-site.xml文件
vim yarn-site.xml
# 把<configuration> </configuration> 替换为以下内容,粘贴后注意检查<configuration>
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
四、根据hdfs-site.xml的配置项,准备数据目录
- 在master节点:
mkdir -p /data/nn //master的根目录下的此目录,用于存放元数据
mkdir -p /data/dn //master的根目录下的此目录,用于存放集群中的数据,以block的方式存放
- 在hadoop02和hadoop03节点:
mkdir -p /data/dn //hadoop02、03的根目录下的此目录,用于存放集群中的数据,以block的方式存放五、配置hadoop02和hadoop03
1. 在master上,切换到目录/export/servers,把hadoop-3.3.5远程拷贝到hadoop02和hadoop03上
cd /export/servers
scp -r hadoop-3.3.5/ hadoop02:`pwd`/
scp -r hadoop-3.3.5/ hadoop03:$PWD/ //多学一招:后也可用`pwd`/
2. 在hadoop02和hadoop03上,构建软链接,完成配置
cd /export/servers
ln -s hadoop-3.3.5 hadoop
# 不推荐用mv hadoop-3.3.5 hadoop修改目录的名字
六、配置环境变量
在三台服务器(master、Hadoop02、Hadoop03)上执行
vim /etc/profile
# 在底部追加如下2行内容:
export HADOOP_HOME=/export/servers/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# 使环境变量生效
source /etc/profile
# 可用hadoop version查看到hadoop的版本号了
七、 授权hadoop用户
生产中,通常是授权给普通用户使用集群,假设普通用户名和用户组为hadoop:hadoop,在三台服务器上,分别进行授权如下授权:
chown -R hadoop:hadoop /export // 把/export授权给hadoop用户
chown -R hadoop:hadoop /data // 把/data授权给hadoop用户
八、格式化namenode
# 在master上 以hadoop用户操作
su - hadoop
hdfs namenode -format
# 倒数第10行附近看到:Storage directory /data/nn has been successfully formatted. 表明namenode格式化成功
#可查看到在/data/nn目录下已经有元数据了
cd /data/nn //可看到有current目录
# 进一步,可查看到current目录下的元数据fsimage,后续用出现editlog
```八、启动集群
```
1. hadoop用户在master上执行
start-dfs.sh //启动HDFS,为防止意外,默认是不让用root启动集群的,强行设置后root用户也可启动集群,详见hadoop-env.sh最下面被注释的部分
```
在master、hadoop02和hadoop03上,检查hadoop进程是否启动
```
jps
# 在master上可看到如下进程
namenode
datanode
# 在hadoop02上可看到如下进程
secondarynamenode
datanode
# 在hadoop03上可看到如下进程
datanode
```
2. 在master上,启动YANR 并检查进程(jps)
start-yarn.sh //启动YANR# 在master上可看到如下进程
ResourceManager
NodeManager
# 在hadoop02上可看到如下进程
NodeManager
# 在hadoop03上可看到如下进程
NodeManager
```
3. 在master上,启动HistoryServer,并检查是否启动
mapred --daemon start historyserver
# 在master上可看到如下进程
JobHistoryServer
4. 集群的Web UI界面管理
在宿主机的浏览器地址栏输入
master:8088 可查看Yarn的运行情况
master:9870 可查看HDFS的运行情况
九、测试用例
测试hadoop能否正常使用
1.pi
# 切换目录
cd /export/servers/hadoop/share/hadoop/mapreduce
# 执行下述内容,显示结果Estimated value of Pi is 3.144000
hadoop jar hadoop-mapreduce-examples-3.3.5.jar pi 20 100
2. 词频统计wordcount
cd /export/data
vim words.txt //在本地/export/data创建文件words.txt,内容为三行文本
Hadoop is the forerunner;
Spark is the famous star;
Flink is the future star;
#在集群上创建目录/wordcount/input
hdfs dfs -mkdir -p /wordcount/input
# 把文件words.txt从本地上传到集群的/wordcount/input目录
hdfs dfs -put words.txt /wordcount/input
# 执行下述命令,在集群上分析文件words.txt中各个单词出现的次数
hadoop jar /export/servers/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.5.jar wordcount /wordcount/input/words.txt /wordcount/output
#系统自带的MapReduce程序wordcount运行后的结果保存在集群的/wordcount/output目录中
# 执行下述命令,在集群上察看分析结果
hdfs dfs -cat /wordcount/output/part-r-00000# 结果如下:
Flink 1
Hadoop 1
Spark 1
famous 1
forerunner; 1
future 1
is 3
star; 2
the 3
#把分析结果文件下载到本地/export/data目录中
hdfs dfs -get /wordcount/output/part-r-00000 /export/data
#在本地查看结果文件
vim part-r-00000也可在集群的WEB UI中查看 (master:9870 )
十、关闭集群
stop-dfs.sh //关闭hdfs,之后用jps查看,Namenode和Datanode消失
stop-yarn.sh //关闭yarn,之后用jps查看,ResouceManager和NodeManager消失
mapred --daemon stop historyserver //关闭historyserver,之后用jps查看,Historyserver消失
hadoop集群安装完成,打好快照,为后续学习做好准备文章来源:https://www.toymoban.com/news/detail-803698.html
十一、通过日志排查问题
cd /export/servers/hadoop/logs
tail -10 a.log //查看日志文件a.log的后10行,通常能查出问题所在
文章来源地址https://www.toymoban.com/news/detail-803698.html
到了这里,关于基于Linux环境下搭建Hadoop3.3.5伪分布式集群的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!