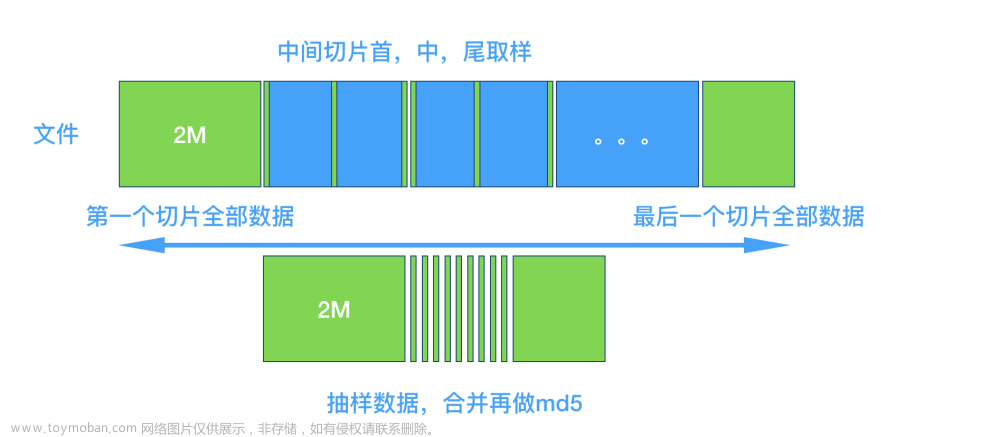
异步切片下载二进制文件并上传桶删除本地文件文章来源:https://www.toymoban.com/news/detail-805597.html
import json
import os
import asyncio
from urllib import parse
import aiohttp
import aioredis
from motor.motor_asyncio import AsyncIOMotorClient
from retrying import retry
from minio import Minio
from minio.error import S3Error
import loguru
class Async_download:
def __init__(self, sema_number=20, redis_address='redis://ip:6379/db', redis_password='passwd'):
self.__sema_number = sema_number
self.__sema = None
self.redis_address = redis_address
self.redis_password = redis_password
self.minio_config = {
"endpoint": "ip:port",
"access_key": "******",
"secret_key": "******",
"secure": False
}
self.mongo_config = {
"uri": "mongodb://{0}:{1}@ip:27017".format(parse.quote_plus("user"),
parse.quote_plus("passwd")),
"db": "******",
"collection": "******",
}
@classmethod
def _mkdir(cls, file_path, full_path):
if os.path.exists(file_path):
return True
try:
os.makedirs(full_path)
except Exception as e:
pass
return False
def __init_check(self, file_path: str):
full_path, file_name = file_path.rsplit('/', 1)
file_size = os.path.getsize(file_path) if self._mkdir(file_path, full_path) else 0
return file_name, file_size
@classmethod
def __sync_save_local(cls, r_headers, results, file_path):
done, padding = results
for d in done:
for index, value in d.result().items():
r_headers[index] = value
with open(file_path, 'ab') as f:
for _, value in r_headers.items():
f.write(value)
return True
@classmethod
def __generate_headers(cls, headers, file_size, first_byte):
r_headers = {}
index = 0
if first_byte > 51200000:
byte = 2048000 # 2M 为一片
else:
byte = 1024000 # 1M 为一片
while True:
file_size_two = file_size + byte
if file_size_two >= first_byte:
r_headers[index] = {"Range": f"bytes={file_size}-{first_byte}"}
break
r_headers[index] = {"Range": f"bytes={file_size}-{file_size_two - 1}"}
index += 1
file_size = file_size_two
for key in r_headers:
r_headers[key].update(headers)
return r_headers
@retry(stop_max_attempt_number=3)
async def __download_one(self, session, method, url, r_headers, **kwargs):
index, headers = r_headers
async with self.__sema:
async with session.request(method, url, headers=headers, **kwargs) as response:
binary = await response.content.read()
return {index: binary}
async def __async_section_download(self, session, method, url, r_headers, **kwargs):
tasks = [
asyncio.create_task(self.__download_one(session, method, url, (key, r_headers[key]), **kwargs)) for key in
r_headers
]
return await asyncio.wait(tasks)
@classmethod
async def __get_content_length(cls, session, method, url, headers, **kwargs):
async with session.request(method, url, headers=headers, **kwargs) as response:
return response.headers.get('Content-Length') or response.headers.get('content-length') or 0
@classmethod
async def __sync_download(cls, session, method, url, headers, file_path, **kwargs):
async with session.request(method, url, headers=headers, **kwargs) as response:
with open(file_path, 'wb') as f:
binary = await response.content.read()
f.write(binary)
async def __async_download_main(self, method, url, headers, file_path, **kwargs):
file_name, file_size = self.__init_check(file_path)
self.__sema = asyncio.Semaphore(self.__sema_number)
async with aiohttp.ClientSession() as session:
