上一篇大数据文章讲解了在单机上搭建Hadoop-Yarn 伪分布式集群的安装方法,方便大家学习,真实环境不可能只有一台机器,肯定是多节点的集群,大单位还会建设很多Hadoop集群,比如各个大部门有自己的集群,或者按热、温、冷来划分建立集群,反正都是很多台服务器安装Linux系统来搭建一个集群。
1. 准备安装包
安装Java环境:需要JDK8以及以上版本。
从Hadoop官网下载安装包,当前使用的是hadoop-2.10.0。
下载地址:https://archive.apache.org/dist/hadoop/common/hadoop-2.10.0/, 下载得到:hadoop-2.10.0.tar.gz。
2. 安装
* 2.1 系统软硬件环境安装
先规划好硬件服务器,至少3台以上,形成一个集群。
首先安装好Linux系统,并在每台机器上安装好Java JDK环境。
本例是安装到/opt/bigdata/jdk1.8.0_144目录,下面配置环境变量时要一致。
通常,集群中的一台机器被指定为NameNode,另一台机器被指定为ResourceManager。它们是master节点。
集群中的其余机器同时充当DataNode和NodeManager, 它们是slave节点。
注意:我建立的HadoopYarn集群主要是用来执行Spark和Flink Job的,并不是用hdfs来存储海量数据的,
hdfs只是用来支持Spark和Flink的jar文件分发的,所以为节省机器资源,我们把NameNode和ResourceManager部署在同一个节点,
而DataNode和NodeManager也在多个slave节点同时部署,当然DataNode可以少启动一点。
如果你需要用hdfs来存储真正的大数据,则节点规划肯定不同。
本案例采用四台服务器来搭建集群:
192.168.1.1
192.168.1.2
192.168.1.3
192.168.1.4
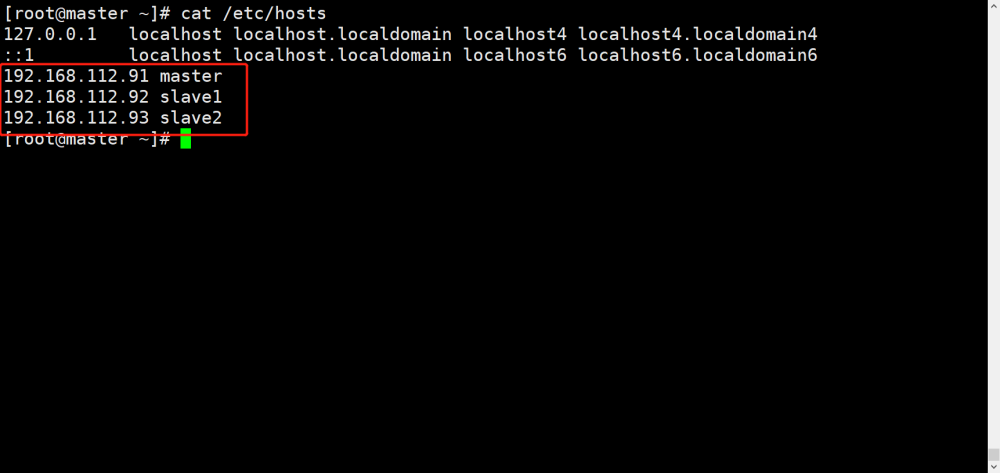
在每一台机器上都设置hosts:
vi /etc/hosts
添加四条记录:
192.168.1.1 hadoop1
192.168.1.2 hadoop2
192.168.1.2 hadoop-master
192.168.1.3 hadoop3
192.168.1.4 hadoop4
当然,建议直接在CoreDNS一次性配置更方便,每台机器/etc/resolv.conf上配置:
nameserver <CoreDNS IP>
本安装例子做如下规划,特别注意master和slave域名和IP配置:
master节点为: hadoop2, hadoop-master
slave节点为:hadoop1、hadoop3、hadoop4、也可以把hadoop2同时作为slave节点(请从实际资源情况和集群稳定性情况考虑)
下面配置环境变量和配置文件时,会使用到这些域名。
然后把Hadoop安装包上传到所有Linux服务器,创建安装目录:
mkdir /opt/bigdata
把hadoop-2.10.0.tar.gz放到/opt/bigdata目录下,解压:
tar zxvf hadoop-2.10.0.tar.gz
则/opt/bigdata/hadoop-2.10.0是安装目录,下面配置时会使用到,要保持一致。
* 2.2 创建子目录
在所有节点上,创建需要的子目录:
cd hadoop-2.10.0/
mkdir -p dfs/data dfs/name
mkdir -p logs/hdfs logs/yarn
mkdir -p tmp/hdfs tmp/yarn
当然,你也可以把dfs,logs,tmp软链接到数据分区,防止/分区磁盘满。
3. 设置环境变量
在所有节点上设置环境变量.
