教程地址:tutorial-InternLM/tutorial (github.com)
1 大模型及 InternLM 模型简介
1.1 什么是大模型?
大模型通常指的是机器学习或人工智能领域中参数数量巨大、拥有庞大计算能力和参数规模的模型。这些模型利用大量数据进行训练,并且拥有数十亿甚至数千亿个参数。大模型的出现和发展得益于增长的数据量、计算能力的提升以及算法优化等因素。这些模型在各种任务中展现出惊人的性能,比如自然语言处理、计算机视觉、语音识别等。这种模型通常采用深度神经网络结构,如 Transformer、BERT、GPT( Generative Pre-trained Transformer )等。
大模型的优势在于其能够捕捉和理解数据中更为复杂、抽象的特征和关系。通过大规模参数的学习,它们可以提高在各种任务上的泛化能力,并在未经过大量特定领域数据训练的情况下实现较好的表现。然而,大模型也面临着一些挑战,比如巨大的计算资源需求、高昂的训练成本、对大规模数据的依赖以及模型的可解释性等问题。因此,大模型的应用和发展也需要在性能、成本和道德等多个方面进行权衡和考量。
1.2 InternLM 模型全链条开源
InternLM 是一个开源的轻量级训练框架,旨在支持大模型训练而无需大量的依赖。通过单一的代码库,它支持在拥有数千个 GPU 的大型集群上进行预训练,并在单个 GPU 上进行微调,同时实现了卓越的性能优化。在 1024 个 GPU 上训练时,InternLM 可以实现近 90% 的加速效率。
基于 InternLM 训练框架,上海人工智能实验室已经发布了两个开源的预训练模型:InternLM-7B 和 InternLM-20B。
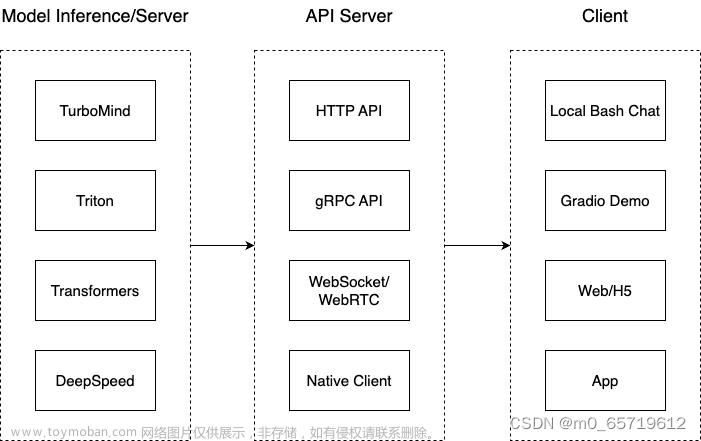
Lagent 是一个轻量级、开源的基于大语言模型的智能体(agent)框架,支持用户快速地将一个大语言模型转变为多种类型的智能体,并提供了一些典型工具为大语言模型赋能。通过 Lagent 框架可以更好的发挥 InternLM 的全部性能。

浦语·灵笔是基于书生·浦语大语言模型研发的视觉-语言大模型,提供出色的图文理解和创作能力,结合了视觉和语言的先进技术,能够实现图像到文本、文本到图像的双向转换。使用浦语·灵笔大模型可以轻松的创作一篇图文推文,也能够轻松识别一张图片中的物体,并生成对应的文本描述。
2 环境配置
2.1 pip、conda 换源
2.1.1 pip 换源
临时使用镜像源安装,如下所示:some-package 为你需要安装的包名
pip install -i https://mirrors.cernet.edu.cn/pypi/web/simple some-package设置pip默认镜像源,升级 pip 到最新的版本 (>=10.0.0) 后进行配置,如下所示:
python -m pip install --upgrade pip
pip config set global.index-url https://mirrors.cernet.edu.cn/pypi/web/simple如果您的 pip 默认源的网络连接较差,临时使用镜像源升级 pip:
python -m pip install -i https://mirrors.cernet.edu.cn/pypi/web/simple --upgrade pip2.1.2 conda 换源
镜像站提供了 Anaconda 仓库与第三方源(conda-forge、msys2、pytorch 等),各系统都可以通过修改用户目录下的 .condarc 文件来使用镜像站。
不同系统下的 .condarc 目录如下:
-
Linux:${HOME}/.condarc -
macOS:${HOME}/.condarc -
Windows:C:\Users\<YourUserName>\.condarc
注意:
-
Windows用户无法直接创建名为.condarc的文件,可先执行conda config --set show_channel_urls yes生成该文件之后再修改。
快速配置
cat <<'EOF' > ~/.condarcchannels:
- defaults
show_channel_urls: true
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
EOF2.2 配置本地端口
由于服务器通常只暴露了用于安全远程登录的 SSH(Secure Shell)端口,如果需要访问服务器上运行的其他服务(如 web 应用)的特定端口,需要一种特殊的设置。我们可以通过使用SSH隧道的方法,将服务器上的这些特定端口映射到本地计算机的端口。这样做的步骤如下:
首先我们需要配置一下本地的 SSH Key ,我们这里以 Windows 为例。
步骤①:在本地机器上打开 Power Shell 终端。在终端中,运行以下命令来生成 SSH 密钥对:(如下图所示)
ssh-keygen -t rsa步骤②: 您将被提示选择密钥文件的保存位置,默认情况下是在 ~/.ssh/ 目录中。按 Enter 键接受默认值或输入自定义路径。
