背景
Stable Diffusion是计算机图形学和可视化领域中的一项重要技术。在这篇分 享中 ,我们将深入探讨稳定扩散的原理、关键要素和实施步骤 ,通过了解Stable Diffusion的流程化 ,我们可以提升自身的设计能力和创造力 ,为公司 和个人注入更多的价值和创意。
美术制定
美术风格的制定主要用于生成图像 ,而美术图片风格制定是指在生成图像时设定特定的风格或艺术效果。
1.数据集选择:选择与目标风格相符的图像数据集作为训练数据。例如 ,如 果希望生成具有卡通风格的图像 ,可以选择包含卡通图像的数据集进行训练。
2.数据预处理:在训练之前 ,可以对训练数据进行预处理来增强特定风格的特征 ,可以调整对比度和亮度和打标等操作来调整定义图像的风格。
3.损失函数设计:在损失函数中引入与目标风格相关的项 ,以促使生成图像 与目标风格更加接近。一种常见的方法是使用风格损失函数 ,它通过比较生成图像与目标风格图像之间的特征表示来度量它们之间的风格差异。
4.模型架构选择:选择适合目标风格生成的模型架构。不同的模型架构可能 对特定风格的生成效果有所差异。您可以尝试使用已经在特定风格生成方面表现良好的模型架构或根据需求进行调整。
5.参数调整:根据需要 ,调整训练过程中的超参数 ,如学习率、批次大小等。这可以帮助优化模型的收敛性和生成图像的质量。
美术图片风格制定是一个主观的过程 ,取决于个人的审美偏好和目标风格的定义。 因此 ,具体的风格制定方法可能因任务和需求而有所不同。在实际应用中 ,您可能需要进行多次实验和调整 ,以获得满意的风格生成效果。
模型制定
LORA模型和CKPT模型主要用于数据分析、模式识别、预测和决策等任务 ,可以使用深度学习模型(如ckpt模型)进行图像识别和图像生成 ,从而 实现更加逼真和艺术化的图形效果。这些模型可以学习并提取图像中的特征 ,进而生成具有艺术风格的图像或实现图像的增强和修复 ,模型训练我主
要使用的是Kohya
1.数据集准备:首先 ,需要准备一个用于训练的图像数据集。这可以是任何类型的图像数据集 ,如人脸、 自然景观等。
2.噪声图像生成:使用随机噪声生成器创建一个与训练数据集相同大小的噪声图像作为初始输入。
3.扩散和逆扩散操作:通过迭代地应用扩散和逆扩散操作 ,逐步改善噪声图 像 ,使其逼近真实图像。扩散操作可以是卷积、高斯模糊等线性操作 ,逆扩散操作可以是反卷积、锐化等线性操作。
4.损失函数定义:定义一个适当的损失函数来度量生成图像与真实图像之间 的差异。常见的损失函数包括均方误差(MSE)和感知损失(如VGG损失) ,用于促使生成图像与真实图像在像素级别或感知级别上相似。
5.训练过程:使用生成图像和真实图像之间的差异作为损失函数 ,通过反向 传播算法优化模型参数。您可以使用梯度下降算法或其他优化算法来最小化损失函数。
6.训练迭代:重复执行训练过程 ,多次迭代更新模型参数 ,直到生成的图像达到所需的质量水平或训练收敛。
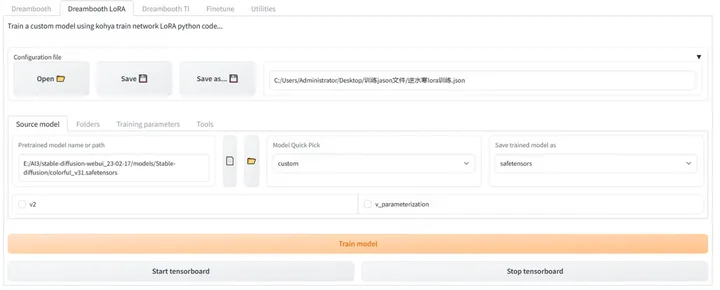
Kohya功能介绍
Github地址 :https://github.com/bmaltais/kohya_ss
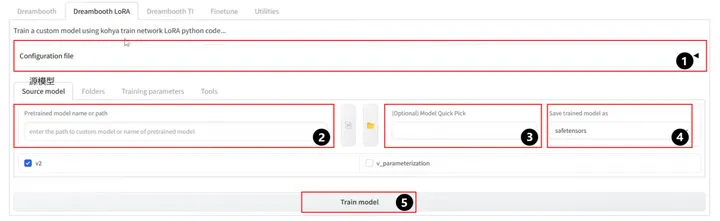
1.Configuration file:配置文件夹 ,用来载入默认配置 ,如果之前保存过预设 ,那可以快速载入。
2.Pretrained model name or path:基础训练模型名称或路径 ,一般填写路 径。基于训练的不同风格的LoRA,应当选择相匹配合适的基础模型。
3.Model Quick Pick(可选):关于一些基础模型的预设快速加载 ,不同基 础模型决定是否勾选v2和v_parameterization ,假如基础模型是基于Stable Diffusion-v1.5训练的 ,v2和v_parameterization不需要勾选。
4. Save trained model as:模型储存格式 ,推荐使用Safetensors格式。
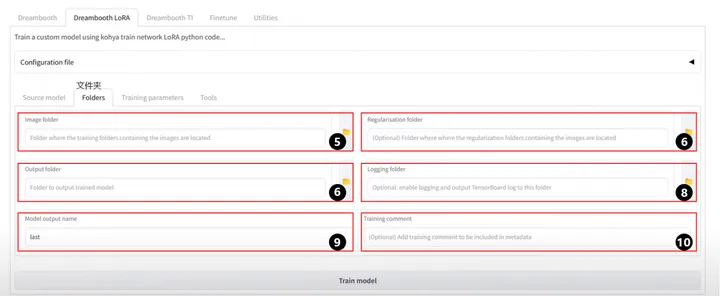
5.Image folder:提供训练素材的文件夹的上级目录 ,文件夹注意命名规则 最好以数字开头, 中间下划线 ,最终是名称的形式 ,数字是对图像重复的次数 ,例如30_XXX模型名称。
6.Regularisation folder:正则化文件夹 ,可以忽略。
7.Output folder:模型输出目录 ,用来保存训练好的模型路径。
8. Logging folder: 日志保存目录 ,需要在该目录中新建一个log.txt的文件, 可以用来观测模型训练数据。
9. Model output name:模型输出的名称。
10. Training comment:训练注释 ,一般不需要。