vi ~/.profile, 添加:
# 假设jdk安装在/opt/bigdata/目录下, 自己安装实际情况配置线上路径
export JAVA_HOME=/opt/bigdata/jdk1.8.0_144
export HADOOP_PREFIX=/opt/bigdata/hadoop-2.10.0
export HADOOP_HOME=$HADOOP_PREFIX
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_YARN_HOME=/opt/bigdata/hadoop-2.10.0
export YARN_CONF_DIR=$HADOOP_YARN_HOME/etc/hadoop
export PATH=$JAVA_HOME/bin:$PATH:$HADOOP_HOME/bin
export HADOOP_CLASSPATH=`hadoop classpath`
使其生效,执行: . ~/.profile
4. 配置
所有配置文件和环境脚本文件到放到etc/hadoop/目录下, 进入配置目录:
cd hadoop-2.10.0/etc/hadoop/
这里配置文件很多,但只要修改4个.xml配置文件和2个.sh脚本文件, 以及slaves:
core-site.xml
hdfs-site.xml
yarn-site.xml
capacity-scheduler.xml
hadoop-env.sh
yarn-env.sh
slaves
因为默认的模板文件基本是空的,需要我们根据官网文档和实际安装情况来配置,为了降低部署难度,
特提供测试环境使用的6个文件,我们在线上部署时,在提供的文件基础上进行修改就比较简单了。
我们在这6个模板文件基础之上,按实际情况进行修改,具体修改方法如下章节所述。
* 4.1 hadoop-env.sh
主要把以下配置项的路径,按实际情况进行配置:
JAVA_HOME=/opt/bigdata/jdk1.8.0_144
export HADOOP_PREFIX=/opt/bigdata/hadoop-2.10.0
export HADOOP_HOME=$HADOOP_PREFIX
export HADOOP_YARN_HOME=/opt/bigdata/hadoop-2.10.0
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_LOG_DIR=${HADOOP_HOME}/logs/hdfs
一般上面没有改动的话,直接用提供的hadoop-env.sh覆盖etc/hadoop下的文件即可。
注意以上配置必须正确,当我们执行批量启动时,可能出现找不到路径现象,就是配置没有生效。
不知道为什么env环境变量里的不能读取到,必须在本文件里设置死,郁闷。
* 4.2 yarn-env.sh
主要把以下配置项的路径,按实际情况进行配置:
这里假设运行yarn集群用的是用户test来执行的,如果是不一样的用户名则改之。
HADOOP_YARN_USER=test
export JAVA_HOME=/opt/bigdata/jdk1.8.0_144
YARN_CONF_DIR=$HADOOP_YARN_HOME/etc/hadoop
YARN_LOG_DIR="$HADOOP_YARN_HOME/logs/yarn"
* 4.3 core-site.xml
主要修改两项:
安装路径要填写实际的目录,如: /opt/bigdata/hadoop-2.10.0
<property>
<name>hadoop.home</name>
<value>/opt/bigdata/hadoop-2.10.0</value>
</property>
修改hdfs的IP和端口。
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop-master:9900</value>
</property>
* 4.4 hdfs-site.xml
主要修改两项:
安装路径要填写实际的目录,如: /opt/bigdata/hadoop-2.10.0
<property>
<name>hadoop.home</name>
<value>/opt/bigdata/hadoop-2.10.0</value>
</property>
修改master节点域名 hadoop-master: (在每台服务器上已经配置/etc/hosts或CoreDNS里配置, 参见1.1节)
<property>
<name>dfs.http.address</name>
<value>hadoop-master:50070</value>
<description> hdfs namenode web ui 地址 </description>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>hadoop-master:50090</value>
<description> hdfs scondary web ui 地址 </description>
</property>
* 4.5 yarn-site.xml
安装路径要填写实际的目录,如: /opt/bigdata/hadoop-2.10.0
<property>
<name>hadoop.home</name>
<value>/opt/bigdata/hadoop-2.10.0</value>
</property>
修改master节点地址: hadoop-master, (在每台服务器上已经配置/etc/hosts或CoreDNS里配置, 参见1.1节)
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop-master</value>
</property>
下面5项的端口号,如果有被其它程序服务所占用,就修改一下,不然不要改动:
<property>
<name>yarn.resourcemanager.address</name>
<value>${yarn.resourcemanager.hostname}:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>${yarn.resourcemanager.hostname}:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>${yarn.resourcemanager.hostname}:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>${yarn.resourcemanager.hostname}:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>${yarn.resourcemanager.hostname}:8088</value>
</property>
任务资源调度策略:1) CapacityScheduler: 按队列调度;2) FairScheduler: 平均分配。
很重要的配置,一定要理解原理, 然后你自己来选择启动哪一种策略。
<property>
<description>The class to use as the resource scheduler.</description>
<name>yarn.resourcemanager.scheduler.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
<!-- <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
-->
</property>
分配给AM单个容器可申请的最小内存: MB
<property>
<description>The minimum allocation for every container request at the RM
in MBs. Memory requests lower than this will be set to the value of this
property. Additionally, a node manager that is configured to have less memory
than this value will be shut down by the resource manager.</description>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1024</value>
</property>
分配给AM单个容器可申请的最大内存: MB
<property>
<description>The maximum allocation for every container request at the RM
in MBs. Memory requests higher than this will throw an
InvalidResourceRequestException.</description>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>8192</value>
</property>
分配给AM单个容器可申请的最小虚拟的CPU个数:
<property>
<description>The minimum allocation for every container request at the RM
in terms of virtual CPU cores. Requests lower than this will be set to the
value of this property. Additionally, a node manager that is configured to
have fewer virtual cores than this value will be shut down by the resource
manager.</description>
<name>yarn.scheduler.minimum-allocation-vcores</name>
<value>1</value>
</property>
分配给AM单个容器可申请的最大虚拟的CPU个数:
<property>
<description>The maximum allocation for every container request at the RM
in terms of virtual CPU cores. Requests higher than this will throw an
InvalidResourceRequestException.</description>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>4</value>
</property>
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
****************** 必须根据服务器实际内存来修改 ************************
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
NodeManager节点最大可用内存, 根据实际机器上的物理内存进行配置:
NodeManager节点最大Container数量:
max(Container) = yarn.nodemanager.resource.memory-mb / yarn.scheduler.maximum-allocation-mb
<property>
<description>Amount of physical memory, in MB, that can be allocated
for containers. If set to -1 and
yarn.nodemanager.resource.detect-hardware-capabilities is true, it is
automatically calculated(in case of Windows and Linux).
In other cases, the default is 8192MB.
</description>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>24576</value>
</property>
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
****************** 必须根据服务器实际CPU来修改 ************************
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
节点服务器上yarn可以使用的虚拟的CPU个数,默认是8,推荐配置与核心个数相同。
如果节点CPU的核心个数不足8个,需要调小这个值,yarn不会智能的去检测物理核数。如果机器性能较好,可以配置为物理核数的2倍。
<property>
<description>Number of vcores that can be allocated
for containers. This is used by the RM scheduler when allocating
resources for containers. This is not used to limit the number of
CPUs used by YARN containers. If it is set to -1 and
yarn.nodemanager.resource.detect-hardware-capabilities is true, it is
automatically determined from the hardware in case of Windows and Linux.
