引言
论文:Vary: Scaling up the Vision Vocabulary for Large Vision-Language Models
Paper | Github | Demo
许久不精读论文了,内心一直想找个专门的时间来细细品读自己感兴趣的论文。现在想来,无异于是自己骗自己了,因为根本就不存在那个专门的时间。所以改变最好的时候就是现在。
因为自己一直在做OCR相关,因为对LLM中文档智能相关的工作比较感兴趣。因此,就以旷视出的这篇工作Vary作为切入点,借此来学习LLM在文档智能领域的相关工作。
整体结构图
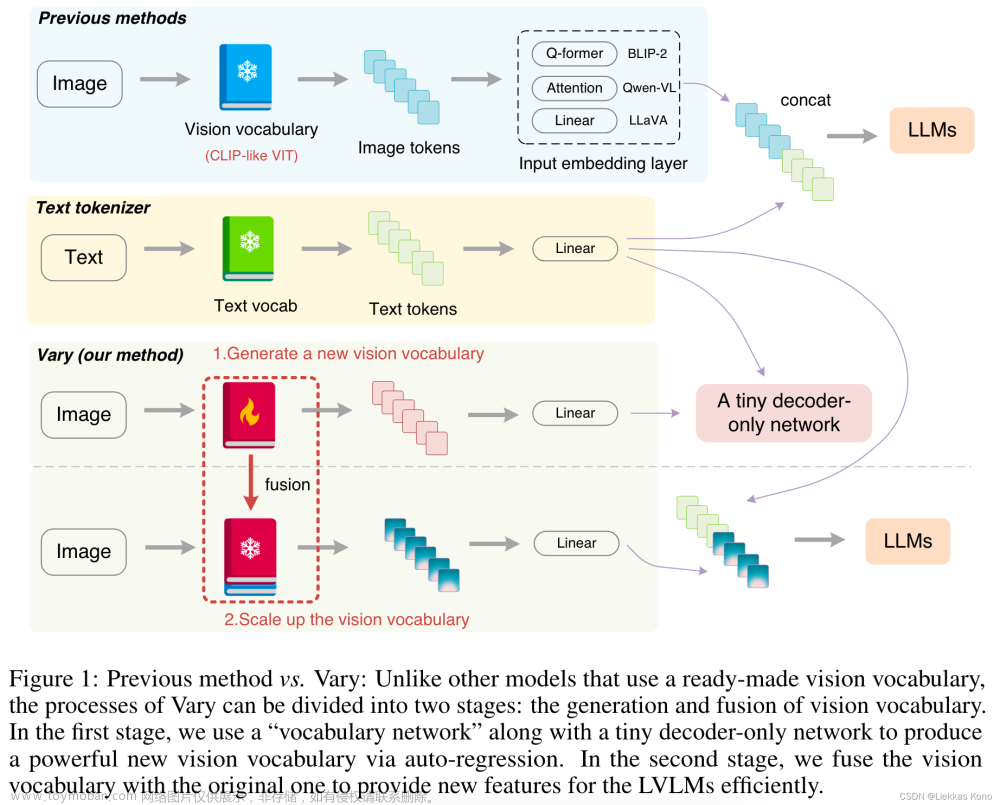
Figure 1:主要想说明Vary在产生vocabulary时,采用两阶段策略:在第一阶段,通过自回归方法,先产生一个新的vocabulary,在第二阶段,将新的vocabulary与原始的融合,作为一个新的vocabulary。
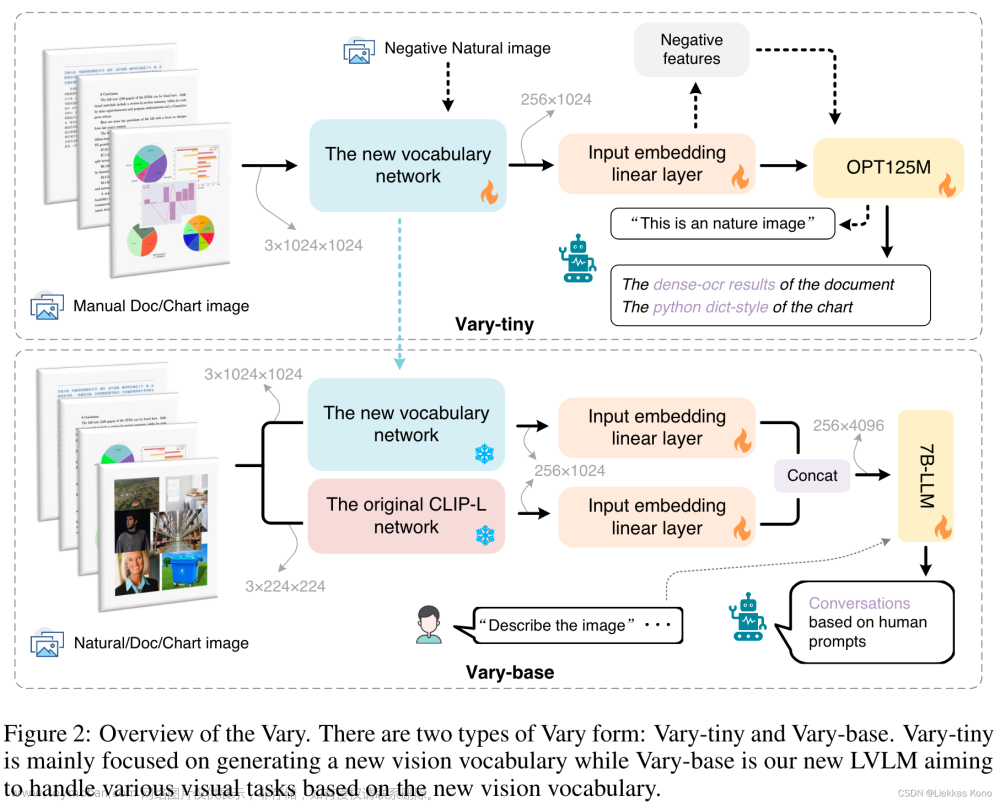
Figure 2: 第一阶段中,Vary为Vary-tiny,主要用来产生新的vocabulary;而Vary-base主要基于new vision vocabulary来处理各种visual tasks。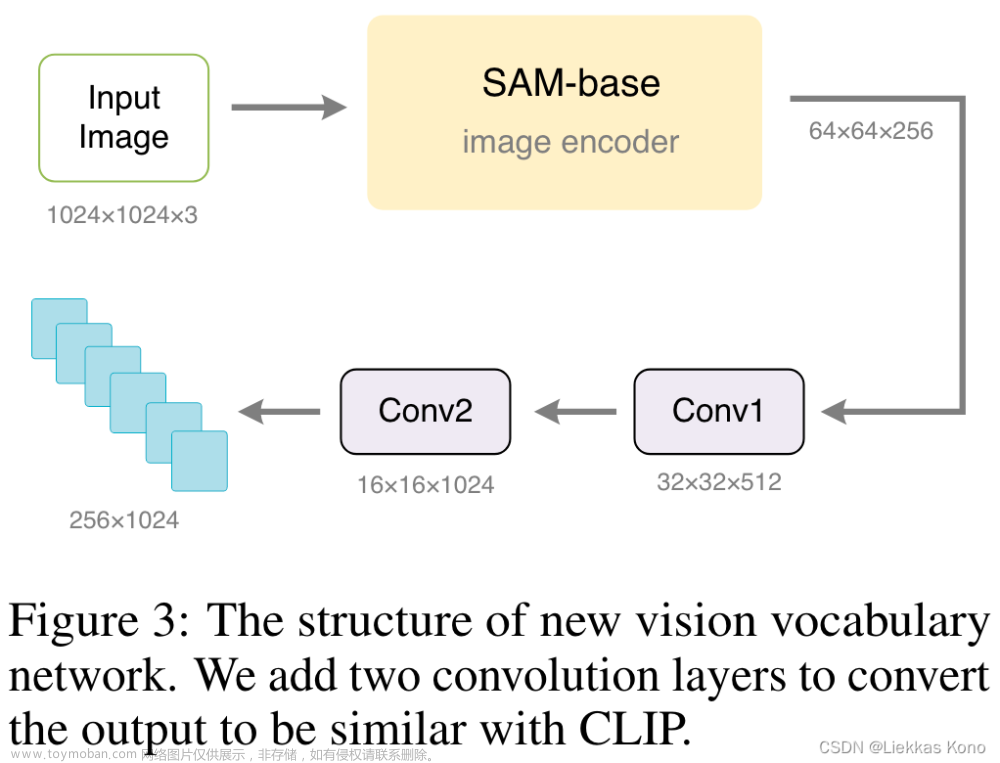
Vary-tiny中,使用在VIT-Det上预训练过的SAM作为image encoder,为了和之后CLIP-L对齐,又加了两个Conv。