步骤③:公钥默认存储在 ~/.ssh/id_rsa.pub,可以通过系统自带的 cat 工具查看文件内容
步骤④:将公钥复制到剪贴板中,然后回到 InternStudio 控制台,点击配置 SSH Key。
步骤⑤:将刚刚复制的公钥添加进入即可。
步骤⑥:在本地终端输入以下指令 .6006 是在服务器中打开的端口,而 33090 是根据开发机的端口进行更改。如下图所示:
ssh -CNg -L 6006:127.0.0.1:6006 root@ssh.intern-ai.org.cn -p 330903 InternLM-Chat-7B 智能对话 Demo
进入开发机 conda 环境之后,使用以下命令从本地克隆一个已有的 pytorch 2.0.1 的环境
bash # 请每次使用 jupyter lab 打开终端时务必先执行 bash 命令进入 bash 中
/root/share/install_conda_env_internlm_base.sh internlm-demo3.1 终端运行
在 /root/code/InternLM 目录下新建一个 cli_demo.py 文件,将以下代码填入其中:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name_or_path = "/root/model/Shanghai_AI_Laboratory/internlm-chat-7b"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, trust_remote_code=True, torch_dtype=torch.bfloat16, device_map='auto')
model = model.eval()
system_prompt = """You are an AI assistant whose name is InternLM (书生·浦语).
- InternLM (书生·浦语) is a conversational language model that is developed by Shanghai AI Laboratory (上海人工智能实验室). It is designed to be helpful, honest, and harmless.
- InternLM (书生·浦语) can understand and communicate fluently in the language chosen by the user such as English and 中文.
"""
messages = [(system_prompt, '')]
print("=============Welcome to InternLM chatbot, type 'exit' to exit.=============")
while True:
input_text = input("User >>> ")
input_text = input_text.replace(' ', '')
if input_text == "exit":
break
response, history = model.chat(tokenizer, input_text, history=messages)
messages.append((input_text, response))
print(f"robot >>> {response}")在终端运行以下命令,即可体验 InternLM-Chat-7B 模型的对话能力。
python /root/code/InternLM/cli_demo.py3.2 web demo 运行
切换到 VScode 中,运行 /root/code/InternLM 目录下的 web_demo.py 文件,输入以下命令后,查看本教程2.2配置本地端口后,将端口映射到本地。在本地浏览器输入 http://127.0.0.1:6006 即可。文章来源:https://www.toymoban.com/news/detail-804762.html
bash
conda activate internlm-demo # 首次进入 vscode 会默认是 base 环境,所以首先切换环境
cd /root/code/InternLM
streamlit run web_demo.py --server.address 127.0.0.1 --server.port 6006在浏览器打开 http://127.0.0.1:6006 页面后,模型加载,可以与 InternLM-Chat-7B 进行对话。文章来源地址https://www.toymoban.com/news/detail-804762.html
到了这里,关于书生·浦语大模型全链路开源体系【大模型第2课-笔记】的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!