In other cases, number of vcores is 8 by default.</description>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>32</value>
</property>
下面四项一般不需要修改,除非我们上面创建子目录tmp, logs时不是这样的名称,否则是不需要改动的。
<property>
<name>hadoop.tmp.dir</name>
<value>${hadoop.home}/tmp</value>
</property>
<property>
<name>yarn.log.dir</name>
<value>${hadoop.home}/logs/yarn</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>${hadoop.tmp.dir}/yarn/nm-local-dir</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>${yarn.log.dir}/userlogs</value>
</property>
* 4.6 capacity-scheduler.xml
<property>
<name>yarn.scheduler.capacity.resource-calculator</name>
<!--
<value>org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator</value>
-->
<value>org.apache.hadoop.yarn.util.resource.DominantResourceCalculator</value>
<description>
The ResourceCalculator implementation to be used to compare
Resources in the scheduler.
The default i.e. DefaultResourceCalculator only uses Memory while
DominantResourceCalculator uses dominant-resource to compare
multi-dimensional resources such as Memory, CPU etc.
</description>
</property>
注释里的英文已经说明白了,如果采用DefaultResourceCalculator则仅仅计算内存,只有DominantResourceCalculator才同时计算内存和CPU。
* 4.7 slaves: 从节点域名配置
hadoop1
hadoop3
hadoop4
hadoop2 (如果在master节点上同时部署slave的话)
* 4.8 配置文件分发
一旦这7份配置文件都修改妥当,则把它们分发到所有节点服务器的HADOOP_CONF_DIR目录里,所有节点应当目录规划一致。
5. 运行集群的系统用户账号
通常,推荐HDFS和YARN集群运行在两个不同的账号下,例如:HDFS采用hdfs用户,YARN采用yarn用户。
本例中,我们只采用一个账号test,HDFS和YARN安装目录也在同一台机器上,只是dfs、logs、tmp下建立HDFS和YARN各自子目录而已。
为了把Hadoop集群运行起来,必须同时启动HDFS和YARN两个集群。
6. 设置ssh免密登录
为了从master节点免密登录所有slave节点,我们在master节点192.168.1.2上执行:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
在test用户主目录下.ssh目录里,得到:
authorized_keys id_rsa id_rsa.pub known_hosts
先把自己id_rsa.pub添加进authorized_keys:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
现在需要把id_rsa.pub文件分发到所有slave节点,追加到它们.ssh目录里authorized_keys之中。
scp ~/.ssh/id_rsa.pub test@192.168.1.1:./
scp ~/.ssh/id_rsa.pub test@192.168.1.3:./
scp ~/.ssh/id_rsa.pub test@192.168.1.4:./
然后在3台机器上去执行:
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
大功告成,我们从192.168.1.2上登录其它4台机器(包括自己,如果自己也作为slave节点的话)试试看:
ssh test@192.168.1.1
ssh test@192.168.1.2
ssh test@192.168.1.3
ssh test@192.168.1.4
应该都是直接进入,不再提示输入密码了。
7. 格式化hdfs
$HADOOP_PREFIX/bin/hdfs namenode -format <cluster_name>
8. 启动hadoop NameNode daemon和DataNode daemon
* 8.1 启动/关闭HDFS NameNode:
在master节点192.168.1.2上执行:
$HADOOP_PREFIX/sbin/hadoop-daemon.sh --config $HADOOP_CONF_DIR --script hdfs start namenode
启动成功后,可以打开管理系统:http://192.168.1.2:50070/
关闭则执行:
$HADOOP_PREFIX/sbin/hadoop-daemon.sh --config $HADOOP_CONF_DIR --script hdfs stop namenode
* 8.2 启动/关闭HDFS DataNode:
在各个slave节点上执行:这里是3台机器hadoop1, hadoop3, hadoop4
执行:
$HADOOP_PREFIX/sbin/hadoop-daemons.sh --config $HADOOP_CONF_DIR --script hdfs start datanode
关闭则执行:
$HADOOP_PREFIX/sbin/hadoop-daemons.sh --config $HADOOP_CONF_DIR --script hdfs stop datanode
* 8.3 启动/关闭所有节点:
上面我们已经设置了master节点免密登录所有slave节点,则可以在master节点一次性启动整个集群。
执行:
$HADOOP_PREFIX/sbin/start-dfs.sh
关闭则执行:
$HADOOP_PREFIX/sbin/stop-dfs.sh
9. 启动ResourceManager daemon 和 NodeManager daemon
* 9.1 启动/关闭ResourceManager节点:
在master节点192.168.1.2上执行:
$HADOOP_YARN_HOME/sbin/yarn-daemon.sh --config $HADOOP_CONF_DIR start resourcemanager
启动成功后,可以打开管理系统:http://192.168.1.2:8088/
关闭则执行:
$HADOOP_YARN_HOME/sbin/yarn-daemon.sh --config $HADOOP_CONF_DIR stop resourcemanager
* 9.2 启动/关闭NodeManager节点:
在各个slave节点上执行:这里是3台机器hadoop1, hadoop3, hadoop4
执行:
$HADOOP_YARN_HOME/sbin/yarn-daemons.sh --config $HADOOP_CONF_DIR start nodemanager
关闭则执行:
$HADOOP_YARN_HOME/sbin/yarn-daemons.sh --config $HADOOP_CONF_DIR stop nodemanager
* 9.3 启动/关闭standalone WebAppProxy server:
WebAppProxy可以独立部署在一台或多台服务器上,只要你有资源,本例中我们还是和ResourceManager节点同一台机器部署。
在master节点192.168.1.2上执行:hadoop2
执行:
$HADOOP_YARN_HOME/sbin/yarn-daemon.sh --config $HADOOP_CONF_DIR start proxyserver
关闭则执行:
$HADOOP_YARN_HOME/sbin/yarn-daemon.sh --config $HADOOP_CONF_DIR stop proxyserver
* 9.4 启动所有节点:
上面我们已经设置了master节点免密登录所有slave节点,则可以在master节点一次性启动整个集群。
执行:
$HADOOP_PREFIX/sbin/start-yarn.sh
关闭则执行:
$HADOOP_PREFIX/sbin/stop-yarn.sh
10. 整合脚本
每次都搞这么长的命令太复杂了,提供run.sh脚本,包装集群启动关闭命令,方便运维工作。
test@hadoop2:/opt/bigdata/hadoop-2.10.0$ ./run.sh
usage: ./run.sh [cmd]
./run.sh namenode_format [cluster name]
./run.sh start [namenode | datanode]
./run.sh stop [namenode | datanode]
./run.sh start dfs
./run.sh stop dfs
./run.sh start [resourcemanager | nodemanager]
./run.sh stop [resourcemanager | nodemanager]
./run.sh start yarn
./run.sh stop yarn
./run.sh start proxyserver
./run.sh stop proxyserver
./run.sh set_env
由于CSDN上传资源审核太慢,还是把所有配置文件直接贴上来吧,万一有需要这些完整脚本来参考的呢。
core-site.xml:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>hadoop.home</name>
<value>/opt/bigdata/hadoop-2.10.0</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.1.2:9900</value>
<description>The name of the default file system. A URI whose
scheme and authority determine the FileSystem implementation. The
uri's scheme determines the config property (fs.SCHEME.impl) naming
the FileSystem implementation class. The uri's authority is used to
determine the host, port, etc. for a filesystem.</description>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
<description>The size of buffer for use in sequence files.
