SQL中的几个区别
1:几种JOIN连接方式的区别?
2:几种排序窗口函数的区别?
3:on和where的区别?
4:having和where的区别?
5:union和union all的区别?
6:in和exists的区别?
7:数据库中空字符串、0和NULL的区别?
8:count(1)、count(*)和count(列名)的区别?
1- 几种JOIN连接方式的区别?
-
INNER JOIN(内连接):
- 描述: 返回两个表中共有的行,即满足连接条件的行。
- 区别: 只包括两个表中共有的数据。
SELECT * FROM table1 INNER JOIN table2 ON table1.column = table2.column;
-
LEFT JOIN(左连接):
- 描述: 返回左表中的所有行,以及右表中匹配的行。
- 区别: 如果右表中没有匹配的行,结果中将包含 NULL 值。
SELECT * FROM table1 LEFT JOIN table2 ON table1.column = table2.column;
-
RIGHT JOIN(右连接):
- 描述: 返回右表中的所有行,以及左表中匹配的行。
- 区别: 如果左表中没有匹配的行,结果中将包含 NULL 值。
SELECT * FROM table1 RIGHT JOIN table2 ON table1.column = table2.column;
-
FULL JOIN(全连接):
- 描述: 返回左表和右表中的所有行,如果没有匹配的行,将包含 NULL 值。
- 区别: 结果集包括两个表的所有数据。
SELECT * FROM table1 FULL JOIN table2 ON table1.column = table2.column;
这些连接方式允许你在多个表之间建立关联,根据特定条件检索相关的数据。
更详细内容可参考: SQL中几种JOIN关系
SQL中几种JOIN关系: https://blog.csdn.net/Taerge0110/article/details/134822620?spm=1001.2014.3001.5502
2- 几种排序窗口函数的区别?
在 SQL 中,排序窗口函数用于对查询结果进行排序和分析。以下是几种常见的排序窗口函数及其区别:
-
ROW_NUMBER():
- 描述: 为结果集中的每一行分配一个唯一的整数值,通常用于给结果集中的行编号。
- 区别: 不考虑重复值,每行都有唯一的编号。
SELECT ROW_NUMBER() OVER (ORDER BY column_name) AS row_num, other_columns FROM table_name;
-
RANK():
- 描述: 分配排名,相同数值的行将获得相同的排名,并在下一个排名后跳过相应数量的排名。
- 区别: 有相同数值的行将获得相同排名,但下一个排名将跳过相应数量的排名。
SELECT RANK() OVER (ORDER BY column_name) AS rank, other_columns FROM table_name;
-
DENSE_RANK():
- 描述: 类似于 RANK(),但不会跳过相应数量的排名。
- 区别: 有相同数值的行将获得相同排名,但下一个排名不会跳过相应数量的排名。
SELECT DENSE_RANK() OVER (ORDER BY column_name) AS dense_rank, other_columns FROM table_name;
-
NTILE():
- 描述: 将结果集划分为指定数量的桶,并为每个行分配一个桶编号。
- 区别: 用于分割结果集,每个桶包含相等数量的行。
SELECT NTILE(number_of_buckets) OVER (ORDER BY column_name) AS bucket, other_columns FROM table_name;
这些排序窗口函数可根据不同的需求和情境选择使用。
3- on和where的区别?
在SQL中,ON和WHERE都是用于筛选数据的关键字,但它们在用途和应用场景上有一些区别。
-
ON:
- 通常用于
JOIN操作,连接两个表时使用。 - 指定用于匹配两个表之间行的条件。
- 在
FROM子句中的JOIN操作中,ON后面跟随连接条件,用于确定两个表之间如何进行关联。
示例:
SELECT * FROM table1 INNER JOIN table2 ON table1.column = table2.column; - 通常用于
-
WHERE:
- 用于过滤从单个表中选择的行。
- 在
SELECT语句中,WHERE后面跟随条件,用于筛选满足条件的行。 - 不限于连接操作,可以在任何需要筛选数据的地方使用。
示例:
SELECT * FROM table WHERE column = 'value';
总的来说,ON用于连接操作,而WHERE用于过滤行。在执行JOIN时,ON指定连接条件;而在其他情况下,使用WHERE来定义筛选条件。
4- having和where的区别?
在SQL中,HAVING和WHERE都是用于筛选数据的关键字,但它们在用途和应用场景上有一些区别。
-
WHERE子句:
- 用于过滤从单个表中选择的行。
- 在
SELECT语句中,WHERE后面跟随条件,用于筛选满足条件的行。 - 主要用于过滤行级别的条件,例如对列值的比较。
- 出现位置,可以用增、删、改、查任何语句中。
- SQL会在分组之前执行where语句,where语句在group by语句之前执行。
示例:
SELECT * FROM table WHERE column = 'value'; -
HAVING子句:
- 用于过滤聚合函数的结果。
- 在包含聚合函数(如
SUM、COUNT、AVG等)的SELECT语句中,HAVING后面跟随条件,用于筛选满足条件的聚合结果。 - 主要用于过滤分组后的数据,通常与
GROUP BY一起使用。 - 出现位置,只能用于查询select语句中
- SQL会在分组之后执行having语句,having语句在group by语句之后执行。
示例:
SELECT column, COUNT(*) FROM table GROUP BY column HAVING COUNT(*) > 10;
总的来说,WHERE用于过滤行级别的条件,而HAVING用于过滤分组后的聚合结果。HAVING通常用于对聚合函数的结果进行条件过滤,而WHERE用于普通的行级别条件过滤。
5- union和union all的区别?