11.LoRA network weights:如果想在现有LoRA模型的基础上进行训练 ,可以选择他所在的文件夹。
12.Train batch size:批处理数量 ,一次读取的图像数量 ,数值越大 ,训练 速度越快 ,消耗的显存越高, 同时学习率也应该相应提高。
13.Epoch:循环次数 ,循环次数越大越好 ,但是过大容易过拟合 ,过拟合就是指训练的模型与素材图像过于相似 ,对于LoRA ,2-3次的学习就足够了。
14.Save every N epochs:按循环次数保存模型 ,即每循环一定次数 ,保存一次模型。例如共循环10次 ,该处设置为2 ,就会产生5个模型。
15.Caption Extension:默认.txt。
16.Mixed pecsion:混合精度 ,指定训练期间数据的混合精度类型 ,选择no 时 ,最初精度为32位, 16位的精度可以节省内存和加快速度 ,fp16可以获得足够高精度的LoRA。
17.Save precision:保存精度 ,与混合精度保持一致。
18.Number of CPU threads per core:每核CPU线程数 ,线程数越高 ,效率 越高。这取决你自身硬件。
19.Seed :随机种子 ,默认为空白 ,训练时尽量指定Seed ,相同的Seed能 尽可能再现结果。
20:Learning rate:学习率 ,学习率对模型训练的影响很大 ,在未设置 unet 学习率 和text_encoder 学习率时生效 ,默认可以选择1e-4。
21.LR Scheduler:学习率调度器。推荐使用constant\cosine_with_restarts ,。
22.LR warmup (% of steps):预热调度程序的步数,默认可以选择0。
23.Cache latent:缓存潜变量 ,通常开启 ,节省显存空间提高速度 ,开启该 项后Color augmentation/Flip augmentation/Random crop 将不可用。
24.Text Encoder learning rate:常取定值5e-5 ,也有许多人将他调成unet_lr 的 10-15分之一 ,调整到 unet_lr 1/8 附近也是常见的做法。调低该 参数有助于更多学习文本编码器。
25.Unet learning rate:默认值是1e-4 ,你也可以写 0.0001。使用不同学习 率时有所调整 ,当你的 network_dimension较大时 ,需要更多的 steps 与更 低的学习率。
26.Network Rank (Dimension):特征维度 ,维度提升有助于学会细节但是 模型的收敛速度变慢 ,更容易导致过拟合高分辨率通常需要更高的维度,推荐值为128。
27.Network Alpha: 推荐值为network_dimension 的一半 ,防止下溢并稳定 学习。
28.Max resolution:训练图像的最大分辨率 ,如果训练图像超过这个指定分辨率 ,就会按比例缩小到这个分辨率内 ,默认为512*512。
29.Stop text encoder training:停止学习文本编码器 ,在一个时间点适度停 止文本编码器学习是预防过拟合的一种方式。这里的数字表示到达训练步数 的百分比 ,一旦学习达到该百分比就会停止学习。如果是0则训练结束才会停止。
30.Enable buckets:是否开启容器。 由于同大小的图像不能同时训练, 因此 需要提前把相似大小的图像进行分类 ,默认为开启。
31.No token padding:附在图像上的文本每75个token就会被处理一次 ,假 设文本数量不足75就会自动填充到75个 ,这个过程叫填充。默认设置是关闭的。