The size of this buffer should probably be a multiple of hardware
page size (4096 on Intel x86), and it determines how much data is
buffered during read and write operations.</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>${hadoop.home}/tmp/hdfs</value>
<description>A base for other temporary directories.</description>
</property>
</configuration>
hdfs-site.xml:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>hadoop.home</name>
<value>/opt/bigdata/hadoop-2.10.0</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>${hadoop.home}/dfs/name</value>
<description>Determines where on the local filesystem the DFS name node
should store the name table(fsimage). If this is a comma-delimited list
of directories then the name table is replicated in all of the
directories, for redundancy. </description>
</property>
<property>
<name>dfs.hosts</name>
<value></value>
<description>Names a file that contains a list of hosts that are
permitted to connect to the namenode. The full pathname of the file
must be specified. If the value is empty, all hosts are
permitted.</description>
</property>
<property>
<name>dfs.hosts.exclude</name>
<value></value>
<description>Names a file that contains a list of hosts that are
not permitted to connect to the namenode. The full pathname of the
file must be specified. If the value is empty, no hosts are
excluded.</description>
</property>
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
<description>
The default block size for new files, in bytes.
You can use the following suffix (case insensitive):
k(kilo), m(mega), g(giga), t(tera), p(peta), e(exa) to specify the size (such as 128k, 512m, 1g, etc.),
Or provide complete size in bytes (such as 134217728 for 128 MB).
</description>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>10</value>
<description>The number of Namenode RPC server threads that listen to
requests from clients.
If dfs.namenode.servicerpc-address is not configured then
Namenode RPC server threads listen to requests from all nodes.
</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>${hadoop.home}/dfs/data</value>
<description>Determines where on the local filesystem an DFS data node
should store its blocks. If this is a comma-delimited
list of directories, then data will be stored in all named
directories, typically on different devices. The directories should be tagged
with corresponding storage types ([SSD]/[DISK]/[ARCHIVE]/[RAM_DISK]) for HDFS
storage policies. The default storage type will be DISK if the directory does
not have a storage type tagged explicitly. Directories that do not exist will
be created if local filesystem permission allows.
</description>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
<description>Default block replication.
The actual number of replications can be specified when the file is created.
The default is used if replication is not specified in create time.
</description>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
<description>
If "true", enable permission checking in HDFS.
If "false", permission checking is turned off,
but all other behavior is unchanged.
Switching from one parameter value to the other does not change the mode,
owner or group of files or directories.
</description>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
<description>
Enable WebHDFS (REST API) in Namenodes and Datanodes.
</description>
</property>
<property>
<name>dfs.http.address</name>
<value>hadoop2:50070</value>
<description> hdfs namenode web ui 地址 </description>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>hadoop2:50090</value>
<description> hdfs scondary web ui 地址 </description>
</property>
</configuration>
yarn-site.xml:
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<property>
<name>hadoop.home</name>
<value>/opt/bigdata/hadoop-2.10.0</value>
</property>
<!-- Site specific YARN configuration properties -->
<property>
<description>Are acls enabled.</description>
<name>yarn.acl.enable</name>
<value>false</value>
</property>
<property>
<description>ACL of who can be admin of the YARN cluster.</description>
<name>yarn.admin.acl</name>
<value>*</value>
</property>
<property>
<description>Whether to enable log aggregation. Log aggregation collects
each container's logs and moves these logs onto a file-system, for e.g.
HDFS, after the application completes. Users can configure the
"yarn.nodemanager.remote-app-log-dir" and
"yarn.nodemanager.remote-app-log-dir-suffix" properties to determine
where these logs are moved to. Users can access the logs via the
Application Timeline Server.
</description>
<name>yarn.log-aggregation-enable</name>
<value>false</value>
</property>
<property>
<description>The hostname of the RM.</description>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop2</value>
</property>
<property>
<description>The address of the applications manager interface in the RM.</description>
<name>yarn.resourcemanager.address</name>
<value>${yarn.resourcemanager.hostname}:8032</value>
</property>
<property>
<description>The address of the scheduler interface.</description>
<name>yarn.resourcemanager.scheduler.address</name>
<value>${yarn.resourcemanager.hostname}:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>${yarn.resourcemanager.hostname}:8031</value>
</property>
<property>
<description>The address of the RM admin interface.</description>
<name>yarn.resourcemanager.admin.address</name>
<value>${yarn.resourcemanager.hostname}:8033</value>
</property>
<property>
<description>
The http address of the RM web application.