Vary这篇工作整体思路较为简单,更多地方就要去看源码的细节实现了。
🤮 不过想要吐槽一下的是,论文中竟然和Nougat作比较。Vary和Nougat参数量来看简直不是一个量级啊。转过来想,也是,毕竟这个方向目前也没有一个除Nougat之外的基线了。
数据集构造
之所以将这部分作为一个单独章节来说,是因为这个工作的难点就在于此。Nougat和Vary都没有开源所用的数据集。Nougat好在给出了一些制作数据集的相关代码。Vary目前一点也没有放出来。所以这里也就只能根据论文来简单看看怎么做的了。
Vary-tiny部分
该部分主要聚焦于fine-grained perception,例如文档智能和图表理解,说是为了弥补CLIP的不足,因此这部分网络输入都是图像,没有文本输入的分支。
在训练Vary-tiny部分,作者将文档和图表数据作为positive samples,自然场景图像作为negative数据。
Document Data数据构造
由于该部分需要的数据为:输入是文档图像,输出是对应的markdown格式文本。目前没有公开的中英文文档数据集,因为作者自行构建的。
其中,英文文档主要来源于arXiv和CC-MAIN-2021-31-PDFUNTRUNCATED两部分。中文文档主要来源于互联网上的电子书。
处理方法:PyMuPDF库提取PDF每页信息,同时用pdf2image工具将PDF对应页转为图像。(感觉这里处理的较为粗糙,有较大提升空间)
