现根据业务需要,需要在原有的3台完全分布式的集群(hadoop1、hadoop2、hadoop3仨节点)增设一台新的服务器节点(hadoop4),以下是在原有的完全分布式hadoop集群中增设新节点(DataNode + NodeManager)的部署步骤。
- 基础服务配置
hadoop4上依次执行以下步骤:
1)用户:重置root用户密码,增加hadoop用户并设置密码
passwd root
useradd hadoop
passwd hadoop
2)网络:设置静态IP
修改BOOTPROTO="static"和ONBOOT="yes"
IPADDR="实际IP"
NETMASK="实际掩网子码"
GATEWAY="实际网关"
DNS1="实际DNS"
3)安全:关闭防火墙、关闭Selinux
systemctl status firewalld.service --查看防火墙状态
systemctl stop firewalld.service --关闭防火墙
systemctl disable firewalld.service --禁止防火墙开机自启动
setenforce 0 --临时关闭Selinux
/etc/selinux/config SELINUX=disabled --永久关闭SeLinux
4)互信:
ssh-keygen -t rsa
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop1
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop2
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop3
5)主机:
临时设置主机名,永久修改主机名,修改hosts文件
hostnamectl set-hostname --static hadoop4
/etc/hostname
四台hadoop主机的hosts文件都需要确保修改成这样:
cat /etc/hosts
10.88.88.56 hadoop1
10.88.88.57 hadoop2
10.88.88.58 hadoop3
10.88.88.63 hadoop4
6)挂载数据盘:
格式化数据盘,整盘挂载
mkfs.xfs /dev/sdb 创建ext4文件系统
mkdir /data 创建数据目录
mount /dev/sdb /data 挂载
chown -R hadoop:hadoop /data 修改权限
修改/etc/fstab,mount -a确认是否挂载成功,df -h查看最新挂载情况
确保所有节点的host文件都已更新。
二、服务部署
1)JDK服务
可利用hadoop1上现有的JDK目录
[hadoop@hadoop1 local] scp -r jdk hadoop@hadoop4:/usr/local/java
[hadoop@hadoop1 local] ssh hadoop@hadoop4
在hadoop4服务器上更新环境变量
# jdk config
export JAVA_HOME=/usr/local/java/jdk
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
以上内容追加到/etc/profile和~/.bashrc文件末尾,并且记得source更新。
使用命令java -version查看JDK版本。
[hadoop@hadoop4 ~]# java -version
java version "1.8.0_301"
Java(TM) SE Runtime Environment (build 1.8.0_301-b09)
Java HotSpot(TM) 64-Bit Server VM (build 25.301-b09, mixed mode)
2)Hadoop服务
可利用hadoop1上现有的hadoop目录
[hadoop@hadoop1 local]scp -r hadoop hadoop@hadoop4:/usr/local/hadoop
[hadoop@hadoop1 local]ssh hadoop@hadoop4
在hadoop4服务器上更新环境变量
# hadoop config
export HADOOP_HOME=/usr/local/hadoop/hadoop-3.3.1
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
以上内容追加到/etc/profile和~/.bashrc文件末尾,并且记得source更新。
使用命令hadoop version查看JDK版本。
[hadoop@hadoop4 ~]# hadoop version
Hadoop 3.3.1
Source code repository https://github.com/apache/hadoop.git -r a3b9c37a397ad4188041dd80621bdeefc46885f2
Compiled by ubuntu on 2021-06-15T05:13Z
Compiled with protoc 3.7.1
From source with checksum 88a4ddb2299aca054416d6b7f81ca55
This command was run using /usr/local/hadoop/hadoop-3.3.1/share/hadoop/common/hadoop-common-3.3.1.jarJava HotSpot(TM) 64-Bit Server VM (build 25.301-b09, mixed mode)
三、测试验证
- 在要上线的节点上启动datanode
[hadoop@hadoop4 sbin] ./hadoop-daemon.sh start datanode
数据均衡需使用以下命令
[hadoop@hadoop4 sbin] start-balancer.sh -threshold 2
执行这行命令以后,如果某个节点的数据块数量超过了其他任何节点的数据块数量超过 2 个,那么平衡器将启动并重新分配数据块,以使得各个节点的数据块数量尽可能接近。
- 需要启动nodemanager,则执行
[hadoop@hadoop4 sbin] ./yarn-daemon.sh start nodemanager
然后在hadoop4上查看Jps进程。
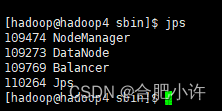
同时具备这两个进程,表明新节点已经同步和增加完毕了,集群新增服务器节点增设完毕!
[hadoop@hadoop4 sbin] hadoop dfsadmin -report
此命令获取 Hadoop 分布式文件系统(HDFS)的状态报告。该命令将在终端上输出有关 HDFS 集群的详细信息,包括节点的名称、状态、容量、数据块数量等。通过该命令,用户可以了解 HDFS 集群的整体状态,以便进行故障排除和性能优化等操作。
输出的状态报告包括以下主要部分:
集群 ID 和名称:HDFS 集群的 ID 和名称。
节点信息:HDFS 集群中所有节点的详细信息,包括节点名称、节点类型、节点状态、数据块数量、磁盘使用情况等。
数据块复制情况:HDFS 集群中每个数据块的复制情况,包括数据块 ID、复制数量、存储位置等。
文件系统总体情况:HDFS 集群中整个文件系统的情况,包括总容量、已使用容量、剩余容量等。


查看HDFS集群总容量从2.88T扩容到3.55T。
查看YARN集群节点从3个扩容到4个,资源总量从memory 48GB vCores 24个扩容到memory 64GB vCores 32个。


hadoop4已经充当计算节点,跑任务了。
其他:数据均衡相关记录

数据均衡期间会极大消耗网络资源(需在非业务高峰期执行)

数据均衡期间也会极大消耗服务器内存资源(需在非业务高峰期执行)

120G数据平衡花了1个小时,生产环境数据平衡时需要注意时间点。
数据平衡结束后,各节点的hdfs数据目录容量不变,内存消耗降下来,但是还有很多在buff/cache里,需要执行以下命令手动释放缓存:
[root@hadoop2 ~]# sync && echo 3 > /proc/sys/vm/drop_caches文章来源:https://www.toymoban.com/news/detail-805553.html
[root@hadoop2 ~]# free -g文章来源地址https://www.toymoban.com/news/detail-805553.html
到了这里,关于hadoop集群中增加新节点服务器(DataNode + NodeManager)方案及验证的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!