If only a host is provided as the value,
the webapp will be served on a random port.
</description>
<name>yarn.resourcemanager.webapp.address</name>
<value>${yarn.resourcemanager.hostname}:8088</value>
</property>
<property>
<description>A comma separated list of services where service name should only
contain a-zA-Z0-9_ and can not start with numbers</description>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<description>The class to use as the resource scheduler.</description>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
<property>
<description>The minimum allocation for every container request at the RM
in MBs. Memory requests lower than this will be set to the value of this
property. Additionally, a node manager that is configured to have less memory
than this value will be shut down by the resource manager.</description>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1024</value>
</property>
<property>
<description>The maximum allocation for every container request at the RM
in MBs. Memory requests higher than this will throw an
InvalidResourceRequestException.</description>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>8192</value>
</property>
<property>
<description>The minimum allocation for every container request at the RM
in terms of virtual CPU cores. Requests lower than this will be set to the
value of this property. Additionally, a node manager that is configured to
have fewer virtual cores than this value will be shut down by the resource
manager.</description>
<name>yarn.scheduler.minimum-allocation-vcores</name>
<value>1</value>
</property>
<property>
<description>The maximum allocation for every container request at the RM
in terms of virtual CPU cores. Requests higher than this will throw an
InvalidResourceRequestException.</description>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>4</value>
</property>
<property>
<description>Amount of physical memory, in MB, that can be allocated
for containers. If set to -1 and
yarn.nodemanager.resource.detect-hardware-capabilities is true, it is
automatically calculated(in case of Windows and Linux).
In other cases, the default is 8192MB.
NodeManager节点最大可用内存, 根据实际机器上的物理内存进行配置:
NodeManager节点最大Container数量:
max(Container) = yarn.nodemanager.resource.memory-mb / yarn.scheduler.maximum-allocation-mb
</description>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>-1</value>
</property>
<property>
<description>Ratio between virtual memory to physical memory when
setting memory limits for containers. Container allocations are
expressed in terms of physical memory, and virtual memory usage
is allowed to exceed this allocation by this ratio.
</description>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<property>
<description>
Number of vcores that can be allocated
for containers. This is used by the RM scheduler when allocating
resources for containers. This is not used to limit the number of
CPUs used by YARN containers. If it is set to -1 and
yarn.nodemanager.resource.detect-hardware-capabilities is true, it is
automatically determined from the hardware in case of Windows and Linux.
In other cases, number of vcores is 8 by default.
节点服务器上yarn可以使用的虚拟的CPU个数,默认是8,推荐配置与核心个数相同。
如果节点CPU的核心个数不足8个,需要调小这个值,yarn不会智能的去检测物理核数。
如果机器性能较好,可以配置为物理核数的2倍。
</description>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>32</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>${hadoop.home}/tmp</value>
</property>
<property>
<name>yarn.log.dir</name>
<value>${hadoop.home}/logs/yarn</value>
</property>
<property>
<description>List of directories to store localized files in. An
application's localized file directory will be found in:
${yarn.nodemanager.local-dirs}/usercache/${user}/appcache/application_${appid}.
Individual containers' work directories, called container_${contid}, will
be subdirectories of this.
</description>
<name>yarn.nodemanager.local-dirs</name>
<value>${hadoop.tmp.dir}/yarn/nm-local-dir</value>
</property>
<property>
<description>
Where to store container logs. An application's localized log directory
will be found in ${yarn.nodemanager.log-dirs}/application_${appid}.
Individual containers' log directories will be below this, in directories
named container_{$contid}. Each container directory will contain the files
stderr, stdin, and syslog generated by that container.
</description>
<name>yarn.nodemanager.log-dirs</name>
<value>${yarn.log.dir}/userlogs</value>
</property>
<property>
<description>Time in seconds to retain user logs. Only applicable if
log aggregation is disabled
</description>
<name>yarn.nodemanager.log.retain-seconds</name>
<value>10800</value>
</property>
<property>
<description>Whether physical memory limits will be enforced for containers.</description>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<description>Whether virtual memory limits will be enforced for containers.</description>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
capacity-scheduler.xml:
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<property>
<name>yarn.scheduler.capacity.maximum-applications</name>
<value>10000</value>
<description>
Maximum number of applications that can be pending and running.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.maximum-am-resource-percent</name>
<value>0.1</value>
<description>
Maximum percent of resources in the cluster which can be used to run
application masters i.e. controls number of concurrent running
applications.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.resource-calculator</name>
<!--
<value>org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator</value>
-->
<value>org.apache.hadoop.yarn.util.resource.DominantResourceCalculator</value>
<description>
The ResourceCalculator implementation to be used to compare
Resources in the scheduler.
The default i.e. DefaultResourceCalculator only uses Memory while
DominantResourceCalculator uses dominant-resource to compare
multi-dimensional resources such as Memory, CPU etc.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>default</value>
<description>
The queues at the this level (root is the root queue).
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.capacity</name>
<value>100</value>
<description>Default queue target capacity.</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.user-limit-factor</name>
<value>1</value>
<description>
Default queue user limit a percentage from 0.0 to 1.0.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.maximum-capacity</name>
<value>100</value>
<description>
The maximum capacity of the default queue.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.state</name>
<value>RUNNING</value>
<description>
The state of the default queue. State can be one of RUNNING or STOPPED.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.acl_submit_applications</name>
<value>*</value>
<description>
The ACL of who can submit jobs to the default queue.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.acl_administer_queue</name>
<value>*</value>
<description>
The ACL of who can administer jobs on the default queue.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.acl_application_max_priority</name>
<value>*</value>
<description>
The ACL of who can submit applications with configured priority.
For e.g, [user={name} group={name} max_priority={priority} default_priority={priority}]
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.maximum-application-lifetime
</name>
<value>-1</value>
<description>
Maximum lifetime of an application which is submitted to a queue
in seconds. Any value less than or equal to zero will be considered as
disabled.