content_length = await self.__get_content_length(session, method, url, headers, **kwargs)
if content_length and content_length.isdigit():
content_length = int(content_length)
if file_size >= content_length:
await self.__upload_to_minio(file_path, file_name) # Upload to MinIO
await self.__update_mongo_status(file_name, True) # Update MongoDB status
os.remove(file_path) # Delete local file
return True, file_path
r_headers = self.__generate_headers(headers, file_size, content_length)
results = await self.__async_section_download(session, method, url, r_headers, **kwargs)
self.__sync_save_local(r_headers, results, file_path)
else:
await self.__sync_download(session, method, url, headers, file_path, **kwargs)
if os.path.getsize(file_path) >= int(content_length):
await self.__upload_to_minio(file_path, file_name) # Upload to MinIO
await self.__update_mongo_status(file_name, True) # Update MongoDB status
os.remove(file_path) # Delete local file
return True, file_path
return False, file_path
async def __get_task_from_redis(self):
async with aioredis.from_url(self.redis_address, password=self.redis_password) as redis:
task = await redis.lpop('file_file_all')
return task
async def __process_redis_tasks(self):
while True:
task_info = await self.__get_task_from_redis()
if task_info is None:
break
task = json.loads(task_info)
try:
method = 'get'
url = task["file_link"]
file_path = './{}'.format(task["file_name"])
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.93 Safari/537.36'}
if url.startswith('http') or url.startswith('https'):
try:
ddd = url.split('http')
if len(ddd) != 0:
url = 'http' + ddd[-1]
except:
continue
# Perform download for the current task
await self.__async_download_main(method, url, headers, file_path)
except Exception as e:
loguru.logger.error("Error processing Redis task:", e)
async def __upload_to_minio(self, file_path, object_name):
"""
上传minio
"""
try:
minioClient = Minio(**self.minio_config)
check_bucket = minioClient.bucket_exists("******")
if not check_bucket:
minioClient.make_bucket("******")
loguru.logger.info("start upload file to MinIO")
minioClient.fput_object(bucket_name="******", object_name=object_name, file_path=file_path)
loguru.logger.info("file {0} is successfully uploaded to MinIO".format(object_name))
except FileNotFoundError as err:
loguru.logger.info('*' * 10)
loguru.logger.error('MinIO upload failed: ' + str(err))
except S3Error as err:
loguru.logger.error("MinIO upload failed:", err)
async def __update_mongo_status(self, file_name, status):
"""
更新mongo采集状态
"""
try:
mongo_uri = self.mongo_config["uri"]
db_name = self.mongo_config["db"]
collection_name = self.mongo_config["collection"]
client = AsyncIOMotorClient(mongo_uri)
db = client.get_database(db_name)
collection = db.get_collection(collection_name)
await collection.update_one({"file_name": file_name}, {"$set": {"status": status}})
except Exception as e:
loguru.logger.error("MongoDB update failed:", e)
async def start(self):
await self.__process_redis_tasks()
loguru.logger.add("download_file_output.log", rotation="500 MB", level="DEBUG")
if __name__ == '__main__':
as_dw = Async_download(20)
asyncio.run(as_dw.start())
部分代码来源于y小白的笔记文章来源地址https://www.toymoban.com/news/detail-805597.html
到了这里,关于python异步切片下载文件(内置redis获取任务 mongo更新任务状态等)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!