32.Gradient accumulate steps:梯度累积步数 ,每次学习的读取的图像批 数 ,例如当该值为2时 ,批处理大小为4时 ,学习一次共会读取8张图像。
33.Prior loss weight:先验损失权重值。该值决定了训练过程对“正则化图 像”的重视程度 ,如果该值较低 ,对正则化图像的重视程度越低 ,会产生更具训练图像特征的LoRA ,默认值推荐为1。
34.Full fp16 training (experimental) :当打开此选项时 ,所有权重数据都是 fp16格式 ,他会覆盖混合精度中的设置 ,尽管打开这个选项会节约内存 ,但数据精度和学习率都会下降。默认推荐关闭。
35.Gradient checkpointing:梯度检查点。该选项指定权重计算应该逐渐增 加得完成 ,有助于节省内存。但该选项与训练LoRA无关 ,默认关闭。
36.Shuffle caption:文本洗牌。当训练图像的文字说明是用逗号隔开的形式 ,则该选项可以每次都改变单词的顺序 ,有助于修正偏差 ,但如果文字说明是以句子的形式 ,该选项就没有意义 ,默认为关闭。
37.Keep n tokens:当训练图像的文字说明是用逗号隔开的形式 ,可以将训练图像中的指定文字始终
38.Use 8bit adam:
39.Use xformers:使用名为“xformers”的Python库 ,牺牲速度来换取更少的显存使用 ,如果没有足够的显存可以打开他 ,默认为打开。
40.Color augmentation:彩色增强。当该选项开启 ,图像的色相每次会发生 随机变化 ,从中学习到的LoRA在色相上会有轻微的范围变化。如果Cache latents(缓存潜变量)开启 ,则该选项不起作用 ,默认为关闭。
41.Flip augmentation:翻转增强。当该选项开启 ,图像会随机翻转 ,可以学习左右角度 ,这对学习对称的人和物体时很有帮助 ,默认关闭。
42.Clip skip:文本编码器跳过某些层的输出 ,例如选择“2”则使用倒数第二层进行输出 ,通常三次元选择1 ,二次元选择2 ,并且一些特定的模型有指定的要求 ,如SD2.0则默认使用倒数第二层。
43.Memory efficient attention:勾选该选项 ,会抑制显存使用并执行注意力 块处理, 同样是牺牲速度来换取更少的显存使用 ,速度比Use xformers更慢一些。
44.Max Token Length:最大Token长度。指定训练图像文本的token数量, 一般情况文本中的token数不容易超过75 ,但如果文本过长 ,可以通过指定该值来解决。
45.Save training state:保存训练状态。如果训练时间过长 ,启用该选项,可以在中间中断学习 ,并且在之后可以从停止的位置继续学习, 中间的学习数据保存在最后状态的文件夹中。
46.Resume from saved training state:从保存训练状态恢复 ,如果想恢复 已经中断的学习 ,可以指定“最后状态”的文件位置 ,从而继续学习。
47.Max train epoch:指定最大循环次数。当达到指定的循环次数 ,学习结束 ,默认是不用填写。
48.Max num workers for DataLoader: DataLoader的最大工作线程 ,此选 项会指定训练CPU的进程数 ,增加该数值会启用CPU的子进程并提高读取速 度 ,但指定太多进程会导致效率下降 ,无论指定数目多大 ,它不会超过CPU并发执行线程数目。
功能介绍到这里就结束了 ,相信大家对Kohya有了一个基本的认识 ,下面我将用实操来演示一个基本的LORA是怎么制作的。
这是我的数据调配