This will be a hard time limit for all applications in this
queue. If positive value is configured then any application submitted
to this queue will be killed after exceeds the configured lifetime.
User can also specify lifetime per application basis in
application submission context. But user lifetime will be
overridden if it exceeds queue maximum lifetime. It is point-in-time
configuration.
Note : Configuring too low value will result in killing application
sooner. This feature is applicable only for leaf queue.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.default-application-lifetime
</name>
<value>-1</value>
<description>
Default lifetime of an application which is submitted to a queue
in seconds. Any value less than or equal to zero will be considered as
disabled.
If the user has not submitted application with lifetime value then this
value will be taken. It is point-in-time configuration.
Note : Default lifetime can't exceed maximum lifetime. This feature is
applicable only for leaf queue.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.node-locality-delay</name>
<value>40</value>
<description>
Number of missed scheduling opportunities after which the CapacityScheduler
attempts to schedule rack-local containers.
When setting this parameter, the size of the cluster should be taken into account.
We use 40 as the default value, which is approximately the number of nodes in one rack.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.rack-locality-additional-delay</name>
<value>-1</value>
<description>
Number of additional missed scheduling opportunities over the node-locality-delay
ones, after which the CapacityScheduler attempts to schedule off-switch containers,
instead of rack-local ones.
Example: with node-locality-delay=40 and rack-locality-delay=20, the scheduler will
attempt rack-local assignments after 40 missed opportunities, and off-switch assignments
after 40+20=60 missed opportunities.
When setting this parameter, the size of the cluster should be taken into account.
We use -1 as the default value, which disables this feature. In this case, the number
of missed opportunities for assigning off-switch containers is calculated based on
the number of containers and unique locations specified in the resource request,
as well as the size of the cluster.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.queue-mappings</name>
<value></value>
<description>
A list of mappings that will be used to assign jobs to queues
The syntax for this list is [u|g]:[name]:[queue_name][,next mapping]*
Typically this list will be used to map users to queues,
for example, u:%user:%user maps all users to queues with the same name
as the user.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.queue-mappings-override.enable</name>
<value>false</value>
<description>
If a queue mapping is present, will it override the value specified
by the user? This can be used by administrators to place jobs in queues
that are different than the one specified by the user.
The default is false.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.per-node-heartbeat.maximum-offswitch-assignments</name>
<value>1</value>
<description>
Controls the number of OFF_SWITCH assignments allowed
during a node's heartbeat. Increasing this value can improve
scheduling rate for OFF_SWITCH containers. Lower values reduce
"clumping" of applications on particular nodes. The default is 1.
Legal values are 1-MAX_INT. This config is refreshable.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.workflow-priority-mappings</name>
<value></value>
<description>
A list of mappings that will be used to override application priority.
The syntax for this list is
[workflowId]:[full_queue_name]:[priority][,next mapping]*
where an application submitted (or mapped to) queue "full_queue_name"
and workflowId "workflowId" (as specified in application submission
context) will be given priority "priority".
</description>
</property>
<property>
<name>yarn.scheduler.capacity.workflow-priority-mappings-override.enable</name>
<value>false</value>
<description>
If a priority mapping is present, will it override the value specified
by the user? This can be used by administrators to give applications a
priority that is different than the one specified by the user.
The default is false.
</description>
</property>
</configuration>
hadoop-env.sh:
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# Set Hadoop-specific environment variables here.
# The only required environment variable is JAVA_HOME. All others are
# optional. When running a distributed configuration it is best to
# set JAVA_HOME in this file, so that it is correctly defined on
# remote nodes.
# The java implementation to use.
JAVA_HOME=/opt/bigdata/jdk1.8.0_144
export JAVA_HOME=${JAVA_HOME}
# The jsvc implementation to use. Jsvc is required to run secure datanodes
# that bind to privileged ports to provide authentication of data transfer
# protocol. Jsvc is not required if SASL is configured for authentication of
# data transfer protocol using non-privileged ports.
#export JSVC_HOME=${JSVC_HOME}
export HADOOP_PREFIX=/opt/bigdata/hadoop-2.10.0
export HADOOP_HOME=$HADOOP_PREFIX
export HADOOP_YARN_HOME=/opt/bigdata/hadoop-2.10.0
HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-"/etc/hadoop"}
# Extra Java CLASSPATH elements. Automatically insert capacity-scheduler.
for f in $HADOOP_HOME/contrib/capacity-scheduler/*.jar; do
if [ "$HADOOP_CLASSPATH" ]; then
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$f
else
export HADOOP_CLASSPATH=$f
fi
done
# The maximum amount of heap to use, in MB. Default is 1000.
#export HADOOP_HEAPSIZE=
#export HADOOP_NAMENODE_INIT_HEAPSIZE=""
# Enable extra debugging of Hadoop's JAAS binding, used to set up
# Kerberos security.
# export HADOOP_JAAS_DEBUG=true
# Extra Java runtime options. Empty by default.
# For Kerberos debugging, an extended option set logs more invormation
# export HADOOP_OPTS="-Djava.net.preferIPv4Stack=true -Dsun.security.krb5.debug=true -Dsun.security.spnego.debug"
export HADOOP_OPTS="$HADOOP_OPTS -Djava.net.preferIPv4Stack=true"
# Command specific options appended to HADOOP_OPTS when specified
export HADOOP_NAMENODE_OPTS="-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_NAMENODE_OPTS"
export HADOOP_DATANODE_OPTS="-Dhadoop.security.logger=ERROR,RFAS $HADOOP_DATANODE_OPTS"
export HADOOP_SECONDARYNAMENODE_OPTS="-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_SECONDARYNAMENODE_OPTS"
export HADOOP_NFS3_OPTS="$HADOOP_NFS3_OPTS"
export HADOOP_PORTMAP_OPTS="-Xmx512m $HADOOP_PORTMAP_OPTS"
# The following applies to multiple commands (fs, dfs, fsck, distcp etc)
export HADOOP_CLIENT_OPTS="$HADOOP_CLIENT_OPTS"
# set heap args when HADOOP_HEAPSIZE is empty
if [ "$HADOOP_HEAPSIZE" = "" ]; then
export HADOOP_CLIENT_OPTS="-Xmx512m $HADOOP_CLIENT_OPTS"
fi
#HADOOP_JAVA_PLATFORM_OPTS="-XX:-UsePerfData $HADOOP_JAVA_PLATFORM_OPTS"
