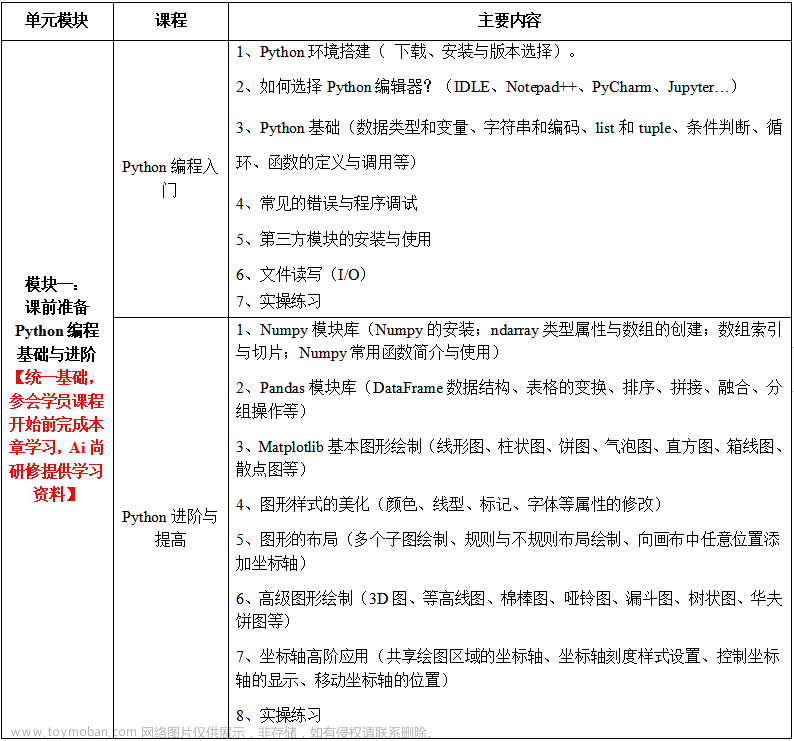
首先,读取数据集,该数据集是UCI上的心脏病患者数据集,其中包含了 303 条患者信息,每一名患者有 13 个字段记录其基本信息(年龄、性别等)和身体健康信息(心率、血糖等),此外有一个类变量记录其是否患有心脏病。详细的字段信息可见 此处。
类别字段target有两个取值,代表预测类别,1 = 患病,2 = 不患病。

文章来源:https://www.toymoban.com/news/detail-803911.html
2.训练/测试集划分
对数据集进行划分,设置划分比例为训练集 : 测试集 = 4 : 1。
由于数据集的同一类标签集中在一起,我们选择分组抽样选项,依据target字段进行分组,合理划分数据集。