实例介绍:
古风角色
- 项目美术需求:包括角色衣服剪裁样式、衣服质感、细节刻画等要求, 同时他们也会提供训练模型的初筛素材。
2. 素材处理:训练模型前, 同时我们也要对素材进行处理从而保证模型的精度。主要包括以下两个部分。
A. 图片格式上, png格式的图片需要将透明的部分填充颜色 ,否则训练可能 会出错。
B. 图片内容上 ,人物与背景尽量分离 ,可以通过手动填充背景 ,或者调整对 比度、亮度等方式实现 ,并且姿势尽量一致。衣物裁切样式上 ,需要剔除那些层次模糊的素材。
3. 模型验证:该步骤也是提交给项目前必要重要的步骤 ,分别通过文生图和 图生图两个方面进行。首先是文生图其目是提供衣服裁切样式的设计 ,配合 训练的大模型一起使用 ,主要检查模型是否过拟合 ,直观的方式就是一次生 成多张图片 ,观察衣服的裁切样式、配色、质感等是否多样。 图生图的目的 主要是进行人物的细化包括例如金属质感、布料质感的细化以及光影的塑
造。

4. 项目使用:通过提供人物的轮廓和色块关系 ,然后利用AI提高完成度 ,但 是AI参与的过程还是需要挑选其中的图进行手动拼贴修改 ,并对整体修改细
节的合理度和美观程度。以角色发型设计三视图为例。

宠物多样性
- 项目素材整理:首先对提供的素材进行分类 ,可以按照形态、材质等进行分类 ,例如按照宠物形态分为二足、 四蹄、三角、福瑞等
- 素材处理和模型验证思路与上述流程基本一致 ,不同分类的模型文生图结果如下。
3.项目使用 :图生图用于细节绘制。

场景单体建筑
单体建筑的AI绘图尝试了两种方式 ,分别如下。
方式一:AI绘图+PS修改
- 概念探索:利用midjourney生成大量建筑的草图 ,将草图收集整理并由 项目组筛选。
2. 模型训练与验证:确定训练集后 ,利用草稿图进行图生图来模型验证 ,验证结果如下。
3. 项目使用: 模型确认可行后, 项目可以结合Control net中的Canny和 Depth来解决AI生成不按设计的问题。接着通过图生图(迭代) 和文生图 (多样性) 对图像进行优化 ,主要针对周边环境、画面风格等方面进行调 整 ,最后从AI结果中选取合适的图像利用Photoshop进行修改完成。
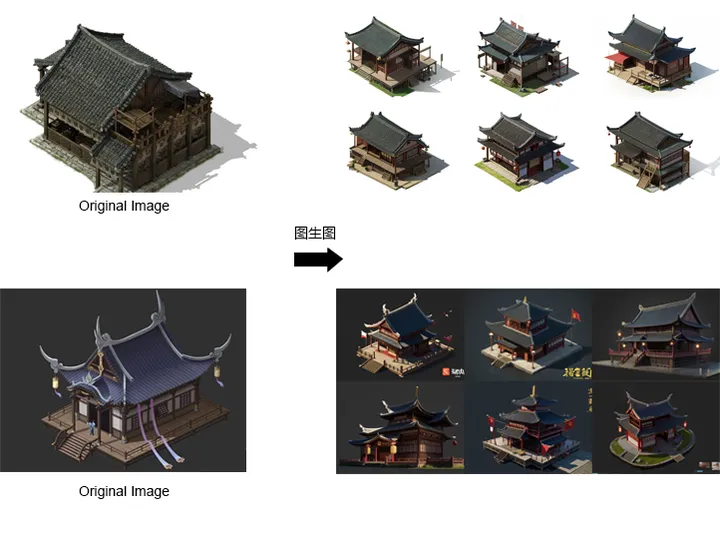
方式二:3D辅助+AI绘图+PS修改 ,AI参与基本过程如下
1.3D辅助:搭建场景单体建筑的简模 ,确定建筑形体的基本框架和设计 ,与 control net配合使用 ,防止生成图像脱离原本的设计。
2.素材整理与模型验证流程与上述基本一致。
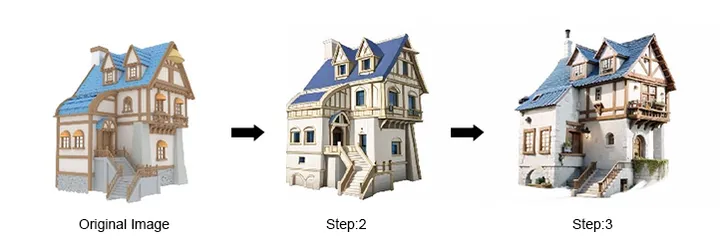
3.项目使用 :首先对整张图进行图生图确定一个大致的建筑风格 ,接着对局 部不满意的地方进行裁切, 图生图迭代直到获得满意的效果 ,最终将各个部分位置进行拼接 ,补充和修改细节完成成图。