最终构建了100w中文和100w英文文档图像对,用于训练Vary-tiny部分。
Chart Data构造
作者观察到LVLM不太擅长处理图表理解问题,尤其是中文图表。因此,本篇工作着重将其作为一个重点任务。
构建图表的image-text pair对方案:采用matplotlib和pyecharts作为渲染工具。渲染了matplotlib风格的中英文图表250k条,渲染了pyeharts风格中英文图表500k条。另外,构建图表的ground truth为一个python字典形式。其中图表中的文本,例如title, x-axis和y-axis都是从NLP语料库中随机选的。
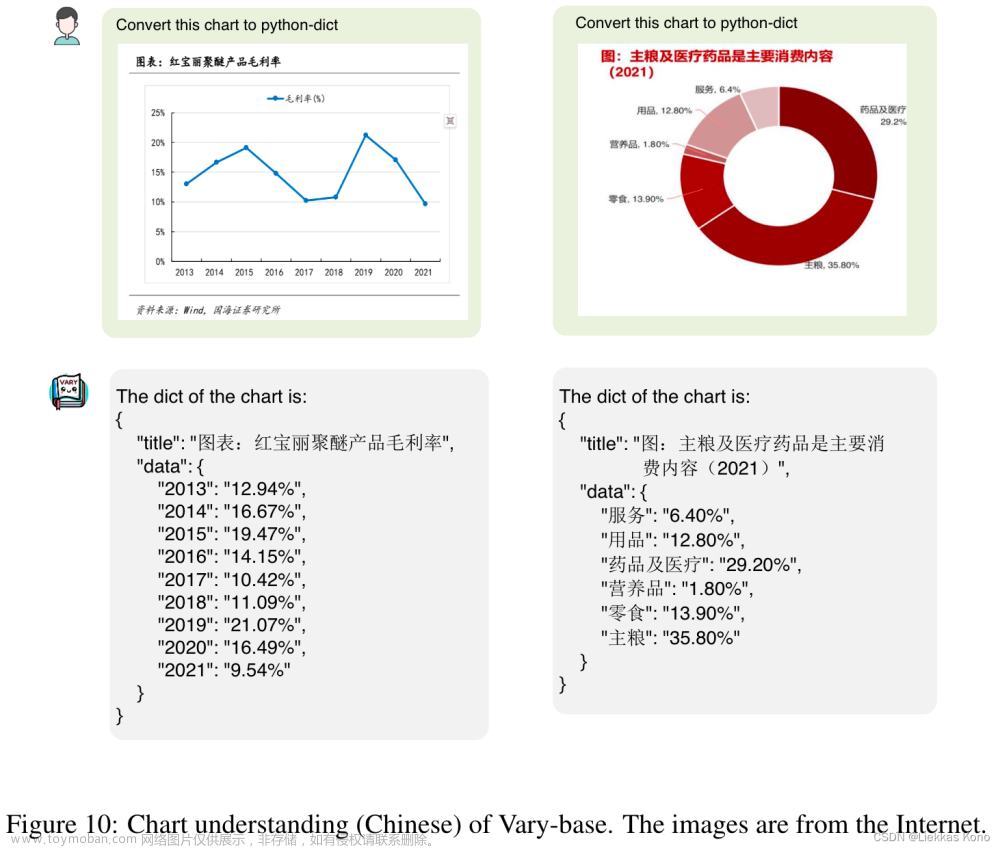
论文中给出了一些图表推理结果样例:
Negative natural image选取
因为CLIP-VIT对于自然图像较为擅长。为了确保新引入的vocabulary不影响已有效果,因此,作者在训练Vary-Tiny时,引入了自然图像作为negative image-text pairs。
作者从COCO数据集中选取了120k图像,其所对应的文本从以下几条中随机选取:
“It’s an image of nature”;
“Here’s a nature picture”;
“It’s a nature photo”;
“This is a natural image”;
“That’s a shot from nature”.