# On secure datanodes, user to run the datanode as after dropping privileges.
# This **MUST** be uncommented to enable secure HDFS if using privileged ports
# to provide authentication of data transfer protocol. This **MUST NOT** be
# defined if SASL is configured for authentication of data transfer protocol
# using non-privileged ports.
export HADOOP_SECURE_DN_USER=${HADOOP_SECURE_DN_USER}
# Where log files are stored. $HADOOP_HOME/logs by default.
#export HADOOP_LOG_DIR=${HADOOP_LOG_DIR}/$USER
export HADOOP_LOG_DIR=${HADOOP_HOME}/logs/hdfs
# Where log files are stored in the secure data environment.
#export HADOOP_SECURE_DN_LOG_DIR=${HADOOP_LOG_DIR}/${HADOOP_HDFS_USER}
###
# HDFS Mover specific parameters
###
# Specify the JVM options to be used when starting the HDFS Mover.
# These options will be appended to the options specified as HADOOP_OPTS
# and therefore may override any similar flags set in HADOOP_OPTS
#
# export HADOOP_MOVER_OPTS=""
###
# Router-based HDFS Federation specific parameters
# Specify the JVM options to be used when starting the RBF Routers.
# These options will be appended to the options specified as HADOOP_OPTS
# and therefore may override any similar flags set in HADOOP_OPTS
#
# export HADOOP_DFSROUTER_OPTS=""
###
###
# Advanced Users Only!
###
# The directory where pid files are stored. /tmp by default.
# NOTE: this should be set to a directory that can only be written to by
# the user that will run the hadoop daemons. Otherwise there is the
# potential for a symlink attack.
export HADOOP_PID_DIR=${HADOOP_PID_DIR}
export HADOOP_SECURE_DN_PID_DIR=${HADOOP_PID_DIR}
# A string representing this instance of hadoop. $USER by default.
export HADOOP_IDENT_STRING=$USER
yarn-env.sh:
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
HADOOP_YARN_USER=test
YARN_CONF_DIR=$HADOOP_YARN_HOME/etc/hadoop
# User for YARN daemons
export HADOOP_YARN_USER=${HADOOP_YARN_USER:-yarn}
# resolve links - $0 may be a softlink
export YARN_CONF_DIR="${YARN_CONF_DIR:-$HADOOP_YARN_HOME/conf}"
# some Java parameters
# export JAVA_HOME=/home/y/libexec/jdk1.6.0/
export JAVA_HOME=/opt/bigdata/jdk1.8.0_144
if [ "$JAVA_HOME" != "" ]; then
#echo "run java in $JAVA_HOME"
JAVA_HOME=$JAVA_HOME
fi
if [ "$JAVA_HOME" = "" ]; then
echo "Error: JAVA_HOME is not set."
exit 1
fi
JAVA=$JAVA_HOME/bin/java
JAVA_HEAP_MAX=-Xmx1000m
# For setting YARN specific HEAP sizes please use this
# Parameter and set appropriately
# YARN_HEAPSIZE=1000
# check envvars which might override default args
if [ "$YARN_HEAPSIZE" != "" ]; then
JAVA_HEAP_MAX="-Xmx""$YARN_HEAPSIZE""m"