场景氛围:用于氛围细节细化和风格迁移。
1.素材整理和模型训练:示例截取了一些游戏场景的图像作为训练集并进行模型训练。

2.项目使用:
A.氛围细节细化。如图所示 ,使用3D辅助的方式搭建场景白模的构图和前后 关系 ,利用control net中的Canny和Depth限定图像的结构关系。通过不断 调整提示词和LoRA的权重来实现图像的迭代。

B.场景氛围风格迁移。 同样是限制画面的构图前提下 ,增加reference only 的方式以及修改提示词 ,来改变场景氛围 ,不限于时间、季节、风格等。

UI流程
概述: UI制作中 ,AI参与的更多是单一对象的图标制作 ,例如装备、药品、头像、技能,
1. 素材收集:项目组提供UI素材, 同时我们会寻找贴近项目风格的大模型来进行训练。
2. 模型训练与模型验证思路与上述基本一致。
3. 项目使用 :具体使用过程中用到的更多的是图生图的功能 ,用来进行细 化 ,保持原本UI设计的同时提高工作效率, 以下分别是进行各类图标的尝试。

刺绣法线流程
1. 素材整理:利用midjourney生产大量关于刺绣的美术资源。生产获得的 资源可以直接使用或者收集获取的素材训练LoRA使用。
2. 图像放大:直接由midjourney生产的图存在分辨率不足的问题 ,使用 Stable diffusion图生图的Tiled Diffusion和Tiled Vae对图像进行放大。 3. 法线生成:使用PhotoShop的转法线功能 ,生成刺绣的法线图。

打飞机小游戏(概念验证)
概述:整个游戏的美术素材,包括飞机、场景均由AI生成。
1. 素材收集 :使用midjourney生成大量美术资源 ,用作飞机模型和背景模 型训练集。
2. 模型训练与验证:检查文生图下 ,能否稳定生产出多样的飞机俯视图和场景背景。
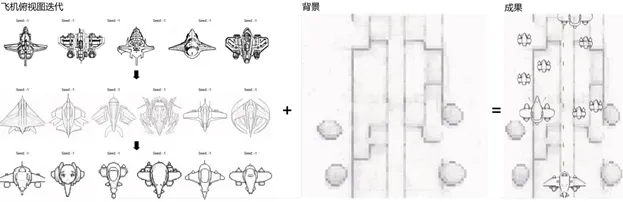
3. 风格转换 :组合调用线框和像素化的LoRA权重 ,获取理想的风格效果 , 飞机俯视图迭代效果如下 ,确定了风格后 ,将参数同样应用于场景背景即可。
欢迎加入我们!文章来源:https://www.toymoban.com/news/detail-805567.html
感兴趣的同学可以投递简历至: CYouEngine@cyou-inc.com文章来源地址https://www.toymoban.com/news/detail-805567.html
到了这里,关于人工智能实战:Stable Diffusion技术分享的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!