数据库设计优化是整个数据库系统性能优化的关键一环,直接影响到数据库系统的稳定性、可扩展性和性能。
一、规范化与反规范化
数据库设计中的规范化和反规范化是为了在满足特定需求的同时,提高数据库的性能和维护效率。这两个概念之间存在权衡,需要根据具体的业务场景和查询模式做出适当的选择。
1. 规范化
规范化是通过设计合理的数据库表结构,以减少数据冗余、提高数据一致性的过程。规范化的目标是消除插入、更新、删除操作中的异常,确保数据存储的一致性和完整性。
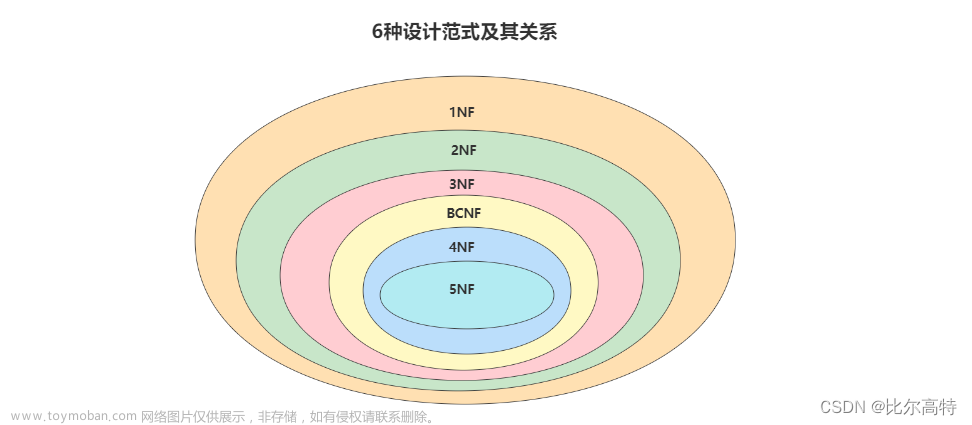
规范化的常用范式:
-
第一范式(1NF):
- 确保每个表中的每一列都是原子的,不可再分。
-
第二范式(2NF):
- 在1NF的基础上,消除部分依赖,确保非主键列完全依赖于主键。
-
第三范式(3NF):
- 在2NF的基础上,消除传递依赖,确保非主键列不依赖于其他非主键列。
优势:
- 数据一致性高,避免了插入、更新、删除异常。
- 存储空间利用率较高。
缺点:
- 复杂查询可能需要多次关联表,影响性能。
- 对于大量查询但少量更新的场景,过多的关联可能会降低性能。
2. 反规范化
反规范化是为了提高数据库的查询性能,通过增加冗余数据或合并表,减少表的连接操作。反规范化的目标是通过牺牲一定的数据冗余来提高查询效率。
常见反规范化手段:
- 冗余数据: 在需要频繁查询的字段上增加冗余,避免连接操作。
- 合并表: 将关联度较高的表合并,减少连接操作。
优势:
- 查询性能提高,减少了表连接的开销。
- 简化复杂查询,提高系统响应速度。
缺点:
- 数据冗余增加,导致更新操作可能不一致。
- 维护成本较高,需要保证冗余数据的一致性。
3. 权衡和实际应用
在实际应用中,规范化与反规范化需要根据具体业务需求和查询模式做出权衡。常见的做法是在设计阶段根据规范化的原则进行初始设计,然后根据实际查询性能的需求进行反规范化的调整。
-
频繁读取的字段: 对于需要频繁读取的字段,可以考虑反规范化,减少连接操作,提高查询性能。
-
经常更新的字段: 对于经常更新的字段,要小心反规范化,避免因为数据冗余导致更新异常。
-
数据库引擎和缓存的影响: 不同的数据库引擎对规范化和反规范化的适应性有所不同,而缓存的使用也可能对查询性能产生重要影响。
二、索引优化
索引是数据库中一种用于提高查询速度的数据结构,通过创建索引,可以加快数据检索的速度,减少系统的IO开销。然而,不恰当的索引设计可能会导致性能问题,因此需要谨慎进行索引优化。
1. 索引的基本概念
-
索引类型:
- 聚簇索引: 数据行的物理顺序与索引顺序一致,主键通常会被自动创建为聚簇索引。
- 非聚簇索引: 数据行的物理顺序与索引顺序不一致,常用于非主键列的索引。
-
单列索引和多列索引:
- 单列索引: 基于单个列的索引。
- 多列索引: 基于多个列的联合索引。
2. 索引的优势
-
加速数据检索: 通过索引,数据库引擎可以快速定位到符合查询条件的数据行,加速查询速度。
-
提高排序性能: 如果查询涉及到排序,通过索引的帮助,排序操作可以更加迅速。
-
加速连接操作: 在连接操作中,通过索引可以加速关联表的数据检索,提高连接操作的效率。
3. 索引的劣势
-
占用存储空间: 索引需要占用一定的存储空间,过多的索引可能导致存储开销较大。
-
影响写操作性能: 对表进行插入、更新和删除操作时,索引也需要进行维护,可能导致写操作性能下降。
-
过多的索引可能降低性能: 当索引数量过多时,查询优化器在选择合适的索引时可能变得更加复杂,从而降低查询性能。
4. 索引优化策略
a. 分析查询需求
- 了解查询模式: 分析常用的查询模式,确定哪些列经常用于过滤、排序和连接操作。
b. 创建合适的索引
-
主键和唯一约束: 主键自动创建聚簇索引,唯一约束创建非聚簇索引,因此在设计表结构时要充分考虑主键和唯一约束的使用。
-
频繁查询的列: 针对经常用于过滤条件的列创建索引,以提高查询性能。
-
经常用于连接的列: 在涉及连接操作的表的连接列上创建索引,提高连接操作效率。
-
频繁排序的列: 针对常用于排序的列创建索引,加速排序操作。
c. 避免过多的索引
-