fi
# Resource Manager specific parameters
# Specify the max Heapsize for the ResourceManager using a numerical value
# in the scale of MB. For example, to specify an jvm option of -Xmx1000m, set
# the value to 1000.
# This value will be overridden by an Xmx setting specified in either YARN_OPTS
# and/or YARN_RESOURCEMANAGER_OPTS.
# If not specified, the default value will be picked from either YARN_HEAPMAX
# or JAVA_HEAP_MAX with YARN_HEAPMAX as the preferred option of the two.
#export YARN_RESOURCEMANAGER_HEAPSIZE=1000
# Specify the max Heapsize for the timeline server using a numerical value
# in the scale of MB. For example, to specify an jvm option of -Xmx1000m, set
# the value to 1000.
# This value will be overridden by an Xmx setting specified in either YARN_OPTS
# and/or YARN_TIMELINESERVER_OPTS.
# If not specified, the default value will be picked from either YARN_HEAPMAX
# or JAVA_HEAP_MAX with YARN_HEAPMAX as the preferred option of the two.
#export YARN_TIMELINESERVER_HEAPSIZE=1000
# Specify the JVM options to be used when starting the ResourceManager.
# These options will be appended to the options specified as YARN_OPTS
# and therefore may override any similar flags set in YARN_OPTS
#export YARN_RESOURCEMANAGER_OPTS=
# Node Manager specific parameters
# Specify the max Heapsize for the NodeManager using a numerical value
# in the scale of MB. For example, to specify an jvm option of -Xmx1000m, set
# the value to 1000.
# This value will be overridden by an Xmx setting specified in either YARN_OPTS
# and/or YARN_NODEMANAGER_OPTS.
# If not specified, the default value will be picked from either YARN_HEAPMAX
# or JAVA_HEAP_MAX with YARN_HEAPMAX as the preferred option of the two.
#export YARN_NODEMANAGER_HEAPSIZE=1000
# Specify the JVM options to be used when starting the NodeManager.
# These options will be appended to the options specified as YARN_OPTS
# and therefore may override any similar flags set in YARN_OPTS
#export YARN_NODEMANAGER_OPTS=
# so that filenames w/ spaces are handled correctly in loops below
IFS=
# default log directory & file
if [ "$YARN_LOG_DIR" = "" ]; then
YARN_LOG_DIR="$HADOOP_YARN_HOME/logs/yarn"
fi
if [ "$YARN_LOGFILE" = "" ]; then
YARN_LOGFILE='yarn.log'
fi
# default policy file for service-level authorization
if [ "$YARN_POLICYFILE" = "" ]; then
YARN_POLICYFILE="hadoop-policy.xml"
fi
# restore ordinary behaviour
unset IFS
YARN_OPTS="$YARN_OPTS -Dhadoop.log.dir=$YARN_LOG_DIR"
YARN_OPTS="$YARN_OPTS -Dyarn.log.dir=$YARN_LOG_DIR"
YARN_OPTS="$YARN_OPTS -Dhadoop.log.file=$YARN_LOGFILE"
YARN_OPTS="$YARN_OPTS -Dyarn.log.file=$YARN_LOGFILE"
YARN_OPTS="$YARN_OPTS -Dyarn.home.dir=$YARN_COMMON_HOME"
YARN_OPTS="$YARN_OPTS -Dyarn.id.str=$YARN_IDENT_STRING"
YARN_OPTS="$YARN_OPTS -Dhadoop.root.logger=${YARN_ROOT_LOGGER:-INFO,console}"
YARN_OPTS="$YARN_OPTS -Dyarn.root.logger=${YARN_ROOT_LOGGER:-INFO,console}"
if [ "x$JAVA_LIBRARY_PATH" != "x" ]; then
YARN_OPTS="$YARN_OPTS -Djava.library.path=$JAVA_LIBRARY_PATH"
fi
YARN_OPTS="$YARN_OPTS -Dyarn.policy.file=$YARN_POLICYFILE"
###
# Router specific parameters
###
# Specify the JVM options to be used when starting the Router.
# These options will be appended to the options specified as HADOOP_OPTS
# and therefore may override any similar flags set in HADOOP_OPTS
#
# See ResourceManager for some examples
#
#export YARN_ROUTER_OPTS=
slaves:文章来源:https://www.toymoban.com/news/detail-804518.html
hadoop1
hadoop3
hadoop4
run.sh文章来源地址https://www.toymoban.com/news/detail-804518.html
#!/bin/bash
#
namenode_format()
{
cluster_name=$1
echo "cluster_name=${cluster_name}, format..."
$HADOOP_PREFIX/bin/hdfs namenode -format $cluster_name
}
start()
{
type=$1
if [ "$type" = "namenode" ]; then
$HADOOP_PREFIX/sbin/hadoop-daemon.sh --config $HADOOP_CONF_DIR --script hdfs start namenode
elif [ "$type" = "datanode" ]; then
$HADOOP_PREFIX/sbin/hadoop-daemons.sh --config $HADOOP_CONF_DIR --script hdfs start datanode
elif [ "$type" = "resourcemanager" ]; then
$HADOOP_YARN_HOME/sbin/yarn-daemon.sh --config $HADOOP_CONF_DIR start resourcemanager
elif [ "$type" = "nodemanager" ]; then
$HADOOP_YARN_HOME/sbin/yarn-daemon.sh --config $HADOOP_CONF_DIR start nodemanager
elif [ "$type" = "proxyserver" ]; then
$HADOOP_YARN_HOME/sbin/yarn-daemon.sh --config $HADOOP_CONF_DIR start proxyserver
elif [ "$type" = "dfs" ]; then
$HADOOP_PREFIX/sbin/start-dfs.sh
elif [ "$type" = "yarn" ]; then
$HADOOP_PREFIX/sbin/start-yarn.sh
else
echo "no supported: $type"
fi
}
stop()
{
type=$1
if [ "$type" = "namenode" ]; then
$HADOOP_PREFIX/sbin/hadoop-daemon.sh --config $HADOOP_CONF_DIR --script hdfs stop namenode
elif [ "$type" = "datanode" ]; then
$HADOOP_PREFIX/sbin/hadoop-daemons.sh --config $HADOOP_CONF_DIR --script hdfs stop datanode
elif [ "$type" = "resourcemanager" ]; then
$HADOOP_YARN_HOME/sbin/yarn-daemon.sh --config $HADOOP_CONF_DIR stop resourcemanager
elif [ "$type" = "nodemanager" ]; then
$HADOOP_YARN_HOME/sbin/yarn-daemon.sh --config $HADOOP_CONF_DIR stop nodemanager
elif [ "$type" = "proxyserver" ]; then
$HADOOP_YARN_HOME/sbin/yarn-daemon.sh --config $HADOOP_CONF_DIR stop proxyserver
elif [ "$type" = "dfs" ]; then
$HADOOP_PREFIX/sbin/stop-dfs.sh
elif [ "$type" = "yarn" ]; then
$HADOOP_PREFIX/sbin/stop-yarn.sh
else
echo "no supported: $type"
fi
}
set_env()
{
export HADOOP_CLASSPATH=`hadoop classpath`
}
usage()
{
echo "usage: ./run.sh [cmd]"
echo " ./run.sh namenode_format [cluster name]"
echo "----------------------------------------------"
echo " ./run.sh start [namenode | datanode]"
echo " ./run.sh stop [namenode | datanode]"
echo " ./run.sh start dfs"
echo " ./run.sh stop dfs"
echo "----------------------------------------------"
echo " ./run.sh start [resourcemanager | nodemanager]"
echo " ./run.sh stop [resourcemanager | nodemanager]"
echo " ./run.sh start yarn"
echo " ./run.sh stop yarn"
echo " ./run.sh start proxyserver"
echo " ./run.sh stop proxyserver"
echo "----------------------------------------------"
echo " ./run.sh set_env"
}
if [ "$#" -lt "1" ]; then
usage
elif [ "$1" = "namenode_format" ]; then
namenode_format $2
elif [ "$1" = "start" ]; then
start $2
elif [ "$1" = "stop" ]; then
stop $2
elif [ "$1" = "env" ]; then
set_env
else
usage
fi
到了这里,关于Hadoop分布式集群安装的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!