Vary-base部分
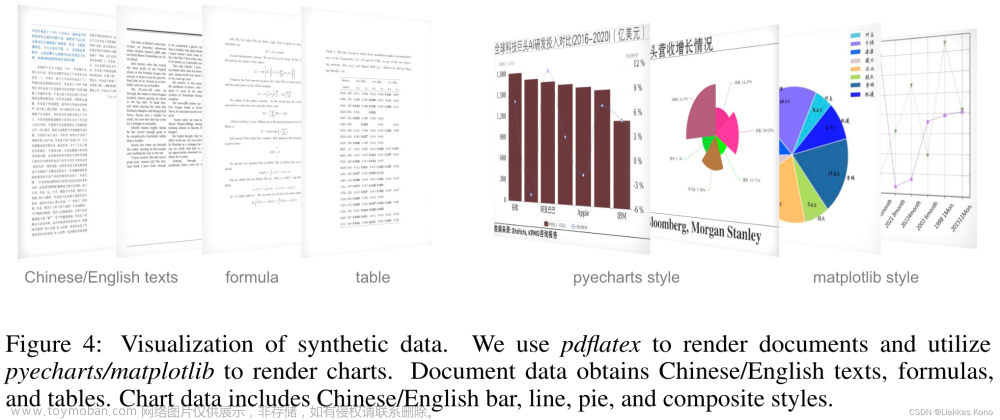
文档数据
上述收集到的文档数据,直接提取的PDF中文本信息。所以数据中更多的是文本数据,表格和公式类型较少。因此在训练Vary-base阶段,作者采用LaTeX来渲染了一批比较有针对性的数据。具体做法如下:
- 收集一些arXiv上tex文件源文件,使用正则提取其中的表格、数学公式和文本内容
- 将以上内容重新用pdflatex工具渲染到新的模板上。作者整理了10+模版。
作者将图像对应的ground truth存储在mmd格式中。mmd格式是一种加强版的md格式,可以直接渲染md中的LaTeX代码编写的表格和公式。
最终,作者收集整理了50w英文数据和40w中文数据。
语义相关的图表数据渲染
在Vary-tiny阶段,作者批量渲染了图表数据来训练Vary-tiny中的vocabulary。但是那些数据存在标题、横纵坐标语义相关性较差的问题。因此,在本阶段,作者使用了GPT-4来产生语义相关性较强的语料来渲染高质量的图表数据。
不得不说,这一步很有借鉴意义的。
General Data
该部分使用的数据分为两部分:
- 预训练阶段:使用的来自LAION-COCO的image-text pair数据
- SFT阶段:使用的LLaVA-80k和LLaVA-CC665k
写在最后
本来还想结合论文源码来进一步查看做法的。一直没有找到合适的表达方法来合理有序地表达代码和论文的关系。暂时搁置。
刚才看Vary源码,发现作者更新了两个新的工作:Vary-toy和 Vary-Family系列,两者关系如下:文章来源:https://www.toymoban.com/news/detail-804655.html
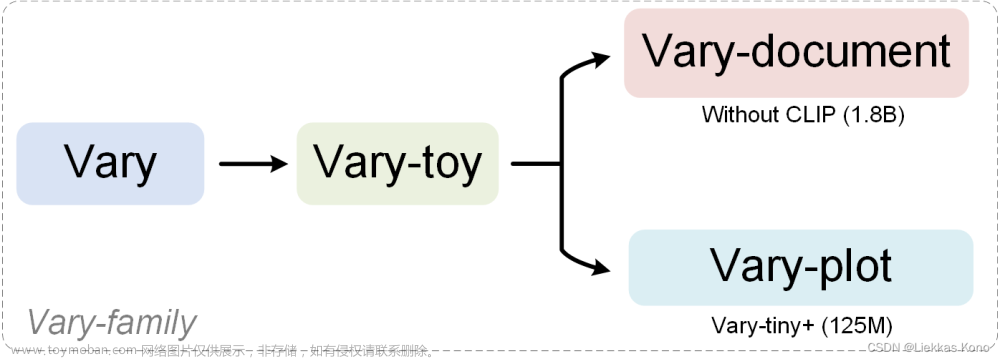
值得期待和学习。文章来源地址https://www.toymoban.com/news/detail-804655.html
到了这里,关于论文阅读:Vary论文阅读笔记的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
![[论文阅读笔记18] DiffusionDet论文笔记与代码解读](https://imgs.yssmx.com/Uploads/2024/01/401181-1.png)