综合考虑索引数量: 避免过多的索引,对于一些特别小的表,过多的索引可能不划算。
-
联合索引的使用: 尽量使用联合索引代替多个单列索引,减少索引数量。
d. 定期维护索引
-
索引重建和重新组织: 定期执行索引的重建和重新组织操作,以消除索引碎片,维护索引的性能。
-
监控索引的使用情况: 根据实际使用情况,调整和删除不再需要的索引。
e. 使用覆盖索引
- 覆盖索引: 确保查询语句所需的字段都包含在索引中,避免不必要的访问表数据,提高查询性能。
5. 索引的适用场景
-
大表: 在大表上使用索引,可以显著提高查询性能。
-
频繁查询的列: 针对经常用于过滤、排序和连接操作的列创建索引。
-
连接操作: 在涉及连接操作的表的连接列上创建索引,加速连接操作。
-
排序: 针对常用于排序的列创建索引,提高排序操作效率。
三、分区表
分区表是将一个大表按照某种规则划分成多个子表,每个子表称为一个分区。分区表的设计旨在提高查询性能、维护效率以及存储管理的灵活性。
1. 为什么使用分区表?
-
提高查询性能: 分区表可以将大表的数据分割成小块,减少查询时需要扫描的数据量,从而提高查询性能。
-
便于维护: 对于大表的维护操作,如备份、恢复、数据迁移等,分区表可以分别处理每个分区,简化维护操作。
-
灵活的存储管理: 不同分区可以采用不同的存储参数,如存储引擎、表空间等,灵活适应不同存储需求。
-
支持滚动数据删除: 可以通过按时间或其他规则划分分区,便于定期删除旧数据,保持表的合理大小。
2. 分区表的基本概念
-
分区键: 用于将表数据划分成不同分区的列,可以选择日期、范围、列表等作为分区键。
-
分区类型:
- 范围分区: 根据某个范围划分分区,如根据日期范围。
- 列表分区: 根据一个离散的值列表进行分区。
- 哈希分区: 根据某列的哈希值进行分区。
- 复合分区: 同时使用多个分区键进行分区。
3. 分区表的设计原则
a. 选择合适的分区键
-
数据分布均匀: 选择的分区键应当使数据在各分区之间分布均匀,避免某个分区过大而导致性能问题。
-
符合查询模式: 分区键的选择应符合实际查询需求,使得查询可以快速定位到目标分区。
b. 控制分区数量
-
分区数量: 控制分区的数量,避免过多的分区导致管理复杂,过少的分区可能无法充分发挥性能优势。
-
定期评估和调整: 根据数据的增长趋势和查询需求,定期评估分区数量的合理性,进行必要的调整。
c. 利用子分区
-
子分区: 对每个分区进行二次划分,可以更精细地管理数据。子分区可以是范围分区、哈希分区等。
-
灵活的管理: 子分区的使用可以根据实际情况进行动态调整,以满足特定查询或维护的需求。
4. 分区表的适用场景
-
大表的数据管理: 面对数据量庞大的表,使用分区表可以更高效地管理数据。
-
按时间范围查询: 当表的数据按照时间进行划分,而查询通常以时间范围为条件时,分区表效果显著。
-
定期维护操作: 对于需要定期备份、删除旧数据等操作的表,分区表可以简化维护工作。
-
表的数据增长趋势不均匀: 如果某个表的数据增长趋势在不同的列之间不均匀,分区表可以更好地适应这种情况。
5. 分区表的注意事项
-
数据均匀性: 分区键的选择需要确保数据在各个分区之间分布均匀,避免出现热点分区。
-
查询性能: 尽管分区表可以提高查询性能,但不是所有查询都能从中获益。在设计时要考虑实际查询模式。
-
分区数量: 过多或过少的分区数量都可能导致性能问题,需要根据具体情况选择适当的分区数量。
-
维护成本: 分区表的管理相对复杂,需要定期评估和调整分区策略,维护成本较高。文章来源:https://www.toymoban.com/news/detail-803711.html
数据库设计优化需要在规范化和性能之间取得平衡。精心设计的表结构和适当的索引、分区策略是提高数据库性能和管理效率的关键。不同的业务需求和数据特点需要综合考虑,以达到数据库设计的最佳状态。文章来源地址https://www.toymoban.com/news/detail-803711.html
到了这里,关于数据库优化系列教程(3)一数据库设计的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!