在SQL中,UNION和UNION ALL是用于合并两个或多个查询结果集的操作符,它们之间有一些主要的区别:
-
删除重复行:
UNION会删除合并结果集中的重复行,只保留唯一的行。而UNION ALL则保留所有行,包括重复的行。 -
性能:由于
UNION会删除重复行,所以在处理大数据量时,使用UNION ALL通常会有更好的性能,因为它不需要进行重复行的删除操作。 -
结果集排序:使用
UNION时,合并的结果集中的列会按照第一个查询的顺序进行排序。而使用UNION ALL时,结果集中的列通常会按照它们在结果集中出现的顺序进行排序,除非在查询中使用了特定的排序规则。 -
使用场景:通常,如果你知道结果集中不会有重复行,或者你希望保留所有行,那么应该使用
UNION ALL。如果你需要合并的结果集中有重复行,并且你希望删除重复行并按照一定的顺序排列结果集,那么应该使用UNION。
请注意,在使用UNION或UNION ALL时,查询中的列必须具有相同的类型和数量,并且不能有NULL值。否则,查询将无法执行。
6- in和exists的区别?
在 SQL 中,IN 和 EXISTS 是两种用于过滤数据的不同方式。
-
IN运算符:-
使用
IN运算符时,你可以指定一个值列表,然后检查某个列是否包含在该值列表中。 -
例如,以下是一个使用
IN的示例:SELECT column_name FROM table_name WHERE column_name IN (value1, value2, ...); -
查询会返回包含在值列表中的列值。
-
-
EXISTS子查询:-
EXISTS是一个用于检查子查询结果是否存在的关键字。 -
通常,
EXISTS与子查询一起使用,如果子查询返回结果集,主查询就会执行。 -
例如,以下是一个使用
EXISTS的示例:SELECT column_name FROM table_name WHERE EXISTS (SELECT 1 FROM another_table WHERE condition); -
查询会返回符合子查询条件的行。
-
主要区别:
-
IN用于比较某一列与一个值列表,而EXISTS用于检查子查询的结果是否存在。 -
IN适用于静态值列表,而EXISTS更适用于动态条件和子查询。 - 通常情况下,
IN的性能可能会受到值列表长度的影响,而EXISTS的性能通常较为稳定,因为它只关心子查询是否返回结果。
选择使用哪种方式取决于具体的需求和数据结构。
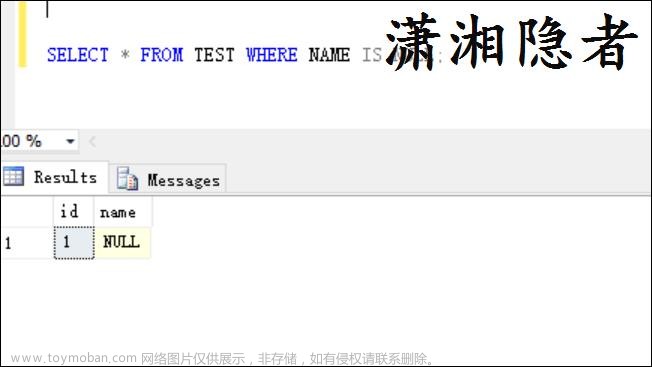
7- 数据库中空字符串、0和NULL的区别?
在数据库中,空字符串(Empty String)、0和NULL有着不同的含义和用途:
-
空字符串(Empty String):
- 表示一个字符串对象,但其内容为空。这是一个有效的字符串,只是它的长度为零。
- 在某些情况下,空字符串可能被视为具有值的字符串,因为它占用了存储空间。
-
0:
- 代表数值型数据中的零,通常用于整数或浮点数字段。
- 与空字符串不同,0是一个数值,具有明确的数学意义。
-
NULL:文章来源:https://www.toymoban.com/news/detail-804143.html
- 表示缺少或未定义的值,不属于任何数据类型。
- 在数据库中,NULL表示一个字段没有被赋予具体的值。
- 与空字符串和0不同,NULL不是一个具体的数值或字符串,而是表示缺失或未知。
- 在排序中,NULL比空字符串优先排序。
- 对于聚合(累计)函数,如COUNT()、MIN()和SUM(),将忽略NULL值。
总体来说,空字符串是一个具有零长度的有效字符串,0是一个具体的数值,而NULL表示缺失或未定义的值。在数据库设计中,理解和正确处理这些差异对于确保数据的准确性和完整性非常重要。文章来源地址https://www.toymoban.com/news/detail-804143.html
8- count(1)、count(*)和count(列名)的区别?
-
执行效果:
- count(1): 忽略所有列, 用1代表代码行, 在统计结果时, 不忽略NULL值.
- count(*): 考虑所有的列, 相当于行数, 在统计结果时, 不忽略NULL值.
- count(列名): 只考虑列名那一列, 在统计结果的时候, 会忽略NULL值.
-
执行效率:
- 如果数据表没有主键, count(1) 比 count(*) 快.
- 如果数据表有主键, 主键作为count的条件比 count(*) 快.
- 如果数据表里只有一个字段, count(*) 是最快的.
- 列名为主键, count(列名)比count(1)快; 列名不为主键, count(1)比count(列名) 快.
end
到了这里,关于SQL中的几个区别的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!