3.构建K近邻心脏病患者分类模型
构建K近邻分类模型,将target作为我们的标签列,其余各字段均作为模型的特征列。选择计算的邻居个数为8,权重计算方式为distance,以及设置距离计算方式为manhattan距离(街区距离)。
参数列表
| 参数名称 | 参数取值 |
|---|---|
| 邻居数 | 8 |
| 权重计算方式 | distance |
| 距离计算方式 | manhattan |
4.Z-Score标准化
对age、trestbps、chol、thalach、oldpeak进行标准化处理,将不同量级的数据转化为统一量度,提高数据可比性。
| age | sex | cp | trestbps | chol | fbs | restecg | thalach | exang | oldpeak | slope | ca | thal | target |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1.350138 | 1 | 2 | 1.129702 | -0.622046 | 0 | 0 | 0.008235 | 0 | -0.196701 | 1 | 0 | 3 | 0 |
| -0.174618 | 1 | 2 | -0.128305 | 0.023539 | 1 | 0 | 1.004711 | 0 | -0.890351 | 2 | 3 | 2 | 1 |
| 0.696671 | 1 | 3 | 0.100423 | -0.204315 | 0 | 1 | -0.20839 | 0 | 1.364011 | 1 | 2 | 2 | 0 |
| -1.045907 | 1 | 1 | -0.24267 | 1.200782 | 0 | 0 | 0.874736 | 0 | -0.890351 | 2 | 0 | 2 | 1 |
| -0.501351 | 1 | 0 | 0.672245 | -0.8499 | 0 | 0 | -1.031565 | 1 | -0.109995 | 1 | 0 | 3 | 0 |
| 特征 | 均值 | 标准差 |
|---|---|---|
| age | 54.603306 | 9.1818 |
| trestbps | 132.243802 | 17.487967 |
| chol | 244.760331 | 52.665406 |
| thalach | 149.809917 | 23.081356 |
| oldpeak | 1.02686 | 1.15332 |
5.各字段基本统计信息
读取数据表后,对各个数据字段统计基本信息,包括样本数量、均值、标准差、最大最小值和上下四分位数等。
可以看出,读取的数据表均为数值型字段。从这里可以发现,各字段的样本数均为 303 ,说明无缺失值;此外。许多字段如sex、cp、fbs、restecg、exang、slope、ca和thal,其上下四分位数、中位数和最大最小值的取值有很大的重复,结合数据集详情页的统计信息,说明其为离散型数值字段;其余字段如age、trestbps等为连续型变量,在后期可以进行标准化处理。
| age | sex | cp | trestbps | chol | fbs | restecg | thalach | exang | oldpeak | slope | ca | thal | target | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 样本数 | 303 | 303 | 303 | 303 | 303 | 303 | 303 | 303 | 303 | 303 | 303 | 303 | 303 | 303 |
| 均值 | 54.3663366337 | 0.6831683168 | 0.9669966997 | 131.6237623762 | 246.2640264026 | 0.1485148515 | 0.5280528053 | 149.6468646865 | 0.3267326733 | 1.0396039604 | 1.399339934 | 0.7293729373 | 2.3135313531 | 0.5445544554 |
| 标准差 | 9.0821009898 | 0.4660108233 | 1.0320524895 | 17.5381428135 | 51.8307509879 | 0.3561978749 | 0.5258595964 | 22.9051611149 | 0.4697944645 | 1.1610750221 | 0.6162261453 | 1.022606365 | 0.6122765073 | 0.4988347842 |
| 最小值 | 29 | 0 | 0 | 94 | 126 | 0 | 0 | 71 | 0 | 0 | 0 | 0 | 0 | 0 |
| 下四分位数 | 47.5 | 0 | 0 | 120 | 211 | 0 | 0 | 133.5 | 0 | 0 | 1 | 0 | 2 | 0 |
| 中位数 | 55 | 1 | 1 | 130 | 240 | 0 | 1 | 153 | 0 | 0.8 | 1 | 0 | 2 | 1 |
| 上四分位数 | 61 | 1 | 2 | 140 | 274.5 | 0 | 1 | 166 | 1 | 1.6 | 2 | 1 | 3 | 1 |
| 最大值 | 77 | 1 | 3 | 200 | 564 | 1 | 2 | 202 | 1 | 6.2 | 2 | 4 | 3 | 1 |
6.年龄分布直方图
选取age字段画出直方图。可以看出,大多数患者年龄在38岁以上,说明心脏病的主要患病人群是中老年人。


选取target字段画出饼图,可以看出,该数据集中患有心脏病的人群比例较高,但两个类别的样本数量相差不大。

对K近邻模型进行评估。使用的方法主要为分类报告、混淆矩阵和ROC曲线。
可以看到,我们构建的K近邻模型的分类性能较为良好,总体分类正确率(accuracy)达到0.87,macor avg F1-score能达到0.87,正类样本的召回率(Recall)能达到0.94,ROC_AUC值为0.88。
分类报告(classification report)
| 标签 | 精确率(Precision) | 召回率(Recall) | F1值(F1-score) |
|---|---|---|---|
| 0 | 0.92 | 0.79 | 0.85 |
| 1 | 0.84 | 0.94 | 0.89 |
| accuracy | 0.87 | 0.87 | 0.87 |
| macro avg | 0.88 | 0.86 | 0.87 |
| weighted avg | 0.87 | 0.87 | 0.87 |
混淆矩阵(confusion matrix)

 文章来源地址https://www.toymoban.com/news/detail-803911.html
文章来源地址https://www.toymoban.com/news/detail-803911.html
到了这里,关于基于数据挖掘机器学习的心脏病患者分类建模与分析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!